<点云>Bin-picking数据集

题目:工业料仓拣选的大规模6D物体姿态估计数据集
Abstract
- 介绍了一种新的公共数据集,用于6D对象姿态估计和用于工业bin-picking的实例分割。
- 数据集包括合成场景和真实场景。
- 对于这两者,提供了包括6D姿势 (位置和方向) 的点云、深度图像和注释、可见性分数(visibility score)和每个对象的分割蒙版(segmentation mask)。
- 除了原始数据外,还提出了一种精确注释真实场景的方法。
- 这是第一个用于6D对象姿势估计和实例分割的公共数据集,用于bin-pinging,其中包含足够的注释数据以进行基于学习的方法。
- 它通常是用于对象姿势估计的最大的公共数据集之一。该数据集可在http:// www.bin-picking.ai/en/ dataset.html上公开获得。
I. INTRODUCTION
- 从混乱填充的垃圾箱中抓取刚性物体的单个实例。
- 根据 [9] 中的实验,当前领先的方法基于点对特征,这与许多其他计算机视觉任务由基于深度学习的方法主导形成鲜明对比。
- 本文旨在支持机器学习方法,并在仓选场景中利用6D对象姿态估计。因此我们创建了一个新的大规模基准数据集,称为 “Fraunhofer IPA Bin-picking”数据集。
- 包括520完全注释的点云以及现实世界场景和关于206,000合成场景的相应深度图像。
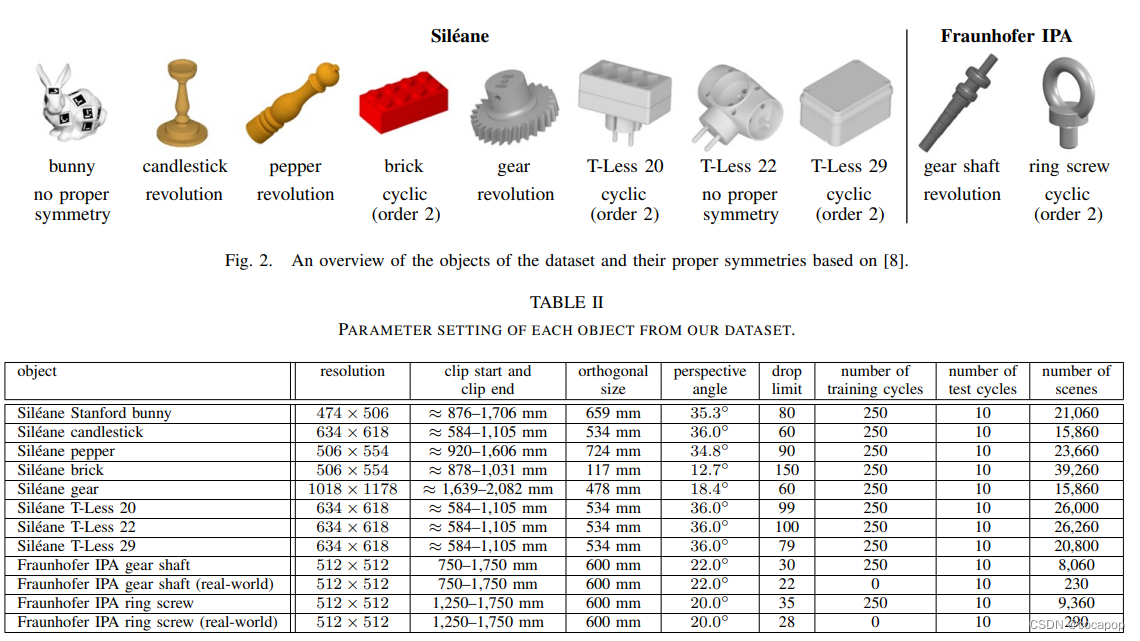
- 它包括来自 [8] 的八个对象以及两个新引入的对象。
- 合成数据包括用于训练的大约198,000带注释的场景和用于测试的8,000场景。
- 我们的贡献可以额外用于实例分割,并包含可见性分数
II. RELATED WORK
由于缺少地面真相信息,它们中的绝大多数不适用于机器学习方法进行6D物体姿态估计。
- Mian等人 [10] 为场景的点云提供了不同的对象,但这些对象既不包含大量的杂波,也不包含相同对象类型的多个实例。
- LINEMOD数据集 [5] 是一种流行且常用的基准测试,包含15个无纹理对象的约18,000个rgb-d图像。该作品通过 [11] 进行了增强,因此可以为图像中描绘的所有对象提供地面真实姿势。这使得能够考虑更高程度的遮挡以进行评估。
- 不同角度记录完全相同的场景的数据集 [12] 、 [13] 、 [6] 、 [14],有限的姿态可变性和数据冗余
- Doumanoglou等人 [14] 提供了同质的场景,就像在工业bin-picking中的情况一样,即,同一对象类型的多个实例存在于一个图像中。
- 在Rutgers APC数据集 [15] 中,引入了一个杂乱的仓库场景,该场景具有遮挡和24个对象的6,000个真实世界测试一下图像,但仅包括非刚性的纹理对象,并且它不是针对bin-picking的。
- T-Less [7] 数据集通过系统地采样一个球体,提供了30个工业纹理无对象的38,000个真实训练图像以及20个场景的10,000个测试一下图像。同样,它缺乏同质性,姿势可变性有限,并且表现出数据冗余。
由于注释过程耗时且困难,因此大多数方法都使用对象本身或相对于对象的标记来自动生成地面真实数据。同一场景被多次记录,导致数据冗余和不灵活。但是,在删除冗余场景后,数据集变得太小,无法适用于深度神经网络等机器学习方法。
- BOP [9] 试图将所呈现的数据集标准化并集成到一个新的基准中以进行6D对象姿态估计。此外,还包括两种具有不同照明条件的新方案,但这些方案与垃圾箱采摘无关。
- SIXD Challenge 2017,专注于一个对象的单个实例的6D对象姿态估计。
- Sil´eane数据集[8]提出了自动注释真实图像的过程。但是,该数据集最多提供一个对象的325图像,这通常不适合使用高级机器学习方法。
- Ours:将Sil´eane数据集扩展为足够大的基于学习的方法,并引入两个新的工业对象以及实际数据。
III. FRAUNHOFER IPA BIN-PICKING DATASET 弗劳恩霍夫IPA垃圾箱采摘数据集
A. Sensor Setup A.传感器设置
- 使用Ensenso N201202-16-BL立体摄像机收集了真实世界的数据。
- 该摄像机的最小工作距离为1,000毫米,最大工作距离为2,400毫米,最佳工作距离为1,400毫米。
- 传感器产生具有1280 × 1024像素分辨率的图像,并安装在箱上方。
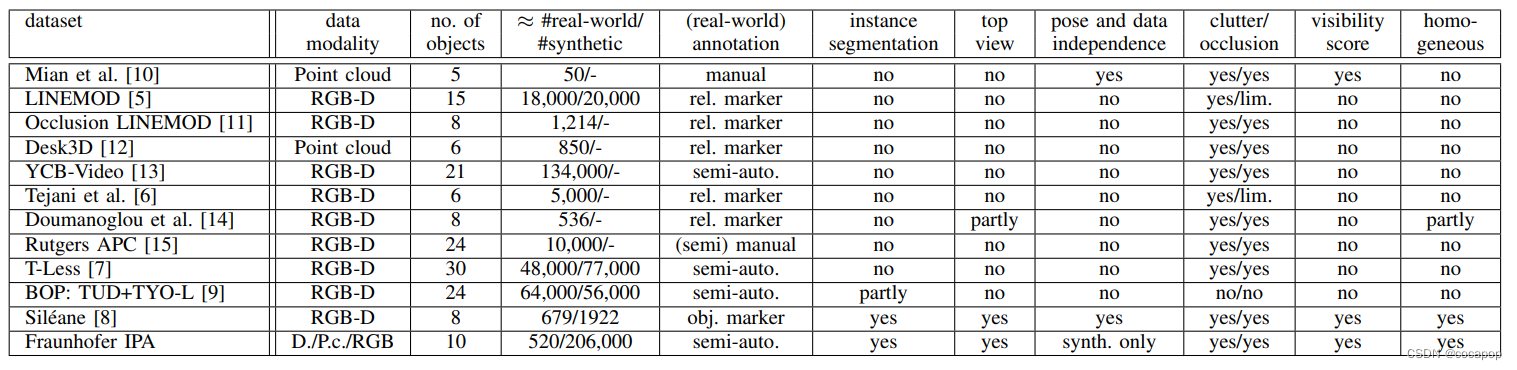
- 对于合成数据的收集,我们在物理模拟中使用与 [8] 中相同的参数设置。在表II中列出了剪切平面的每个对象的详细设置,透视投影的视角,正交投影的正交尺寸以及图像分辨率。
B. Dataset Description B.数据集描述
- 我们使用 [8] 中具有不同对称性的八个对象,它再次使用了最初由 [7] 发布的三个对象。
- 此外,我们介绍了两个新颖的工业目标: 具有旋转对称性的齿轮轴和具有循环对称性的环形螺钉。
- 地面真实数据包括相对于3D传感器的坐标系的平移向量t和旋转矩阵R,可见性分数v ∈ [0,1] 以及由对象ID标记的分割图像,用于透视和正交投影。
C. Data Collection Procedure C.数据收集程序
1) 合成数据:
- 要生成典型的binping场景,我们使用物理模拟V-REP [19]。在仿真中导入每个对象的CAD模型,并将它们从不同的位置以随机的方向放入箱中 (见图3)。
- 为了处理动力学和碰撞,我们使用内置的子弹物理引擎2。
- 为了增加新引入的对象的真实感,我们将bin姿势从图像稍微转移到图像,而 [8] 中的对象设置保持不变。
- 深度图像以16位无符号整数格式 (uint16) 保存。通过将相应对象的ID分配给每个像素来创建分割图像,即,对于bin为0,对于第一对象为1等。
- 如果像素属于背景,则分配uint8的最大值255。
- 对于每个项目,我们保存仅包含单个对象的分割图像,以便计算形成该对象的像素总数。
- 对于该单对象图像,所有其他对象均不可见。
- 最终可见性分数由分割图像中的可见像素与像素总数之间的比率从外部计算。
2)真实数据
IV. EVALUATION 四.评价
除数据集外,我们还提供CAD模型,Python工具,以满足点云,深度图像或地面真相文件和脚本的各种转换需求,以方便使用我们的数据集。如 [20] 所示,我们的合成数据集以及域随机化 [17] 可用于在我们的真实场景中获得稳健且准确的6D姿势估计。通过在训练过程中对合成图像应用各种增强功能,深度神经网络尽管完全在合成数据上进行了训练,但仍能够推广到实际数据。
A. Evaluation Metric A. Evaluation Metric
- Hinterstoisser等人 [5] 添加了一个用于6D物体姿态估计的通用评估度量,如果地面真相和估计姿态之间的模型点的平均距离小于物体最小边界球直径的0.1倍,则接受姿态假设。
- 由于此指标无法处理对称对象,因此引入了ADI [5] 来处理这些对象。ADI度量被广泛使用,但不能拒绝误报在 [8] 中。
- 因此,我们使用Br´egier等人 [21],[8] 提供的度量,该度量适用于刚性物体,用于许多部分的场景,并适当地考虑了循环和旋转物体的对称性。
- 如果到地面真相的最小距离小于物体直径的0.1倍,则姿势假设被接受 (被认为是真阳性)。
- 在 [8] 之后,只有小于50% 遮挡的物体的姿态与检索有关。该指标通过在精度-召回曲线下取面积,将方法的性能分解为一个名为平均精度 (AP) 的标量值。
B. Object Pose Estimation Challenge for Bin-Picking B.装箱拾取的物体姿态估计挑战