pytorch进阶学习(二):使用DataLoader读取自己的数据集

上一节使用的是官方数据集fashionminist进行训练,这节课使用自己搜集的数据集来进行数据的获取和训练。
所需资源
教学视频:https://www.bilibili.com/video/BV1by4y1b7hX/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=e482aea0f5ebf492c0b0220fb64f98d3
pytorch进阶学习(一):https://blog.csdn.net/weixin_45662399/article/details/129737499?spm=1001.2014.3001.5501
课程准备:本节课需要用到3个Python文件和一个数据集文件,代码后面我都会给出,zip需要自己下载,,数据集zip文件和所需的三个代码文件可以在“leo在这”进行下载。
一、数据集文件准备
1.1 项目文件结构
下图为我的项目文件在远程服务器上的目录,需要新建一个dataset中为上传的自己的数据集。
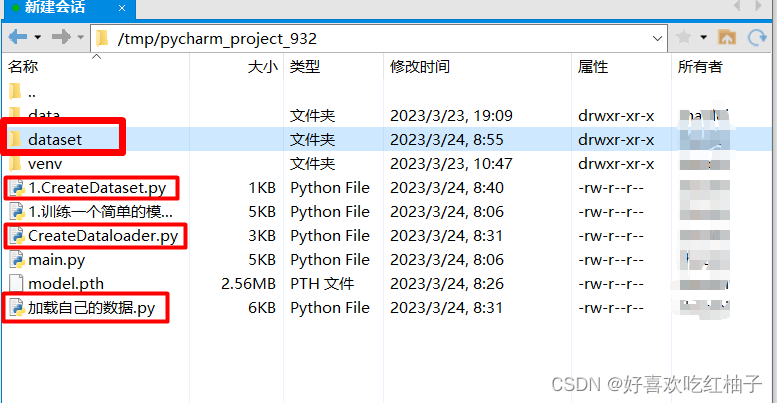
1.2 上传数据集到服务器
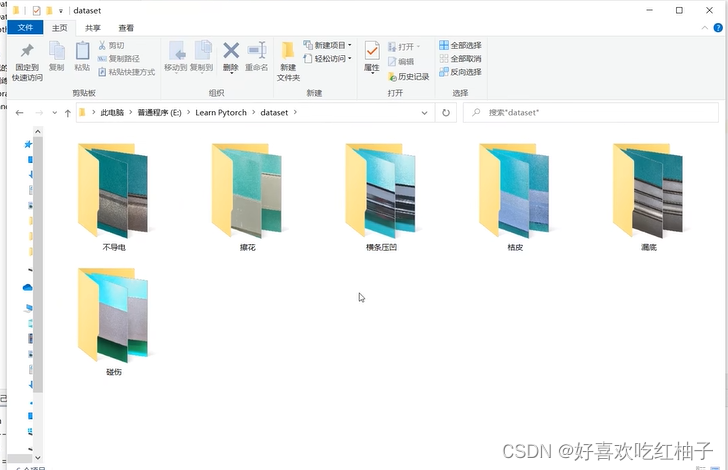
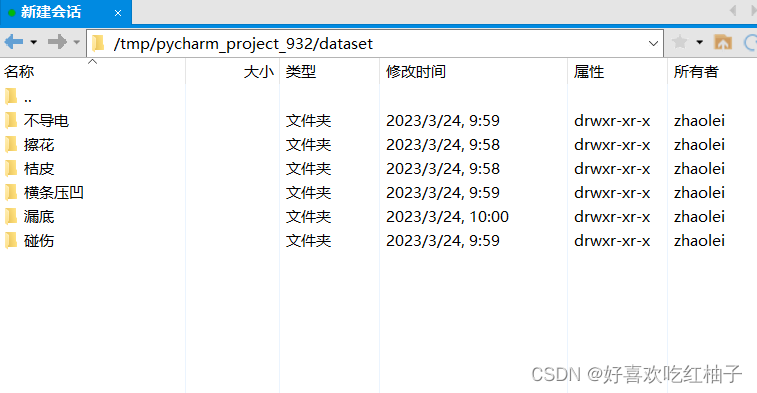
数据集文件解压后如下所示,有6个子文件夹,对应6个类别。
我们先把dataset.zip上传到服务器中的代码项目文件夹中。一定要找到服务器中项目的路径,不要传错位置!
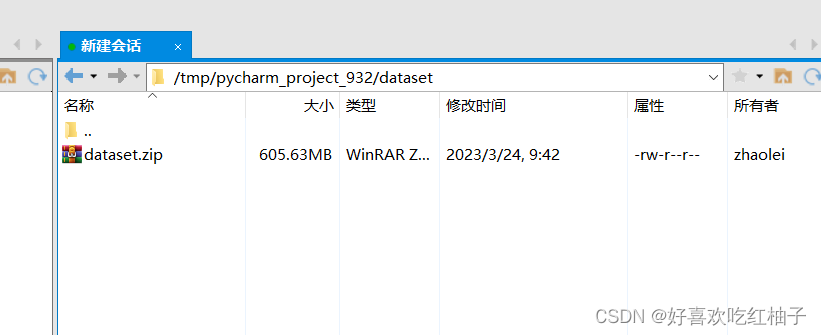
我的项目目录在服务器中的路径为“tmp/pycharm_932”,数据集zip文件即下载到tmp/pycharm_932/dataset目录下。
1.3 解压zip文件
回到服务器控制台在红,先使用cd命令定位到tmp/pycharm_932/dataset路径下,然后使用unzip 'dataset.zip'命令解压压缩文件。
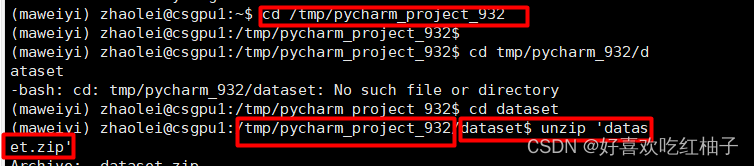
可以看到服务器完成了解压。
最后把zip文件从dataset文件夹中删去即可,最终解压好的文件如下。
1.4 代码框架解读
-
'CreateDataset.py' 用于把数据集文件夹中的所有图片文件生成一个TXT文件,其中存放着所有图片的路径和图片对应的标签。
-
'CreateDataLoader.py' 用于把上一步生成的TXT文件中的信息提取出来,进行图片信息的打包,生成一个dataloader
-
最后在'加载自己的数据.py' 文件中对dataloader进行使用,并且完成网络的训练和测试。
二、运行CreateDataset.py
作用:该代码可以生成训练集和测试集中每张图片的路径和标签,保存在TXT文件中。后续即可以从文件中调用每一张图片,进行读取。
2.1 代码实现
'''
生成训练集和测试集,保存在txt文件中
'''import os
import random#60%当训练集
train_ratio = 0.6
#剩下的当测试集
test_ratio = 1-train_ratiorootdata = r"dataset"train_list, test_list = [],[]
data_list = []class_flag = -1
for a,b,c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a,c[i]))for i in range(0,int(len(c)*train_ratio)):train_data = os.path.join(a, c[i])+'\\t'+str(class_flag)+'\\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio),len(c)):test_data = os.path.join(a, c[i]) + '\\t' + str(class_flag)+'\\n'test_list.append(test_data)class_flag += 1print(train_list)
random.shuffle(train_list)
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)2.2 运行结果
可以看到此时服务器中文件管理器中已经有了test.txt和train.txt两个文件。
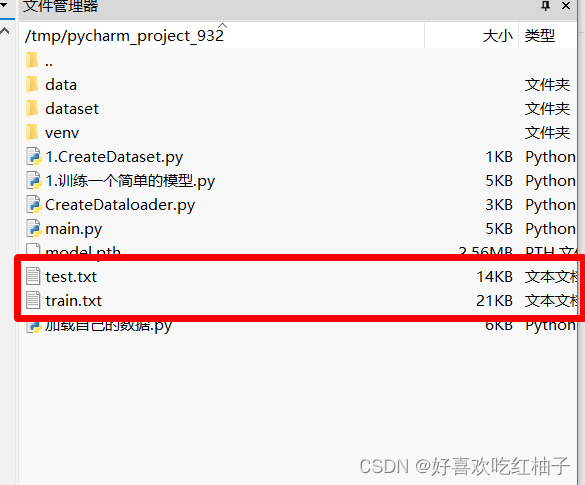
生成了train.txt和test.txt两个文件,里面保存了每张图片的对应相对路径和类别标签,标签是以int型进行存储。打开test.txt文件可以发现里面的内容为测试集所有图片路径以及其标签。
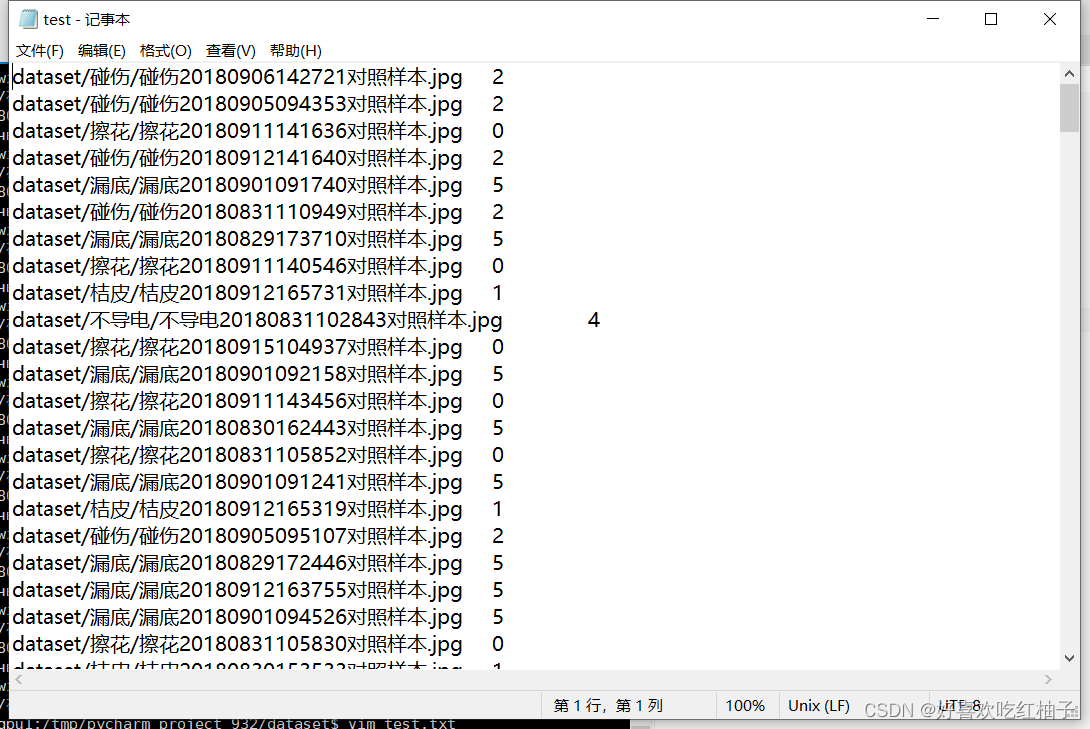
2.3 代码要点解析
-
对训练集和测试集的划分比例为6:4
rootdata为数据集文件保存的根目录,为dataset文件夹。
#60%当训练集
train_ratio = 0.6
#剩下的当测试集
test_ratio = 1-train_ratio
rootdata = r"dataset"2. 读取文件夹
-
a读取文件夹根目录,再使用c[i]读取每个图片的名称,使用os.path.join进行拼接,实现每张图片的相对路径的path存取。可以看到a为dataset加上下面类别子文件夹。
dataset/擦花
dataset/桔皮
dataset/碰伤
dataset/横条压凹
dataset/不导电
dataset/漏底
和c[i]进行拼接后即可完成每一张图片的定位。
dataset/碰伤/碰伤20180906142721对照样本.jpg
-
然后使用class_flag进行图片类别标签的存储,从0开始依次增加,一共6个类别,故取值为【0,5】。
-
path和label之间使用\\t进行分割,即一个tab的距离。
for a,b,c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a,c[i]))for i in range(0,int(len(c)*train_ratio)):train_data = os.path.join(a, c[i])+'\\t'+str(class_flag)+'\\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio),len(c)):test_data = os.path.join(a, c[i]) + '\\t' + str(class_flag)+'\\n'test_list.append(test_data)class_flag += 13. 写入文件
-
使用shuffle打乱数据集的顺序,把上面生成的每一张图片的“路径+标签”转为字符串形式,然后存入txt文件中。
-
因为文件名有中文,所以使用utf-8编码形式。
random.shuffle(train_list)
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)三、CreateDataLoader.py
作用:完成对上一步dataset中生成的txt文件中对图片和标签信息的读取,将图片进行打包放入图片加载器DataLoader中。
使用系统带的数据集如下代码所示,将带的数据集存在training_data中,将training_data作为参数传入DataLoader中。
training_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),
)# 下面是测试集,同样需要下载
test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),
)train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)可以看到我们代码是使用LoadData类自己新建了一个数据集train_dataset,然后把train_dataset传入DataLoader中。
train_dataset = LoadData("train.txt", True)# 传入dataloader中
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=10,shuffle=True)3.1 代码实现
import torch
from PIL import Imageimport torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = Truefrom torch.utils.data import Dataset# 数据归一化与标准化# 图像标准化
transform_BZ= transforms.Normalize(mean=[0.5, 0.5, 0.5],# 取决于数据集std=[0.5, 0.5, 0.5]
)#读取TXT文件
class LoadData(Dataset):def __init__(self, txt_path, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flagself.train_tf = transforms.Compose([transforms.Resize(224),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transform_BZ])self.val_tf = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transform_BZ])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x:x.strip().split('\\t'), imgs_info))return imgs_infodef padding_black(self, img):w, h = img.sizescale = 224. / max(w, h)img_fg = img.resize([int(x) for x in [w * scale, h * scale]])size_fg = img_fg.sizesize_bg = 224img_bg = Image.new("RGB", (size_bg, size_bg))img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,(size_bg - size_fg[1]) // 2))img = img_bgreturn imgdef __getitem__(self, index):img_path, label = self.imgs_info[index]img = Image.open(img_path)img = img.convert('RGB')img = self.padding_black(img)if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)if __name__ == "__main__":train_dataset = LoadData("train.txt", True)print("数据个数:", len(train_dataset))train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=10,shuffle=True)for image, label in train_loader:print(image.shape)print(image)# img = transform_BZ(image)# print(img)print(label)# test_dataset = Data_Loader("test.txt", False)# print("数据个数:", len(test_dataset))# test_loader = torch.utils.data.DataLoader(dataset=test_dataset,# batch_size=10,# shuffle=True)# for image, label in test_loader:# print(image.shape)# print(label)3.2 运行结果
我学校服务器跑大约等了两分钟,然后跑完后出现如下结果。


可以看到数据集中有380张图片,图片大小为224*224,dataloader中图片每10个为一组,tensor中为10个图片的标签。
3.3 代码要点解析
3.3.1 class LoadData init方法
-
该类的初始化方法,定义了两个变量,img_info为get_images方法获取的信息,是一个list,保存着图片的路径和标签;train_flag为标志点,标志是否为训练集,TRUE为时=是,否则为测试集。
-
train_tf和val_tf使用compose完成对图片样式的变换,如定义大小为224*224,随机水平展平,正则化等。
3.3.2 get_images方法
通过txt文件的路径读取到txt中信息,使用‘\\t’分割图片路径和图片标签,并且保存在imgs)info的列表中。
3.3.3 padding_black方法
如果图片过小,使用padding填充该图片,使其能够成为224*224大小。
3.3.4 getitem方法
-
该方法为class loaddata的主方法,使用index下标获取到每一张图片的path和label后,用flag判断为训练集还是验证集,并且采用对应的图片处理措施(train_tf/val_tf)。
-
返回的是图片和对应标签。
3.3.5 main方法
-
把LoadData生成的数据存入train_dataset中,作为数据集传入torch的data.DataLoader类中,设置batchsize=10.
-
10张图片为一组,输出每张图片和标签。
四、加载自己的数据.py
4.1 代码实现
大部分和第一节中的模型一样。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
from CreateDataloader import LoadData# 定义网络模型
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()# 碾平,将数据碾平为一维self.flatten = nn.Flatten()# 定义linear_relu_stack,由以下众多层构成self.linear_relu_stack = nn.Sequential(# 全连接层nn.Linear(3*224*224, 512),# ReLU激活函数nn.ReLU(),# 全连接层nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 6),nn.ReLU())# x为传入数据def forward(self, x):# x先经过碾平变为1维x = self.flatten(x)# 随后x经过linear_relu_stacklogits = self.linear_relu_stack(x)# 输出logitsreturn logits# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。for batch, (X, y) in enumerate(dataloader):# 将数据存到显卡X, y = X.cuda(), y.cuda()# 得到预测的结果predpred = model(X)# 计算预测的误差# print(pred,y)loss = loss_fn(pred, y)# 反向传播,更新模型参数optimizer.zero_grad()loss.backward()optimizer.step()# 每训练100次,输出一次当前信息if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test(dataloader, model):size = len(dataloader.dataset)print("size = ",size)# 将模型转为验证模式model.eval()# 初始化test_loss 和 correct, 用来统计每次的误差test_loss, correct = 0, 0# 测试时模型参数不用更新,所以no_gard()# 非训练, 推理期用到with torch.no_grad():# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)for X, y in dataloader:# 将数据转到GPUX, y = X.cuda(), y.cuda()# 将图片传入到模型当中就,得到预测的值predpred = model(X)# 计算预测值pred和真实值y的差距test_loss += loss_fn(pred, y).item()# 统计预测正确的个数correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= sizecorrect /= sizeprint("correct = ",correct)print(f"Test Error: \\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \\n")if __name__=='__main__':batch_size = 16# # 给训练集和测试集分别创建一个数据集加载器train_data = LoadData("train.txt", True)valid_data = LoadData("test.txt", False)train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)for X, y in test_dataloader:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break# 如果显卡可用,则用显卡进行训练device = "cuda" if torch.cuda.is_available() else "cpu"print("Using {} device".format(device))# 调用刚定义的模型,将模型转到GPU(如果可用)model = NeuralNetwork().to(device)print(model)# 定义损失函数,计算相差多少,交叉熵,loss_fn = nn.CrossEntropyLoss()# 定义优化器,用来训练时候优化模型参数,随机梯度下降法optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 初始学习率# 一共训练5次epochs = 5for t in range(epochs):print(f"Epoch {t+1}\\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model)print("Done!")# 读取训练好的模型,加载训练好的参数model = NeuralNetwork()model.load_state_dict(torch.load("model.pth"))4.2 运行结果
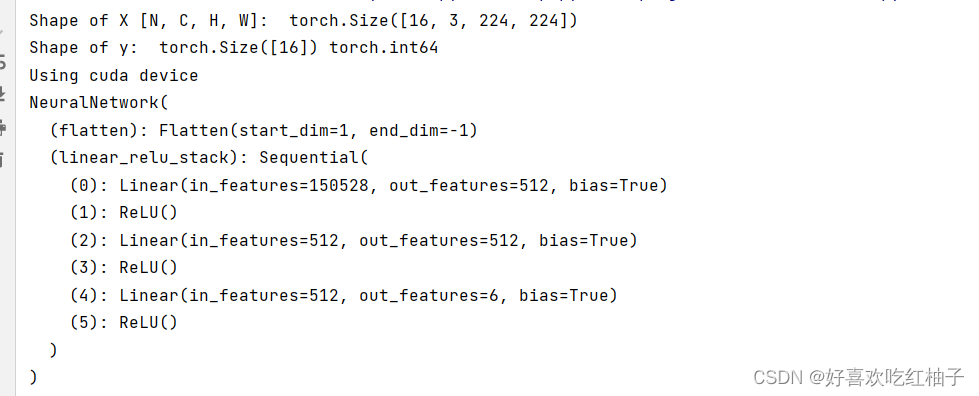
首先打印出来了网络的结构。
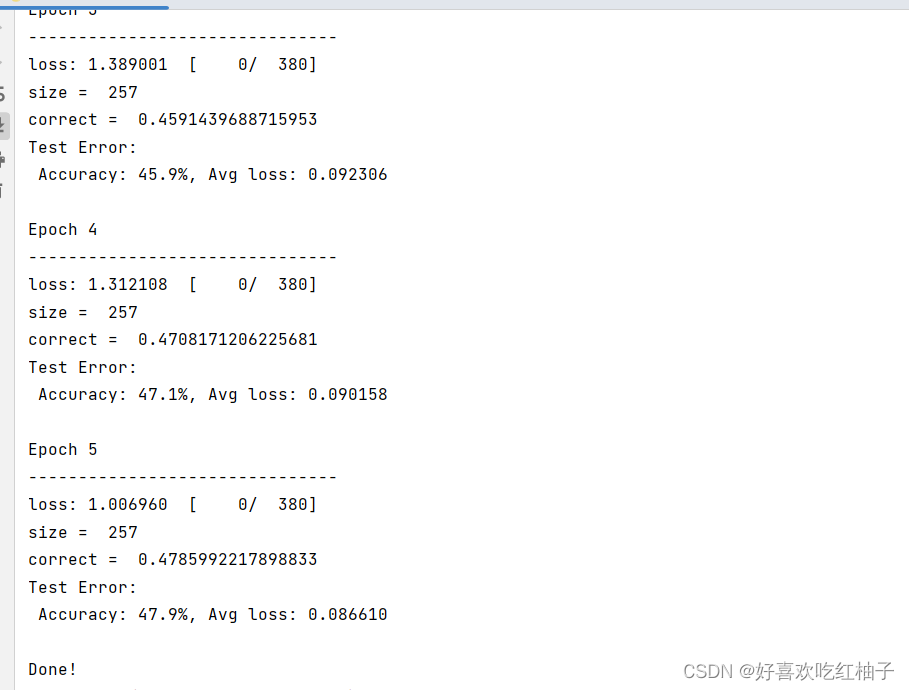
之后是训练模型的结果,一共有5个epoch,可以看到准确率不是很高。
4.3 代码解析

num_workers为cpu使用多线程读取数据,pin_memory为不写入虚拟内存