RoBERTa 阅读笔记

RoBERTa 阅读笔记
https://arxiv.org/abs/1907.11692
总的来说,bert在模型上并没有做太多的改进,只是在训练数据和训练策略上进行了一个改进。
相较于BERT的改进
1. Masking策略
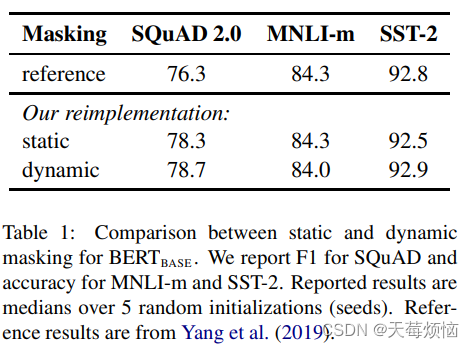
stastic: 原始 BERT 的 masking 是固定的,RoBERTa 给相同的 sentence 做了10个不同的mask,训练40个epoch,每个mask训练4次。
dynamic: 每次训练前再随机mask。
2. Model Input Format and No NSP
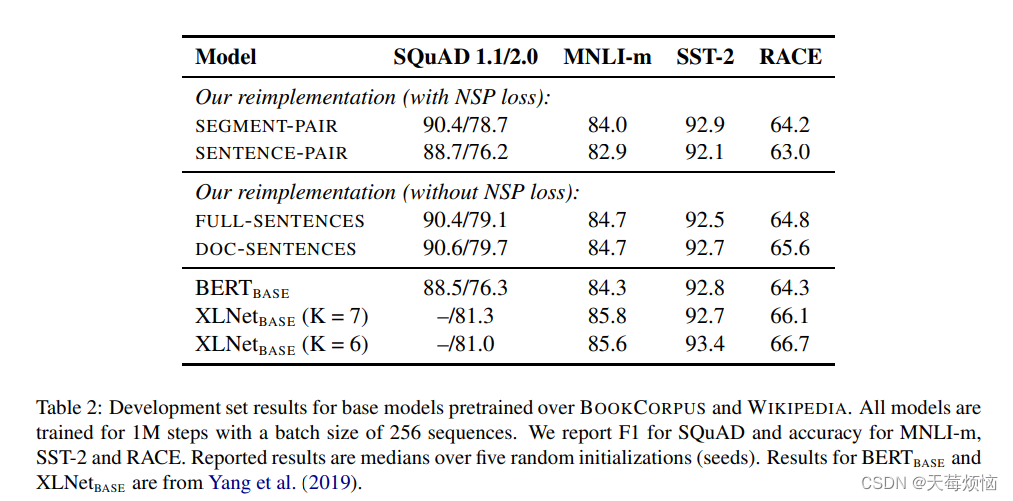
更改了模型的输入方式,并且去除了 NSP 任务,只保留 MLM 任务进行训练。然后在公开数据集上测试,发现去除 NSP 任务更好。
3. Larger Batch Size
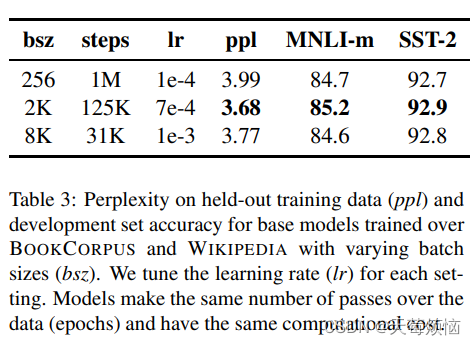
采用了更大数据量和更大的 batch size 进行训练。
4.字节对编码 (BPE)
关于字节对编码,可以参考这篇博客:
自然语言处理中常见的字节编码对(Byte-Pair Encoding,BPE)简介
原始 bert: 采用的是字符级别的 BPE,就会像博客中的那样,将 aa 这个 sub-word 作为一个 unit 去压缩,介于字符和单词之间。
RoBERTa: 采用的是字节级别的 BPE,也就是将字母改成一串串的 01 字节,这样是基于字符级别下的字节级别,unicode占用1-4个字节,也就是8-32位字,这样做不会引入 UNK 标记。
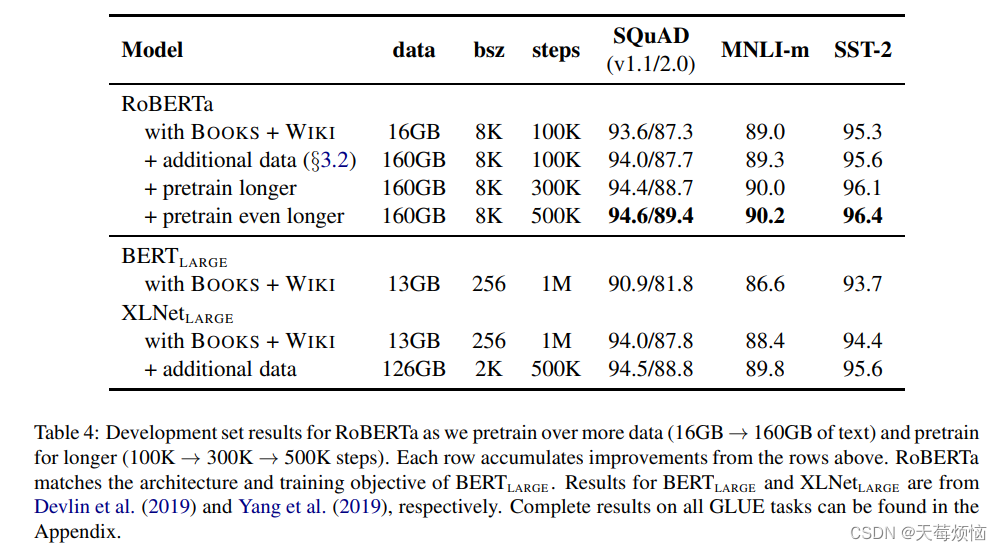
最终模型
将以上的所有改进内容合起来就是 RoBERTa,效果如下: