稳定性治理一,重新认识系统

目录
-
稳定性分析(单点,容量和性能,依赖,数据保护,安全,资损,弹性能力,业务连续性,变更控制)
-
压测方案(引流,单点压测,全链路压测)
-
线上问题分析与排查思路
-
大厂稳定性设计系统实现案例
SLA
SLA即服务级别协议(Service Level Agreement),是一份服务提供商和客户之间达成的协议,规定了服务提供商必须提供的服务质量、服务水平、服务保证及赔偿方式等方面的内容。
它是一种合同,用于明确双方之间的责任和义务,以确保服务的稳定性和可靠性。SLA IT 的衡量标准通常包括以下几个方面:
-
可用性:表示系统或服务能够正常运行的时间百分比。通常以年度或月度为单位进行度量。
-
响应时间:表示系统或服务对请求作出响应的时间。通常分为几个级别,如高级别、中级别和低级别,每个级别对应不同的响应时间标准。
-
容量:表示系统或服务最大的处理能力。通常以每秒处理请求数量为单位进行度量。
-
安全性:表示系统或服务提供的安全保障措施。通常包括身份认证、访问控制、数据加密和防火墙等措施。
-
数据备份和恢复:表示系统或服务备份和恢复数据的能力。通常包括备份频率、数据存储位置、备份恢复时间等指标。
-
报告:表示系统或服务提供的报告及时性和准确性。通常包括定期报告、实时报告和数据可视化等方式。
这些指标通常按照优先级进行排序,并设置相应的服务级别目标。如果服务提供商未达到目标,则需要按照协议中规定的方式向客户提供赔偿或其他形式的补偿(“日内瓦,还钱!”)。
其中“可用性”通常被衡量为“几个9”,9越多代表服务全年可用时间越长服务也就越可靠,即停机时间越短。
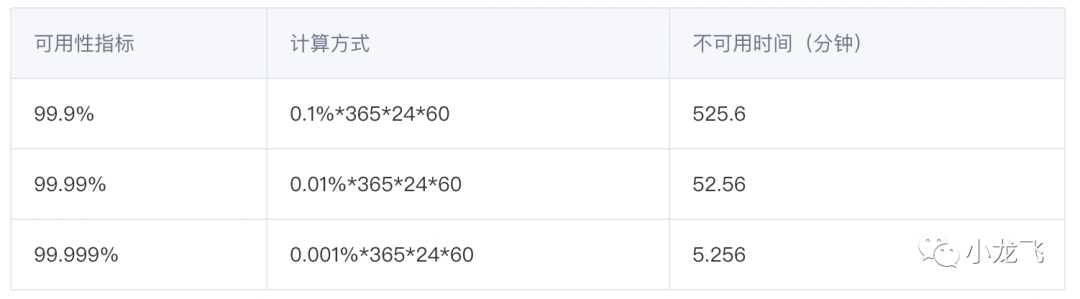
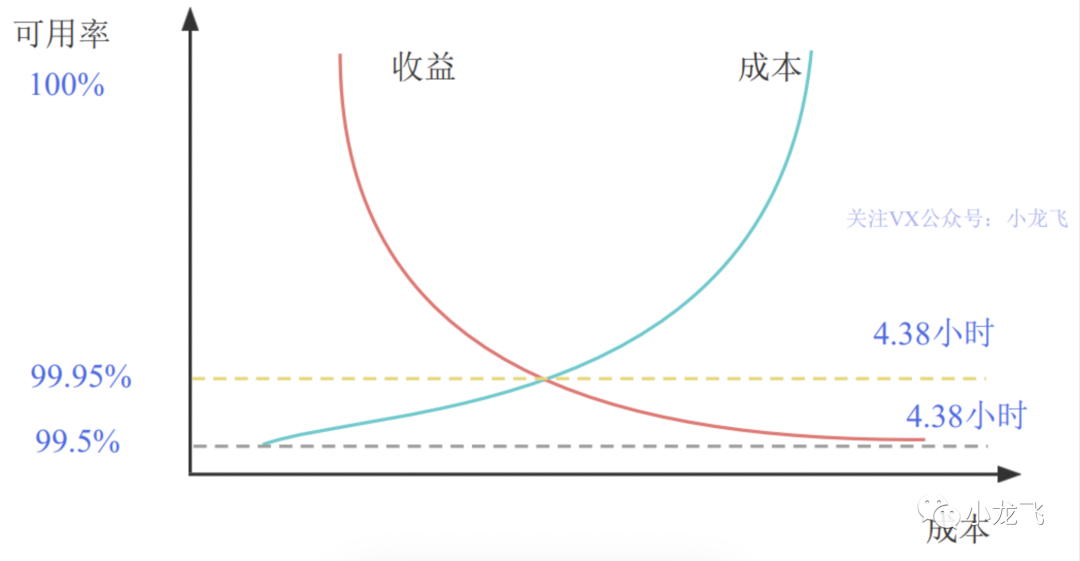
可用性是直接和金钱挂钩的,企业肯定都想着多搞几个9,但是成本也是和金钱挂钩的,越到后面的9保证起来需要的投入成本越高,他们的关系是一个相反的曲线如下:
引发可用率下降的因素
-
系统失败或崩溃
-
应用层或者中间层错误
-
网络失败或故障
-
存储介质失败或故障
-
人为失误或bug
-
同城或异地容灾
-
机房宕机与维护
其中人为失误或bug是导致服务不可用最大的元凶,毕竟发布无时无刻不再发生着,有变动就有风险。
这些年微博跟个太监一样,互联网每家服务崩溃或者异常都要播报一声,例如B站崩溃,阿里云香港机房崩溃,豆瓣崩溃等,我们都已经见怪不怪了。
稳定性治理第一步
了解自己的系统。
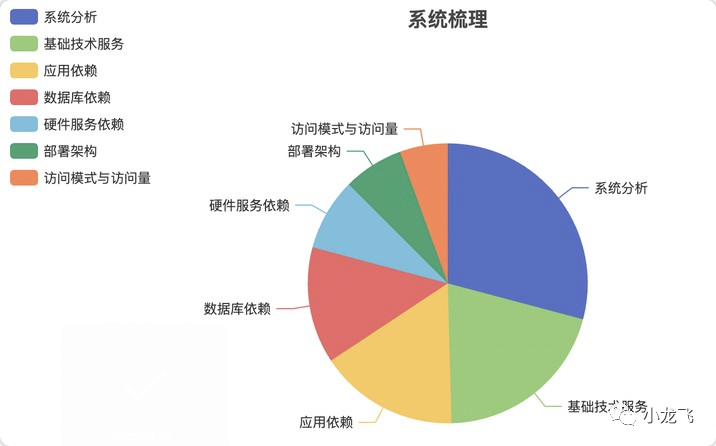
分析梳理系统现状
怎么梳理,梳理哪些内容?实战经验告诉你:
-
系统分析
核心是输出系统核心功能场景的流程图、时序图、架构图,用例图,领域模型等,需要结合业务来进行梳理。
其实就是典型的软件工程方法,浓缩进了教科书的智慧,按照一个个核心功能点的维度,输出或者消化这些图的过程中,我们会遇到很多的疑问,乃至挑战设计,会自动去找答案,恭喜你,已经初步具备一个系统 owner 的资质了!
-
应用依赖(强弱依赖、同步或异步、依赖权重-次数)
核心是输出上下游调用关系,系统间调用依赖关系。再结合一些系统调用数据,以及业务关联,得出强弱依赖,同步异步依赖,依赖权重等,我们治理的时候可以进行进行权重打标,降级打标。
-
数据库依赖 (强弱依赖、依赖权重) 可能很多简单系统都只有一个数据库,数据库挂了整个系统就挂了,实际上很多重要的复杂系统都会同时具有多个数据源,将核心业务从数据源层面隔离开,哪怕有天数据库挂了,也不是业务全挂。
核心是输出业务与数据库依赖关系,数据库的部署架构,如果能输出慢sql治理方案,画出数据库表ER图,那么到这个层面,整个系统你差不多都能掌握的七七八八了。
-
硬件服务依赖 (存储, 网络、负载均衡,cdn)
硬件这个方面,就交给硬件运维吧,专业的事情交给专业的人来做,软件工程师不瞎搞就是最大的帮助了(狗头保命)。
但是作为软件工程师,是非常有必要了解这些硬件的基本指标信息的,自己买个阿里云服务器个也得知道这些吧,工作中我们申请机器,申请资源的时候,要评估申请的量,如果公司资源紧张,明显达不到系统要求的情况下,是需要勇敢走特批申请的,否则真故障了责任还是你的。因此,核心是靠基本功,了解网络、负载均衡、CDN、带宽、存储等基本的指标信息,最好是原理,大学那四本考研教材是最基本的!
-
基础技术服务(配置中心、KV缓存、消息中心、定时任务等基础依赖)
中间件依赖,我们要掌握的核心是:
-
缓存设计(如何更新,如何插入,失效时间等)
-
消息依赖,系统发布了哪些消息,订阅了哪些消息,什么时机发送的,核心的消费者有哪些,如果出现问题对自身系统和下游的核心影响是什么
-
定时任务,有哪些定时任务,是什么业务需要
这些都是系统的重要组成部分,我们需要一一整理出来。
-
部署架构(同城容灾、异地多活、单元化部署)
这种一般会有专门的资料,我们需要去看,和我们系统部署的时候息息相关,我们要结合自己的业务特点,match 公司的部署方案。核心是弄清理论上、系统上如何实现同城容灾、异地多活、以及单元化部署,
-
访问模式与访问量(推算与调用量间的关系,为容量分析与规划做准备)
访问模式是指用户访问网站或应用的方式和习惯,例如访问时间、频率、页面浏览深度等。
访问量是指用户访问网站或应用的次数或流量。
核心是根据访问模式和访问量可以推算出未来的访问量,并进行容量分析和规划。例如,如果一个网站平均每天有1万次访问,但在周末有2万次访问,那么在容量规划时需要考虑周末的访问量来确保服务器能够承受高峰期的访问量。
这个系统分析的方案,其实适用于所有的系统熟悉阶段,怎么快速熟悉一个系统,提高效率,这七个步骤是非常适用的。小人不才,用这套组合拳,在几个月内熟悉了14个系统,当系统足够复杂的时候,方法论非常重要。
小结

脱离系统现状谈稳定性治理就是耍流氓,而且系统稳定性治理不是说一下子就完成了,而是一步一步实现的,一步步进行优化的。
作为一个有理想的程序猿,我们要想的是平时如何做好服务稳定性治理,将风险降低到最低,哪怕真的有天中奖了,也要将伤害降到最低。
最近有计划出一篇系统稳定性治理的专题,因为业余时间有限,因此采用连载的方式,本篇是目录内第一篇,为后面的系统稳定性分析做准备,都是实战经验贴,感兴趣的可以关注我。