常见分布式锁4:zookeeper 瞬时znode节点 + watcher监听机制

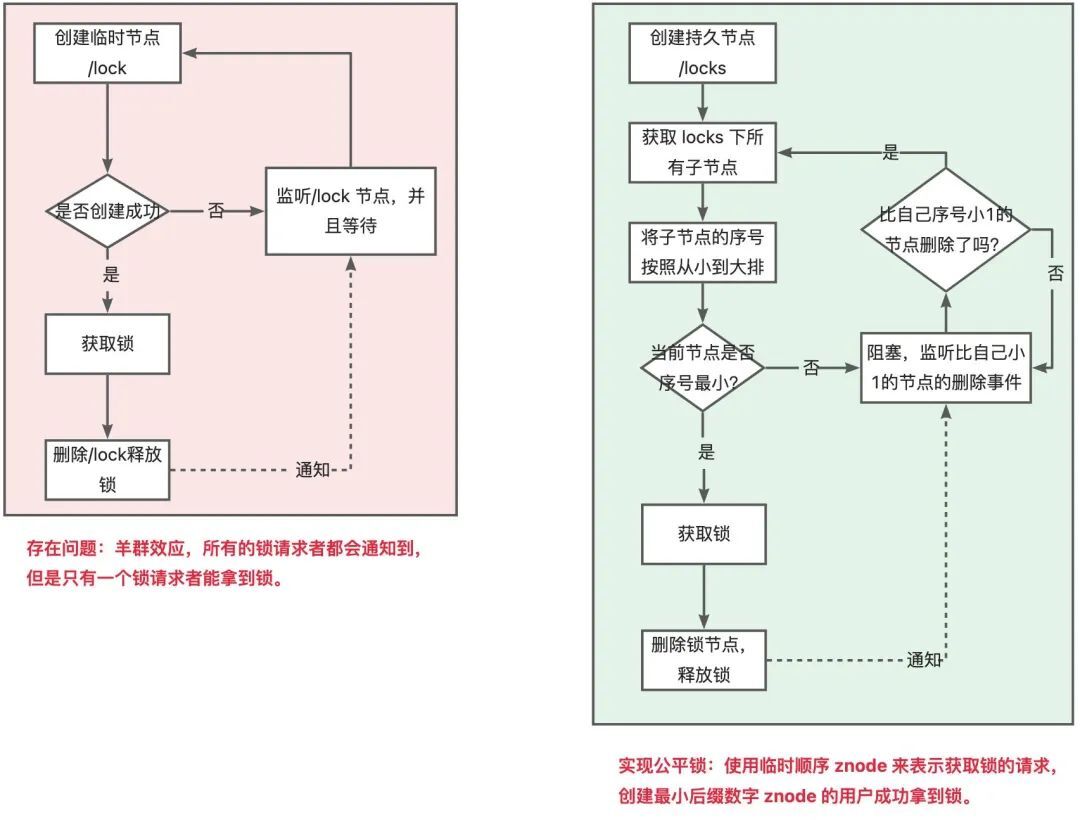
临时节点具备数据自动删除的功能。当client与ZooKeeper连接和session断掉时,相应的临时节点就会被删除。zk有瞬时和持久节点,瞬时节点不可以有子节点。会话结束之后瞬时节点就会消失,基于zk的瞬时有序节点实现分布式锁:
多线程并发创建瞬时节点的时候,得到有序的序列,序号最小的线程可以获得锁;
其他的线程监听自己序号的前一个序号。前一个线程执行结束之后删除自己序号的节点;
下一个序号的线程得到通知,继续执行;
以此类推,创建节点的时候,就确认了线程执行的顺序。
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.14</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions>
</dependency>zk 的观察器只可以监控一次,数据发生变化之后可以发送给客户端,之后需要再次设置监控。exists、create、getChildren三个方法都可以添加watcher ,也就是在调用方法的时候传递true就是添加监听。注意这里Lock 实现了Watcher和AutoCloseable:
当前线程创建的节点是第一个节点就获得锁,否则就监听自己的前一个节点的事件:
/* 自己本身就是一个 watcher,可以得到通知* AutoCloseable 实现自动关闭,资源不使用的时候*/
@Slf4j
public class ZkLock implements AutoCloseable, Watcher {
private ZooKeeper zooKeeper;
/* 记录当前锁的名字*/private String znode;
public ZkLock() throws IOException {this.zooKeeper = new ZooKeeper("localhost:2181",10000,this);}
public boolean getLock(String businessCode) {try {//创建业务 根节点Stat stat = zooKeeper.exists("/" + businessCode, false);if (stat==null){zooKeeper.create("/" + businessCode,businessCode.getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);}
//创建瞬时有序节点 /order/order_00000001znode = zooKeeper.create("/" + businessCode + "/" + businessCode + "_", businessCode.getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);
//获取业务节点下 所有的子节点List<String> childrenNodes = zooKeeper.getChildren("/" + businessCode, false);//获取序号最小的(第一个)子节点Collections.sort(childrenNodes);String firstNode = childrenNodes.get(0);//如果创建的节点是第一个子节点,则获得锁if (znode.endsWith(firstNode)){return true;}//如果不是第一个子节点,则监听前一个节点String lastNode = firstNode;for (String node:childrenNodes){if (znode.endsWith(node)){zooKeeper.exists("/"+businessCode+"/"+lastNode,true);break;}else {lastNode = node;}}synchronized (this){wait();}return true;} catch (Exception e) {e.printStackTrace();}return false;}
@Overridepublic void close() throws Exception {zooKeeper.delete(znode,-1);zooKeeper.close();log.info("我已经释放了锁!");}
@Overridepublic void process(WatchedEvent event) {if (event.getType() == Event.EventType.NodeDeleted){synchronized (this){notify();}}}
}这段代码实现了一个基于 ZooKeeper 的分布式锁,以下是它的实现步骤:
-
首先创建 ZooKeeper 客户端,并实现 Watcher 接口,在自身上注册监听器。
-
在 ZooKeeper 上创建一个业务根节点,例如 /businessCode,表示该业务下所有的分布式锁。
-
使用 ZooKeeper 的临时有序节点创建子节点,例如 /businessCode/businessCode_00001,表示当前节点占用了分布式锁,并记录在 znode 中。
-
获取业务节点下所有的子节点,并按节点名称排序。如果当前节点的名称是所有子节点中最小的,则获取分布式锁。
-
如果当前节点不是所有子节点中最小的,则监听前一个子节点的删除事件,等待前一个子节点释放锁。
-
当前一个子节点被删除时,重新执行第四步,即再次检查当前节点是否为所有子节点中最小的。
-
如果当前节点成功获取到锁,则执行业务操作;否则等待锁释放,重新获取锁。
-
业务操作完成后,执行 close() 方法释放锁,删除当前节点。
总体来说,这段代码实现了一种基本的分布式锁机制,通过 ZooKeeper 的临时有序节点和 Watcher 监听机制来实现。需要注意的是,此实现方式还可能存在死锁问题,当持有锁的节点出现网络故障或宕机时,会导致整个分布式锁失效。因此,在实际应用中,还需要综合考虑各种异常情况,确保分布式锁的正确性和高可用性。