中间表示- 到达定义分析

基本概念
定义(def):对变量的赋值
使用(use):对变量值的读取
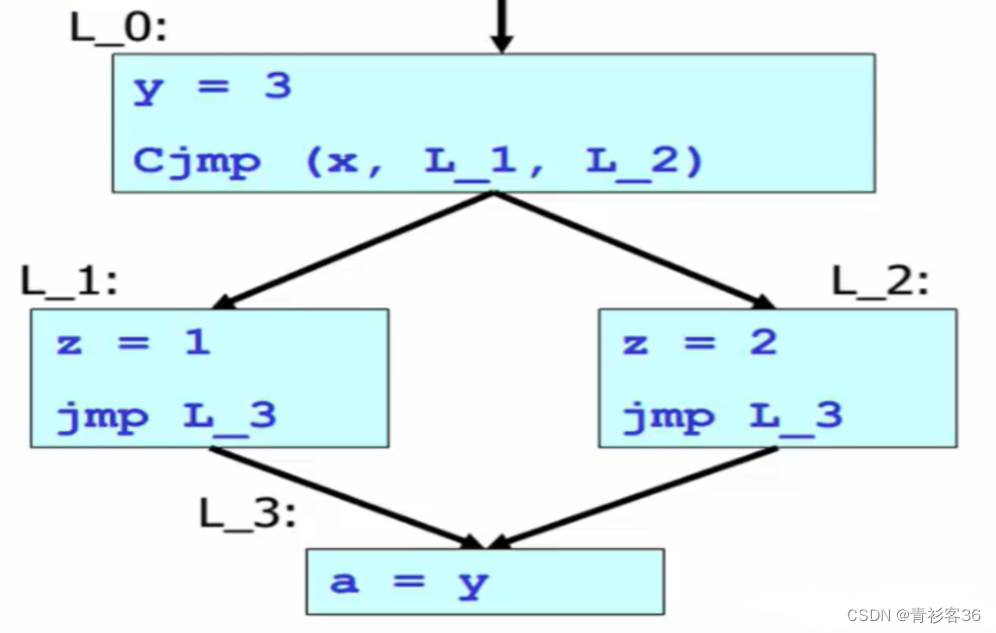
问题:能把上图中的y替换为3吗?如果能,这称之为“常量传播”优化。
该问题等价于,有哪些对变量y的定义能够到达语句a = y?
到达定义:对每个变量的使用点,有哪些定义可以到达?(即:该变量的值是在哪儿赋值的?)
如果赋值点有且只有一个,并且那个赋值点是一个常数的话,那么就可以做常量传播了。
所以,到达定义是一种程序分析,这种程序分析的结果就可以用来指导接下来我们做常量传播这种优化。再次印证了下面这张图。
接下来的问题是,如何用算法来做到达定义分析?
在此,我们引出数据流分析中非常重要的数学工具——数据流方程
数据流方程

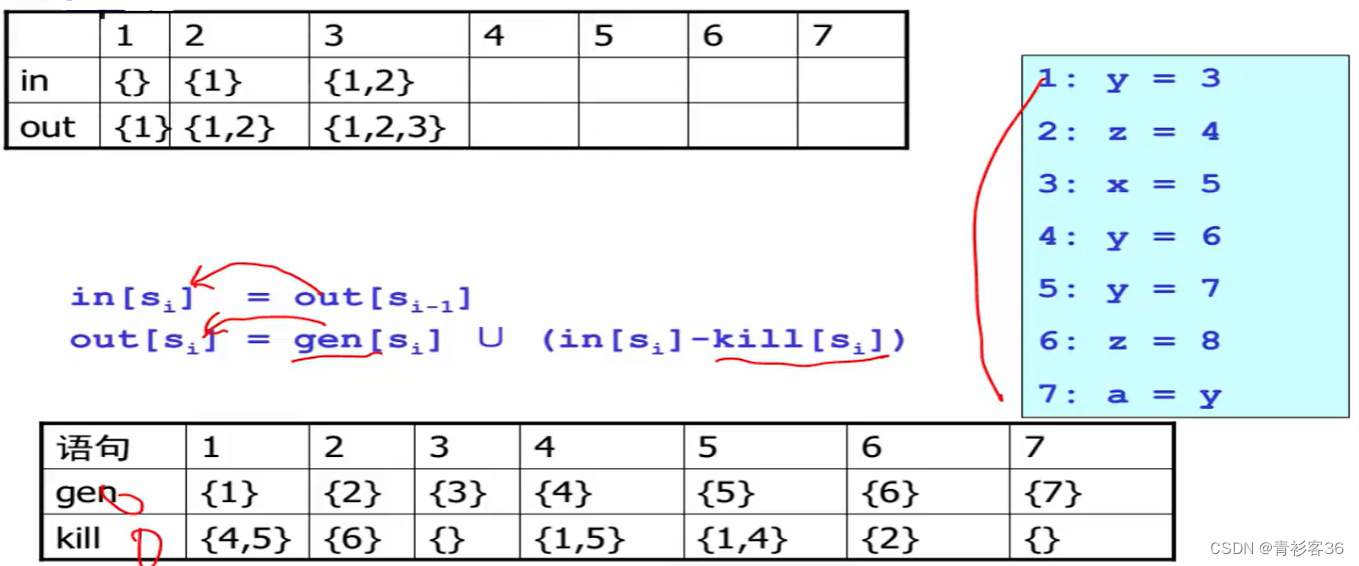
注:d是这条定义的编号,x的变量(比如,右侧第一条定义[1: y = 3])
- gen(产生集)这个集合中存放的是语句的编号,因为语句编号和语句是一一对应的(双射关系),所以可以理解为语句本身。例如,gen[1: y = 3] = {1},可将gen集合理解为当前的这条语句给出了一条什么定义,显然,如果它是一条定义的话,就生成自身。从4向下走就可以见到4处定义了y(可在此直观的体会一下生成的含义)。
- kill集合,例如kill[4: y = 6] = defs[y] - {4} = {1, 5},可以理解为,这些集合都被当前的定义点杀死,只能看到此处(定义点)的4,其他的y所在的序号都被屏蔽了。
- defs[x]是x的所有定义点,例如defs[y] = {1, 4, 5}。
下面再解释一下数据流方程
给每条语句定义两个集合in[S]和out[S],in集合表示在进入语句S之前,有哪些定义是可以见到的(有多少语句是可达的,可到达这儿的),out集合表示经过S之后有哪些语句是可以出去,继续到达下一条的。
结合下面这个例子,看看每个定义点处的in和out集合都是什么

in[1] = {∅},out[1] = {1}
in[2] = {1},out[2] = {2,1}
in[3] = {2, 1},out[3] = {3,2,1}
in[4] = {3,2,1},out[4] = {4,3,2}
注意,在此处到达5的定义是{4,3,2}没有1,意味着y在1处的定义是不可能到达5的,因为它总是会被4覆盖掉。
结合前面的内容,如果要做常数传播优化的话,结合到达定义分析就比较容易做了,而且这个到达定义分析是足够精确的,它会忽略掉那些不会到达的定义,只会算静态看可以到达的。
可以这么理解数据流方程:数据在程序中流动的过程中,每一点都标注了若干数据。
从数据流方程到算法
算法:对一个基本块的到达定义算法
- 输入:基本块中所有的语句
- 输出:对每个语句计算in和out两个集合
List_t stms; // 一个基本块中的所有语句
set = {}; // 临时变量,记录当前语句s的in集合
reaching_definition()
{foreach (s ∈ stms){in[s] = set;out[s] = gen[s] ∪ (in[s] - kill[s]);set = out[s];}
}
对于一般的控制流图
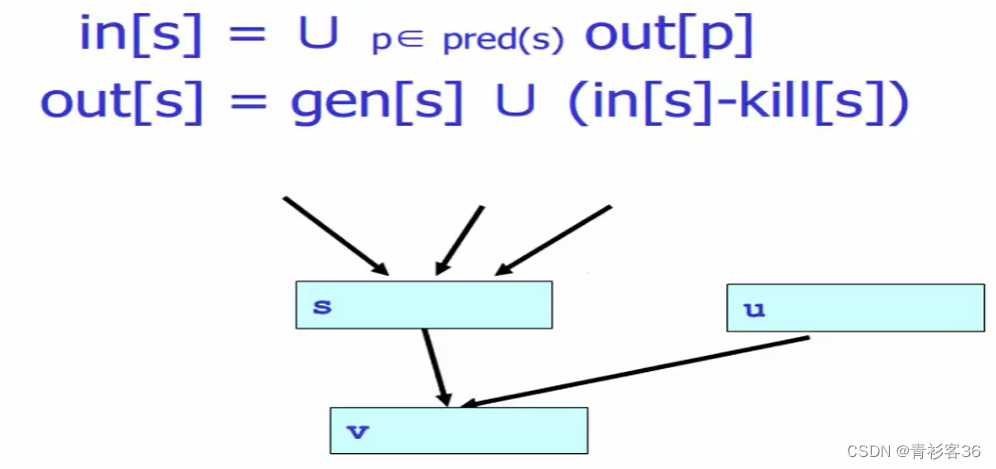
以上讨论的都是基本块内的,那么对于一般的控制流图呢?我们可以写以下两条前向数据流方程,注意,我们只是对刚才基本块内的方程做了推广。
前向数据流方程
从数据流方程到不动点算法
算法:对所有基本块的到达定义算法
- 输入:基本块中所有的语句
- 输出:对每个语句计算in和out两个集合
List_t stms; // 所有基本块中的所有语句
set = {}; // 临时变量,记录当前语句s的in集合
reaching_definition()
{while (some set in[] or out[] is still changing){foreach (s ∈ stms){foreach (predecessor p of s)set ∪= out[p];in[s] = set;out[s] = gen[s] ∪ (in[s] - kill[s]);}}
}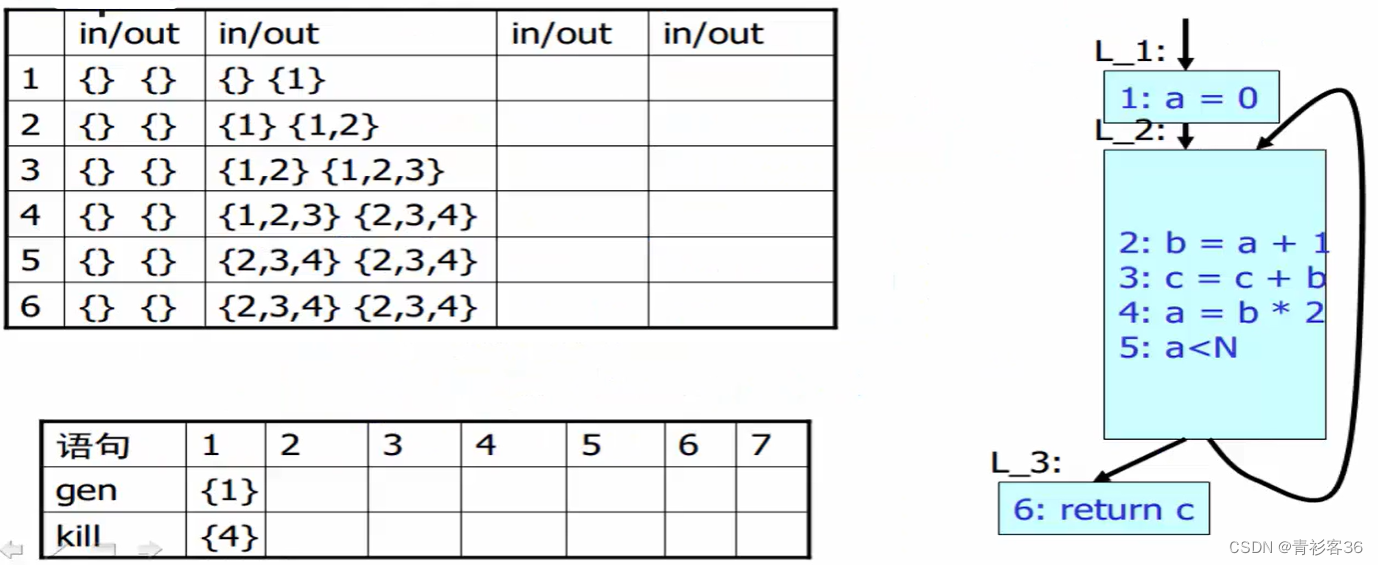

一开始6条语句上的每个in和out集合都初始化为空集,先来看第一遍运算,从第一号语句开始,它的in集合为初始的空集,out集合通过计算为{1},这样的计算前后对比,out集合发生了变化。同理,我们继续计算2号语句,它的in等于前驱元素out的并,我们可以看到有两条边进入2号,所以它有两个前驱元素(1号和5号),1号的out集合为{1},5号的out集合为{},所以2号语句的in集合为{1},2号语句的out通过计算为{1, 2},同理可以依次计算3-6。
为什么叫不动点呢?因为这其中包含一个循环,从5号语句出发又重新回到了2号语句这边,这样的循环导致对这里面到达定义的分析不可能一遍完成,正如我们在上图第一个表格中看到的,第一遍初始值与第二遍计算结束后,有些集合(确切的来说是2n - 1个集合)都发生了变化,只有第一个集合没有变,所以只要有集合还在发生变化,那么我们就要进行下一轮,如果还有变化的话,就继续进行下一轮,直到到达一个不动点为止。
该不动点算法为什么可以终止?因为对于一个确定的程序而言,每个基本语句的in,out集是固定且有限的。