数据仓库简介

数据仓库诞生的原因
- 历史数据的积存
- 企业数据分析的需要
历史数据的积存
线上的业务系统随着业务的进行,会源源不断的产生数据,这些数据都会存储在业务数据库中,比如mysql等。但是随着业务系统的运行,数据库中积压的数据就会越来越多。对业务数据库就会产生一定的负载,导致业务系统的运行速度较慢。
堆积的数据当中,相当一部分的是冷数据。一般最长调用的都是最近的数据,过早的数据调用的频率就很低。为了避免由于冷数据的积压导致业务系统的缓慢,就需要定期将业务数据库中的冷数据存储到一个专门存储历史数据的仓库中。这个仓库就是数据仓库。
企业数据分析的需要
在没有建立数据仓库之前,企业要进行数据分析,数据的来源是业务数据库。
但是这种方法是有弊端的。
首先,各个部门的分析结果就会不一致,因为如果两个部门是在不同的时间抽取的同一个业务数据库的数据进行分析,结果肯定会不一致。其次,每个部门都要建立数据抽取系统,就会产生资源的浪费,每个数据抽取系统都要数据库的权限,数据库的权限管理也会变得麻烦。同时还会降低数据库的性能
这时就可以建立一个数据仓库,统一对业务数据库中的数据进行抽取,就可以解决上面的问题
数据仓库的基本概念
数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据结合
主要应用与积累历史数据,利用分析方法进行分析整理,进而辅助决策
数据仓库的特点
面向主题:为数据分析提供服务,根据主题将原始数据整合在一起[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传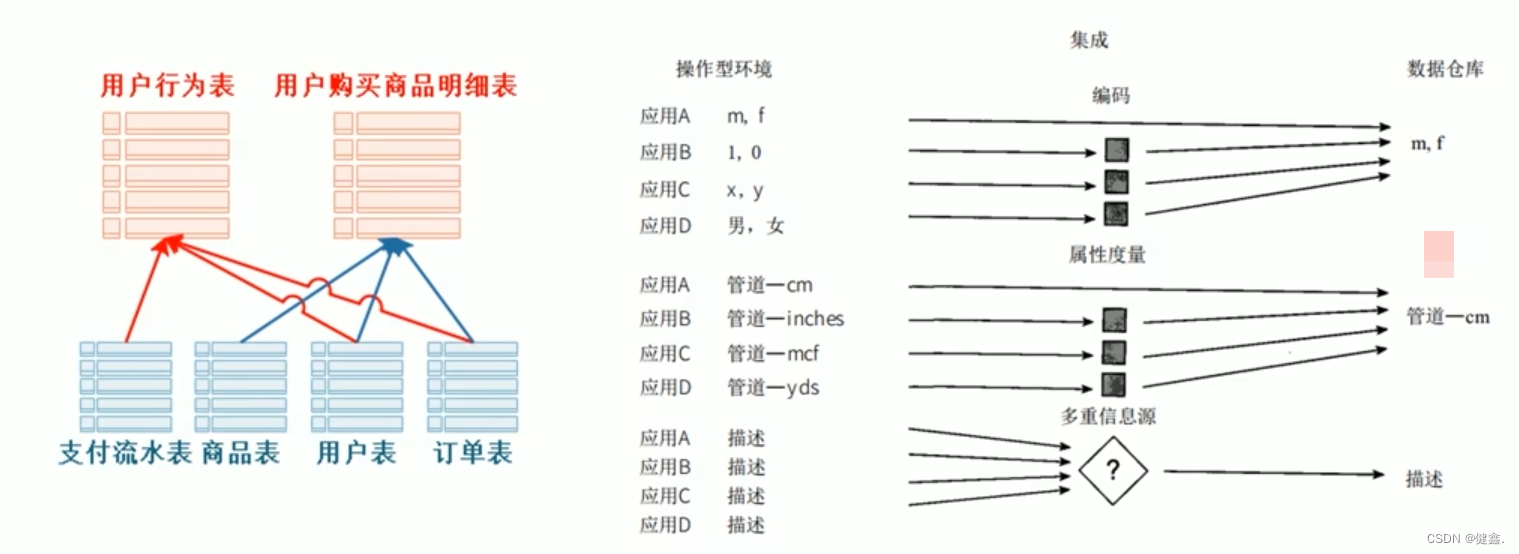
集成:原始数据来源于不同的数据源,要整合成最终的数据,需要经过抽取、清洗的过程
非易失:保存的数据都是历史快照,不允许被修改,只允许查询和分析
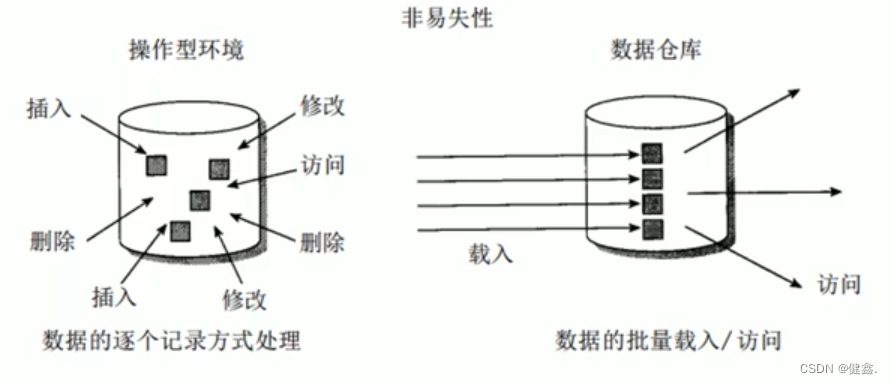
随时间变化:数仓会定期接受新的数据,从而反应出数据的最新变化
数据仓库VS数据库
- 数据仓库是面向事务的,属于OLTP(在线事务处理)系统,主要操作是随机读写。在设计是要避免冗余,要符合范式设计
- 数据仓库是面向主题的,属于OLAP(在线分析系统),主要操作是批量读写吗,注重分析性能,会有意引入冗余,不满足三范式
数据仓库的技术实现
- 传统数据仓库
- 大数据数据仓库
传统数据仓库
传统数据仓库使用关系型数据库进行数据的存储。由多个单机节点组成MPP(大规模并行处理)集群
在数据量没超过某个量级时是非常优秀的解决方案,但一旦超过了某个量级就会产生拓展性有限和热点
问题
由于每个节点都是独立进行计算的,所以进行数据交换的时候会经过高速网络来进行连接,就限制了节点上线
在进行存储时,采用分库分表,将一张大表拆分到各个节点进行存储,节点数越多,出现错误的频率就会越高,集群的可用性就会降低
由于是单机节点,数据存储的位置不透明,需要通过hash来确定数据所在的物理节点,查询任务在所有的节点都会进行
在并行计算时,单节点会成为整个系统的短板,因为如果一个节点运行过于缓慢,其他所有的节点都需要等待这个节点完成任务才能继续运行
大数据数据仓库
采用分布式架构来存储数据,具有极强的扩展性
为了避免海量数据的移动造成的IO和网络的开销,采用了移动计算的架构,也就是将计算任务分发到数据所在的节点
解决了热点问题,因为一个数据默认会存三份,处理数据时节点就是可选的
但是数据仓库缺少事务支持,因为在分布式的环境下要实现事务的难度还是不小的
同时在数据量没到达一定的规模的时候,数据仓库处理数据的速度还是比较慢的,因为要对任务进行拆分、调度、合并,如果数据量很少的话,这个过程所要花费的时间比处理数据所花费的时间都要多