Attention is all your need——Transformer论文

摘要
此序列转录模型仅仅依赖于注意力机制,而不使用循环或者是卷积,将循环全部换成了multi-headed self- attention
介绍
RNN的特点、并行程度低。
Attention在RNN上的应用。
引入注意力机制,提高并行度。
背景
使用卷积对长的序列难以建模,因为卷积计算的时候一次只能看一个比较小的窗口,如果隔的很远需要很多层卷积一层一层上去才能把隔的远的像素融合起来。如果使用transformer的注意力,一层就能够把整个序列看到。卷积可以做多个输出通道,一个输出通道可以去识别不一样的模式,transformer也想这样多输出通道的效果所以提出一个Muti- Headed Attention,可以模拟卷积神经网络多输出通道的效果。
自注意力机制
Model
编码器:会将输入,就是一个长为n的输入(x1.....xn)xt表示第t个词,编码器会把它表示成一个长为n的向量Z,zt是对应的xt的一个向量表示。
解码器:拿到编码器的输出,生成一个长为m的序列(如果英文翻译成中文两个句子可能是不一样长的,这时n!=m),在解码器中词是一个一个生成的。因为编码器是一次性看整个句子,但是解码器是一个一个生成,叫自回归auto-regressivet。根据最开始给定的z,生成y1,有了y1之后再生成y2。生成yt要把y1~yt-1全部拿到。就是在翻译的时候是一个词一个词蹦。过去时刻的输出也是当前时刻的输入(自回归)
transformer使用的就是编码器解码器的结构

左边一块是编码器右边一块是解码器,shifted right就是一个一个往右输出
![]() 就是变成一个一个向量,
就是变成一个一个向量,![]() 就是n个层摞在一起,
就是n个层摞在一起,![]() 前馈神经网络
前馈神经网络
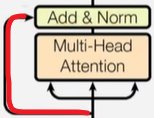 残差连接
残差连接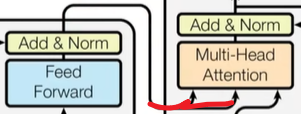 编码器的输出最为解码器的输入从这里进去
编码器的输出最为解码器的输入从这里进去
编码器:使用了N=6个完全一样的层 因为是残差连接所以将输入和输出加在一起,输出维度都是512,使模型简单,所以目前只有2个参数,N和维度,调参只需要调这两个就行了。
LayerNorm:变长的应用里不使用batchnorm而使用LayerNorm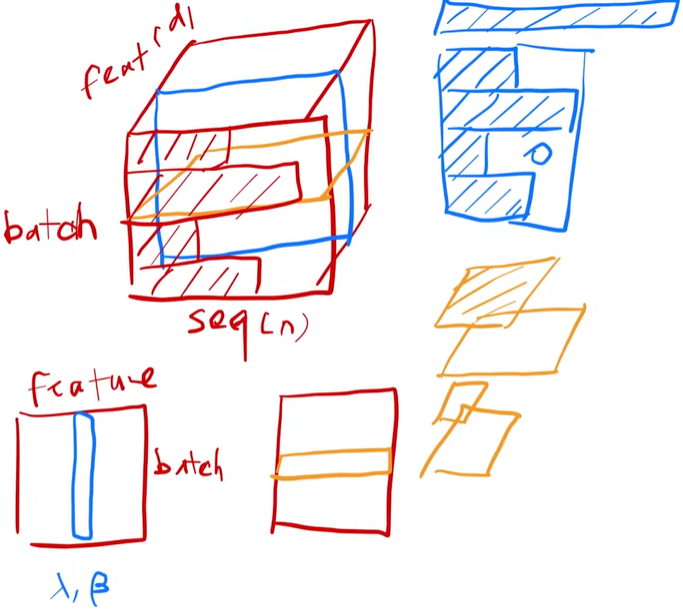
解码器:带掩码的注意力机制,因为输入的时候不能让他看到后面没有输入的东西,保证训练和预测的时候行为是一致的
注意力
注意力函数是一个将一个query 和一些 key-value对映射成一个输出的函数,output是value的加权和,所以输出的维度和value的维度是一样的。每个value的权重是value对应的key和查询的query的相似度
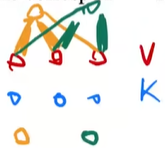
transformer中的注意力叫scaled dot-product attention
query和key的长度是等长的都等于dk,value是dv所以输出也是dv,对query和每一个key做内积,softmax得到权重作用到value上就可以得到输出
 蓝色query对所有key的一个内积值,再除以
蓝色query对所有key的一个内积值,再除以![]() ,再对每一行进行softmax,每一行之间是独立的,得到了权重然后再乘以V
,再对每一行进行softmax,每一行之间是独立的,得到了权重然后再乘以V
mask
将t之后的换成一个大的负数 ,大的负数做softmax运算的时候会变成0,所以权重都会变成0
Multi-Head Attention

Position-wise Feed-Forward Networks
最后一次的MLP其实就是2个线性层,MLP在独立的点独立做就行了,因为已经经过了注意力机制。