九耶丨钛伦特-教你使用Java语言清洗京东商品数据

数据清洗是数据处理的前奏,也是数据处理的关键所在。使用java语言通过mapreduce技术可以实现数据清洗,一般对日志类型的数据会进行这样的清洗。
数据的清洗主要需要处理的是数据的过滤,重在三步走,去重,去空,去异常。
具体操作使用步骤如下。
1、使用IntelliJ IDEA新建项目。
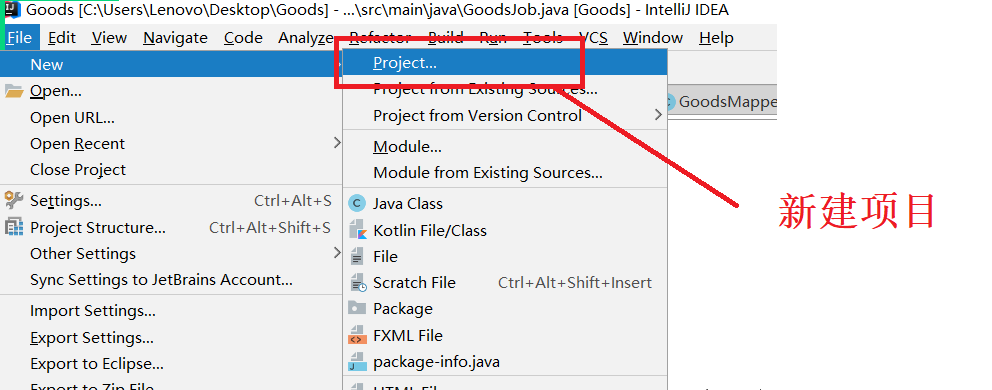
2、这里通过maven技术实现项目数据的清洗。
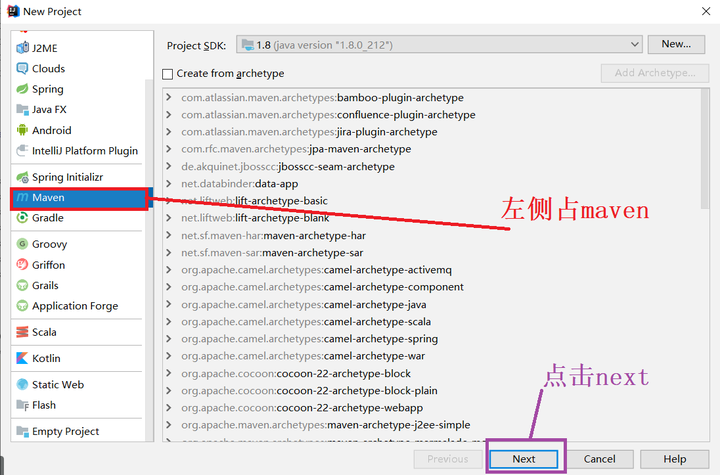
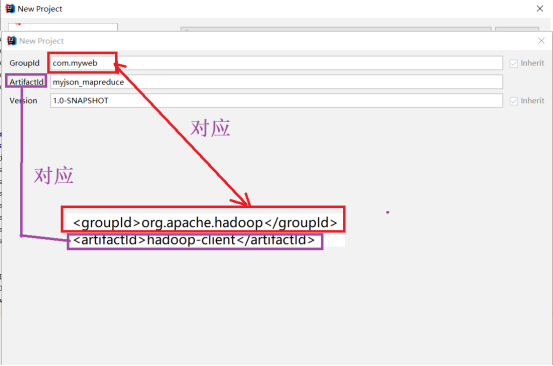
3、接下来添写大数据开发需要的hadoop相关的groupId或artifactId。
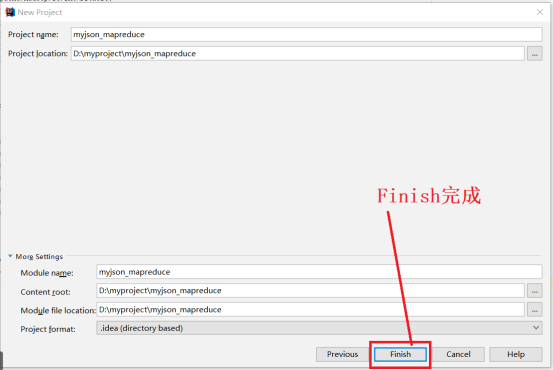
4、点击“Next”进入下一步,接下来的窗口参数默认。点击Finish完成
5、使用maven技术开发项目,需要指定相关依赖。

这里的程序Mapper,Ruducer,Job,一定要注意json数据是值对,值对有JavaBean对应。
值对就是面向对象,面向对象就是一个属性一个值,json数据就是一个属性一个值。json对应java对象。遇到json一定有JavaBean。
注意企业中常见的问题就是wordcount的问题,即在项目中统计文档中英文出现的个数,如英文单词 hadoop的个数,结合到企业中的分析,如一天内用户点击率有多少,把用户点击率当成word,然成求count,只要清楚哪一列是用户点击率。
下面进入开发的步骤,需要建立JavaBean,JavaBean作用让你知道每一列到底是何意义。
第一步:建立一个GoodsBean,建立之后数据有意义。
第二步:把GoodsBean里面Json对应的属性全部写入 。
注意:price为什么在Bean中定义成String,它是Float型,我们要做的事是清洗,去空,如果抓取的price为空,这个地方显示空,如果是Float,这个地方显示的是0。爬虫爬取的时候,一般原生数据直接爬取,是空的可能性比是0的可能性大。尤其对爬虫来说不是写代码,比如八爪鱼这类类似于爬虫的工具,这个不需要写代码。这里就把price做字符串处理。后续导入hive时没有空数据,没有空数据就可以作Float。
定义完属性后,代码如下:
定义getter和setter 方法,为了面向对象的封装道理,因为私有属性,做取数据和设置数据的接口。
在代码处右键,选择”Generate....”
点击”Generate....”,选择getter和setter
把所有的属性都做一个getter和setter方法
点击”Ok”即可。
习惯性地构造两个方法,也就是构造函数,第一个方法无参,为了方便,第二个方法全参。全参目的是应对linux中每一列的意义是从另一个文件中给出的,不是一个json数据,类似于json数据。在公司项目上的合作,大部分都是json数据合作。
在公司中,处理的大数据都是多维度的,有可能达到100列,200列,多类型,最后才是大的数据量。这里产生无参构造器和有参构造器,这是完成JavaBean的步骤所在。
在代码处右键,选择”Generate....”。
构造一个无参构造器。
点击弹出框所有属性,结合shift键,作全参构造器。
这样GoodsBean 的代码如下。

写Mapper方法,继承于Mapper,注意输入,输出的类型,在Mapper中输入只能是LongWritable,Text,因为LongWritable是行号,Text是内容,不是String是因为String的序列化就是Text。序列化原因是两个电脑需要传输数据。再注意输出的类型,maper方法的输出会输出<hadoop,1>,<word,1>,这里想,<json数据1,1>,<json数据2,1>,得出输入的第一个参数是Text,也就是文本,第二个参数就是整数,整数的序列化是IntWritable;
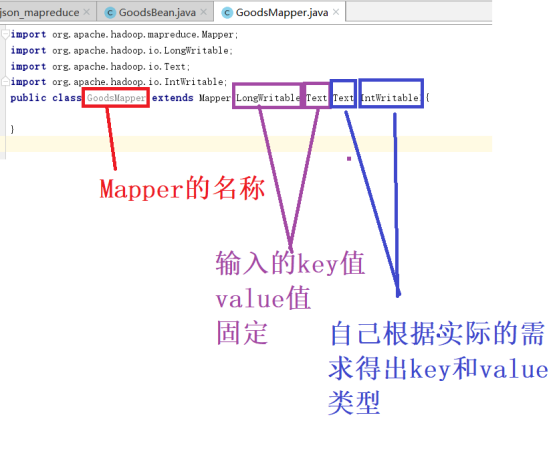
然后在类代码中右键,选择override,即重写的是map方法。
在接下来的弹出对话框中选择map方法。
选择完点击 “OK”即可。
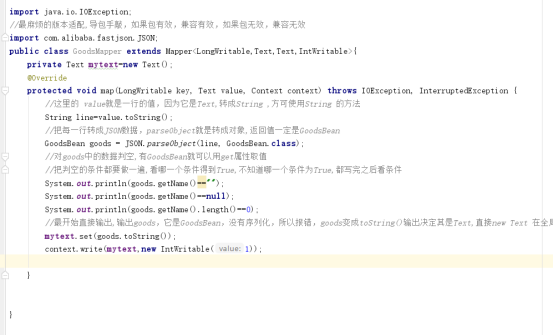
写map的逻辑,在mapper中读取每一行,之后json化数据,判断空数据和判断异常数据,这里的异常是comment_sum中不可以有“万”和”+”。
“万”替换成为”0000”,“+”替换成 空。
现在没有进行清洗处理,为了调试程序的方便,直接把 mapper 的输出写完。
再写GoodsReudcer ,写继承于Reducer。输入是上一级的 Mapper的输出,希望的输出是<json数据>,reduce方法必须输入值对,后面的值就是NullWritable;
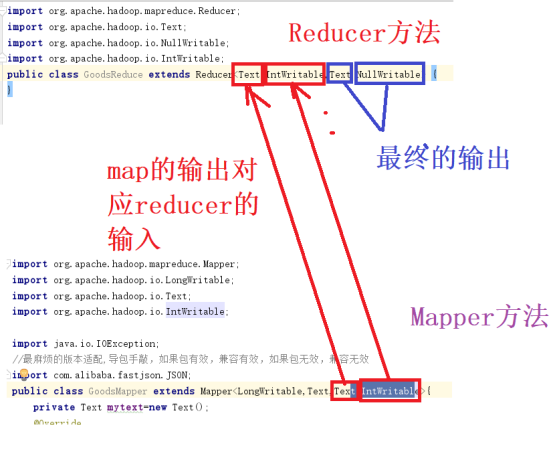
写reducer中的逻辑实现
首先重写reduce方法
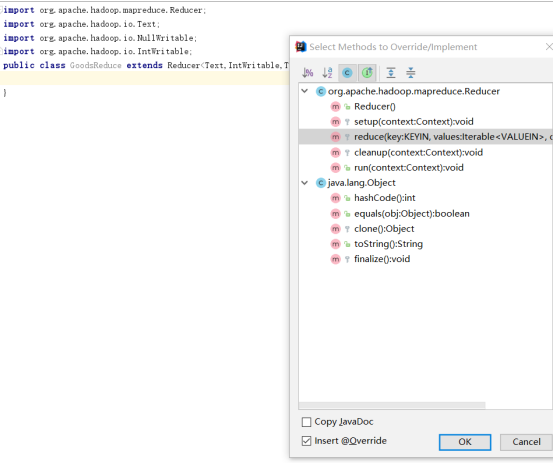
在reduce方法中不统计,直接输出。

下面写goodsJob,相当于调用mapreduce的主程序

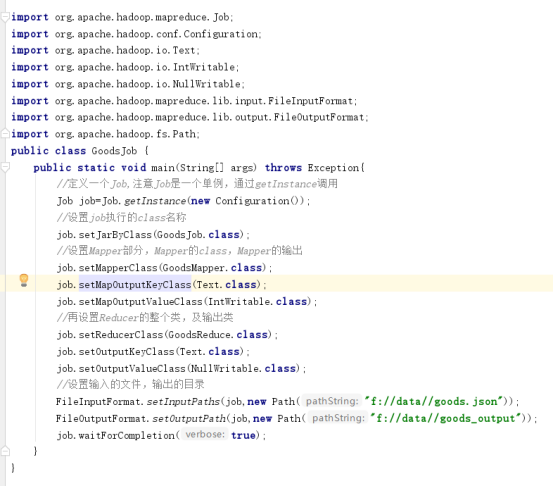
执行一遍,mapper输出的空是True还是false;
注意,执行时如果报错,可能是下列原因,一般情况下目录存在。
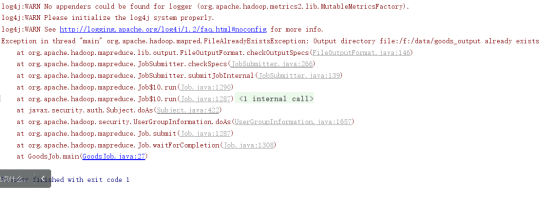
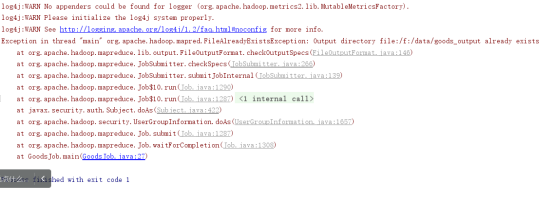
打印的信息如果显示

没有重写 toString()方法,重写 toString()
仔细找一下,有一个显示True的,

找到对应的输出方法

只有goods.getPublisher().length()==0是有true,其它空的都显示false,判断逻辑是有问题。
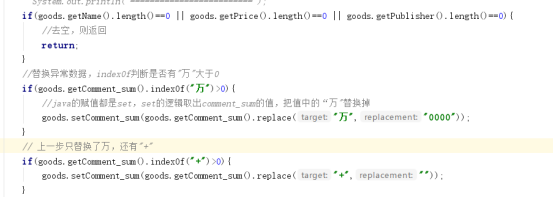
这样,就实现了mapreduce来使用去重去空去异常对 json数据进行清洗。
注意:麻烦的地方,在goodsBean里面一 定设置变量。
公司里面变化的数据,如果有20个维度,30个维度,Bean里面代码成倍增长。修改一个属性,比如原来是publisher,后来变成author,那会带来很大的麻烦。

这种尺度很难把握。引入lombok类。帮助我们产生getter, setter方法,还有构造器,toString()。
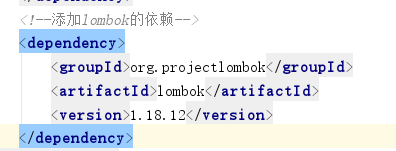
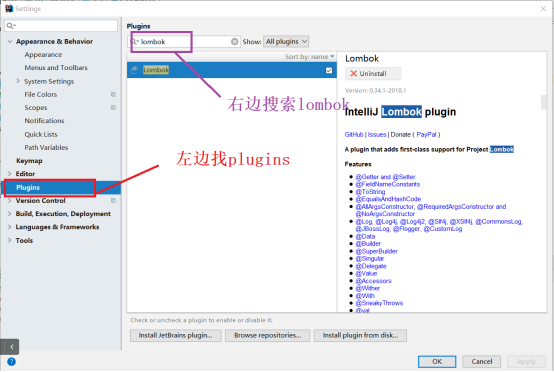
添加完这个依赖后,直接就把GoodsBean作修改。因为getter或者是setter会因为变量的变化而变化,这里引入lombok来解决这个问题,不过plugin中也需要安装插件。
在左边选择plugins,右边输入查询lombok
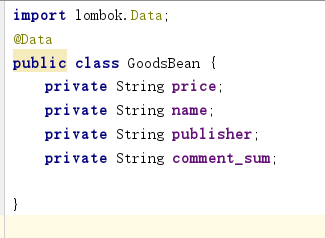
然后在Bean类中加入一个注解,注解就是lombok中的Data注解,注解帮助我们解决getter和setter及构造器。

这种类形的类,setter有了,getter有了,构造器有了,toString()方法也有了。

重写toString()方法,因为在mapper 里调用的toString()方法。

最后形成如下代码:

以上注意是采用把对象toString()变成文本,然后利用Text类型进行序列化的。
在百度上面搜索相关的Text序列化的清洗方法,会发现清洗方法是把对象实现WritableComparable接口。实现了看一下。

实现接口后,是红线,红线表示有些方法没有被重写。
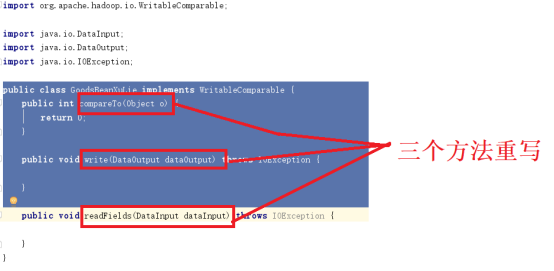
看一下介绍内容,每个维度都要写一遍
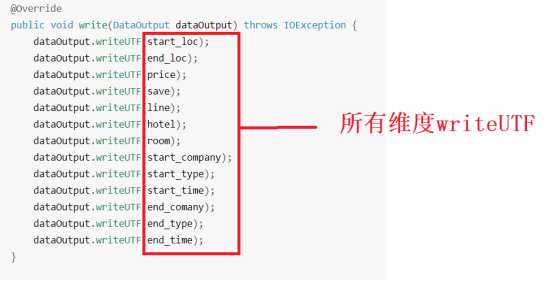
再看readFile方法
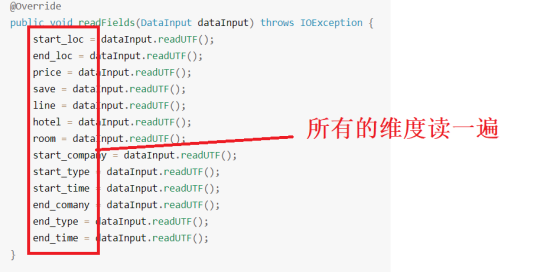
发现代码中getter和setter方法仍然有。
如果维度多,你就要一个一个write,然后再readFile。不利于代码维护,数据库的定义在项目初期考虑内容不全面,后期由于用户功能修改,添加维度,意味着模型要添加数据,大数据分析需求再修改,又会添加某些维度,添加维度后,json数据是永远的课题,使一个类简单的处理应付变化的需求,所以采用Text序列化一个Bean类。
实现这个接口WritableComparable,reduce的逻辑重新建立。
把javaBean实现序列化。
这里也需要getter和setter方法,建议使用lombok,lombok没有起到序列化的作用。

对Mapper进行修改。
首先对类型进行修改,因为GoodsBean已经序列化,不需要输出Text,需要输出GoodsBean;

第二因为GoodsBean已经序列,原来使用Text就可以去掉。
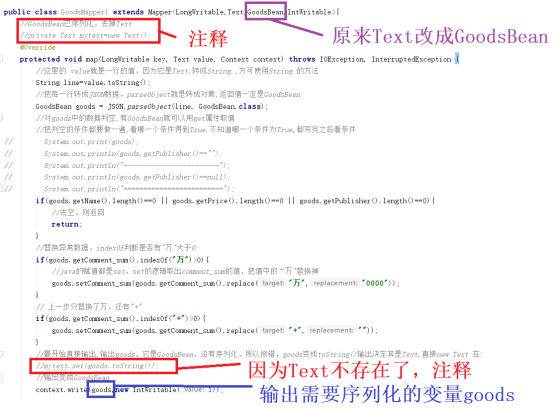
Reducer需要修改,同样修改类型,输入和输出都要修改类型。

对应最后的主程序也要修改。
运行之后看结果。

Java的MapReduce有错误,基本没有输出结果。

看运行结果没有错误显示,没执行,这里把GoodsBean换成GoodsBeanXuLie
Mapper方法中改动的地方

Reducer方法的改动的地方:
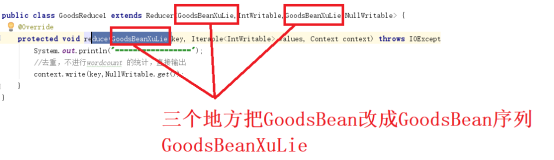
最后的Job需要改动的地方.

再执行一遍,看问题。
从结果上看,mapper都执行,查是打印==的reduce只有一行。
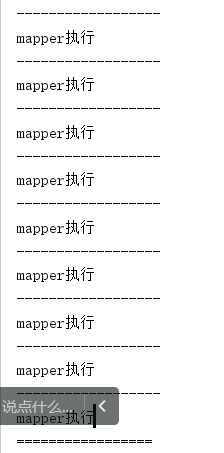
就是Reduce只执行了一次,需要执行多次,将所有map输出的values形成的叠代器遍历。去打印key值。

这种迭代没有去重。去重,计数式的统计。Reduce的逻辑复杂。
通过结果,看到结果还电带上了一对象名,也不是纯的json结果。还需要javabean重写toString()的方法。

继承的WritableComparable,必须重写write和readFile。同时还需要重写类中的toString()方法才能输出正确的json数据。这是实现WritableComparable接口实现的数据清洗序列化手段。