【数据结构】Map、Set和哈希表的练习

目录
前言
1、只出现一次的数字
2、复制带随机指针的链表
3、宝石和石头
4、坏键盘打字
5、前K个高频单词【难】
前言
- Map和Set是两个接口类型,他们要实例化,得借助具体的类来实现,继承Map的类有TreeMap和HashMap;继承Set的类有TreeSet和HashSet两个类。
- TreeMap和TreeSet它的底层实现是二叉搜索数(红黑树)。
- HashMap和HashSet它们的底层实现是Hash表。
- 二叉搜索树的插入、删除操作,他们的时间复杂度为树的高度O(logN).
- Hash表的的各种操作时间复杂度为O(1),虽然说哈希表在冲突的位置是单链表的结构或者是红黑树的结构,但是我们认为他们是可数的。因为在哈希表当中有负载因子的控制,在Java当中负载因子大于0.75的时候,Hash表会扩容。所以红黑树的高度不会太高。
- 继承Set接口的类当中,当数据有重复的时,第二次出现的数据不会进入。Set具有去重的效果
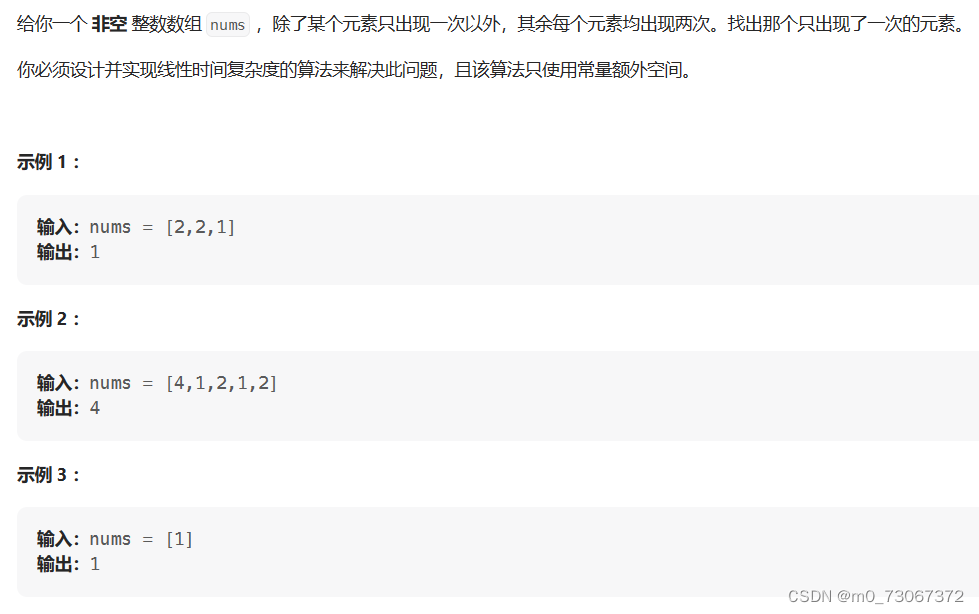
1、只出现一次的数字
【题目要求】
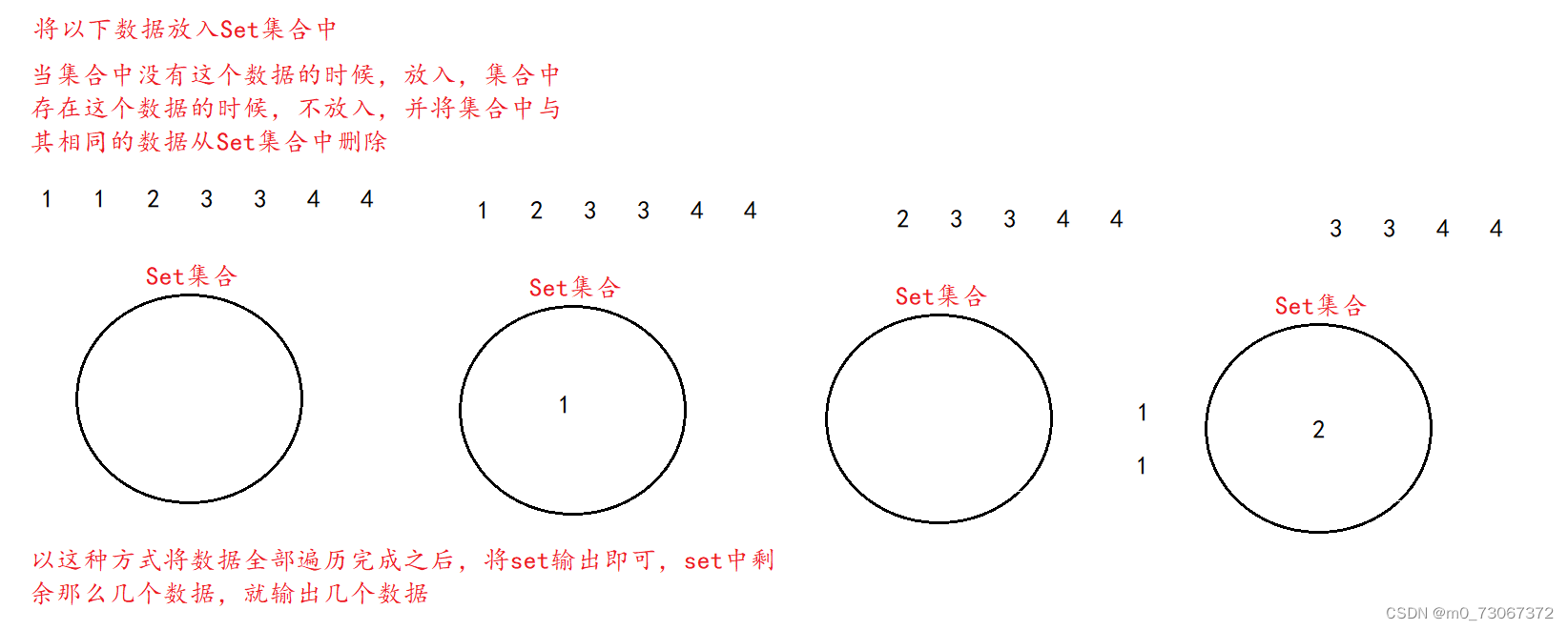
【 思路分析】
【代码示例】
public int singleNumber(int[] array){Set<Integer> set = new HashSet<>();//创建一个HashSet对象for (int i = 0; i < array.length; i++) {//遍历数组中的元素if(!set.contains(array[i])){//set对象中是否存在i下标的数据set.add(array[i]);//不存在,将i下标的数据放入set对象中}else{//如果存在,则将set对象中与i下标数据相同的数据,移出set对象set.remove(array[i]);}}for (int i = 0; i < array.length; i++) {//再遍历一遍数组if(!set.contains(array[i])){//数组当中存在与set对象当中一致的数据,则将这个数据返回return array[i];}}return -1;//如果没有则返回-1}
【写死的代码示例】
public static void main(String[] args) {int[] array = {1,1,2,3,4,4,5,5,6,6};Set<Integer> set = new HashSet<>();//创建一个HashSet对象for (int i = 0; i < array.length; i++) {//遍历数组中的元素if(!set.contains(array[i])){//set对象中是否存在i下标的数据set.add(array[i]);//不存在,将i下标的数据放入set对象中}else{//如果存在,则将set对象中与i下标数据相同的数据,移出set对象set.remove(array[i]);}}System.out.println(set);//可以将set对象传给输出方法,当set当中有几个元素,就会输出几个元素}2、复制带随机指针的链表
【题目要求】
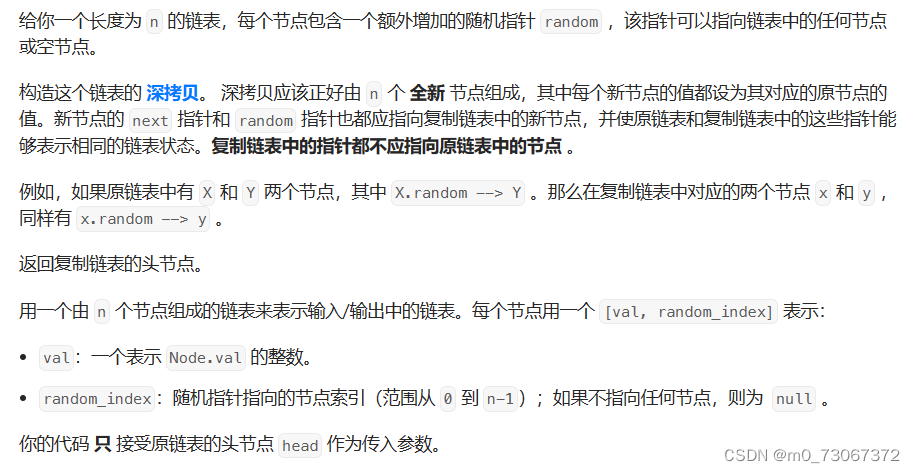
【示例】
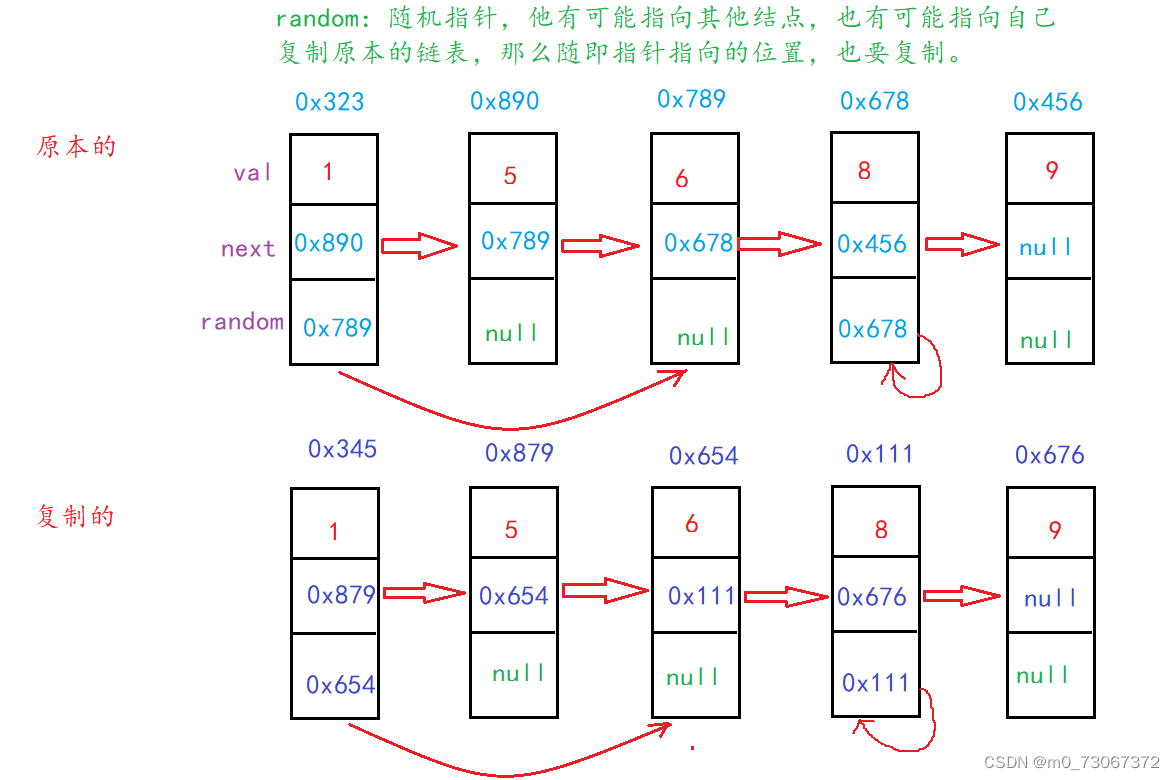
【思路分析】
- 这道题我们使用HashMap来实现。
- 我们创建一个cur遍历原本的链表。
- 每遍历一个原本链表的一个结点,创建一个新的结点。
- 将cur遍历到的结点的地址和新节点的地址放入Hash表,Hash表中key放cur所在结点的地址,value中存放新节点的地址。这样新链表和旧链表就产生了联系。通过这样的方式将原本链表遍历完。新链表会形成和旧链表相同的结点数。
- 再将原本链表遍历一遍,将cur结点所对应的新节点的地址用get(cur)方法得到。
- 新节点的地址得到之后,新节点要连接下一个结点,所以新节点的next域为原本链表的cur结点的next域中地址所对应新节点的地址【map.get(cur).next = map.get(cur.next)】
- 新节点的random域,等于cur结点的random域中地址(key)所对应的value(也就是新节点random域中地址)【map.get(cur).random = map.get(cur.random)】
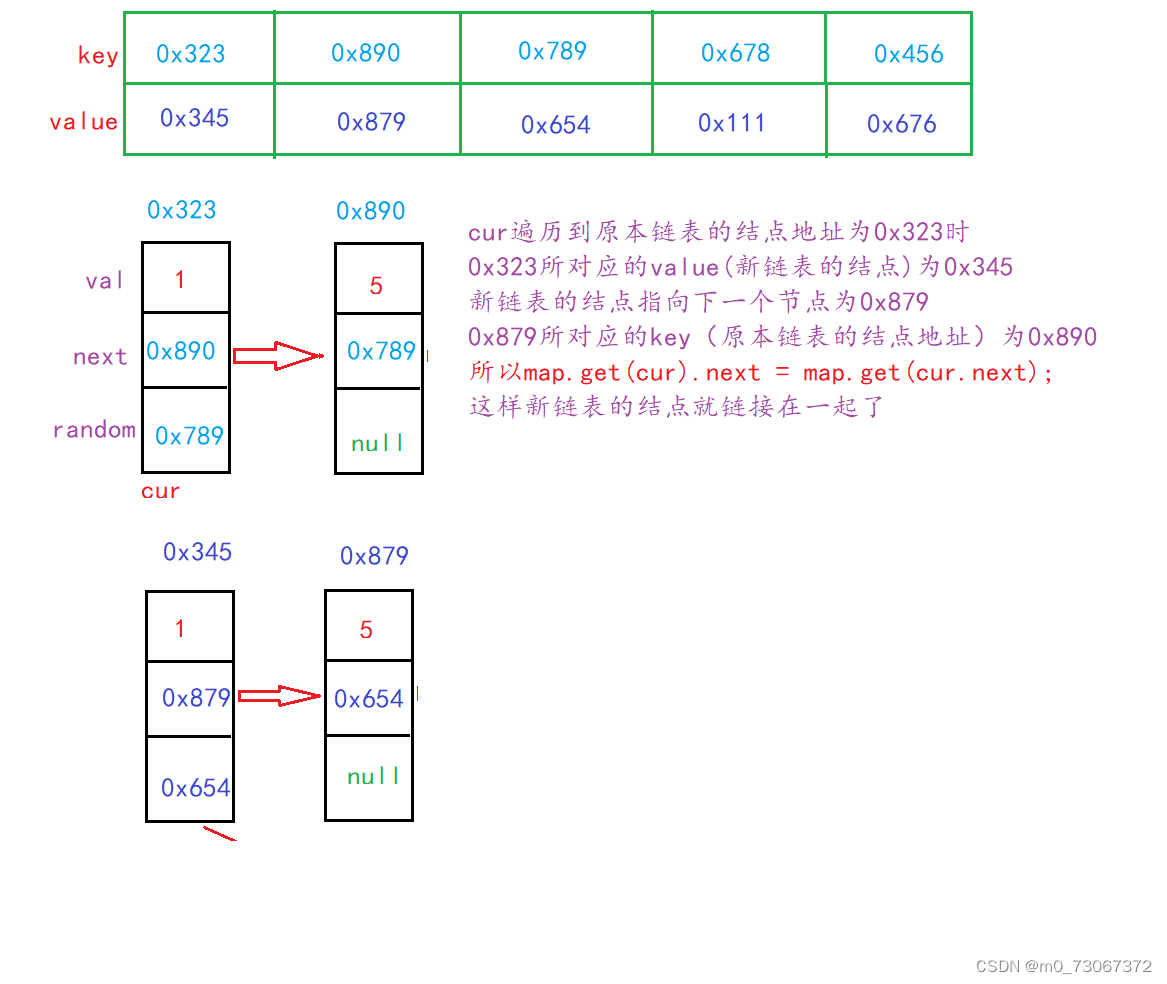
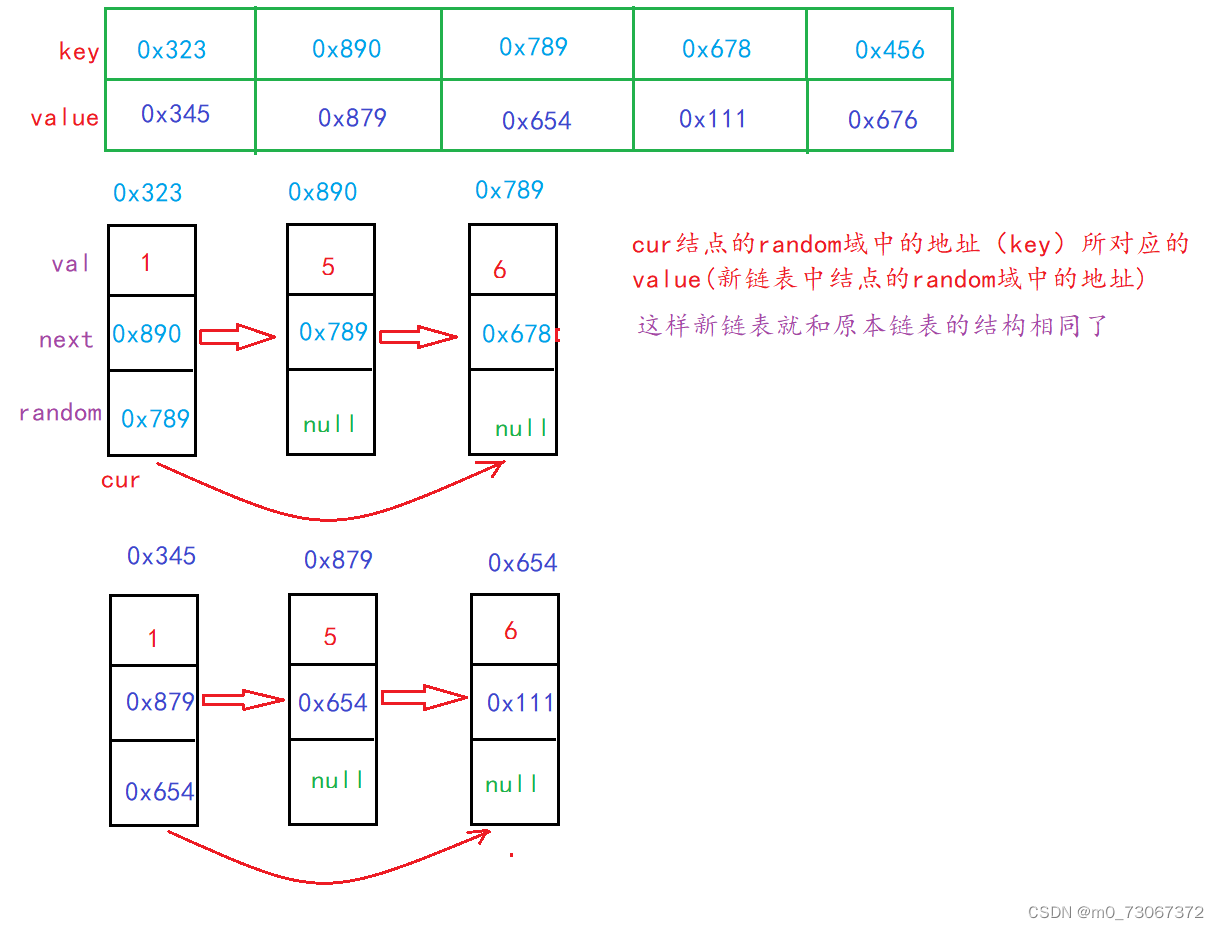
【代码示例】
class Node {int val;Node next;Node random;public Node(int val) {this.val = val;this.next = null;this.random = null;}public Node copyRandomList(Node head){Map<Node,Node> map = new HashMap<>();//定义一个HashMap的对象使用K-V模型Node cur = head;//定义cur指向head,从头节点开始遍历链表while(cur != null){//cur没有将链表遍历完,进入循环Node node = new Node(cur.val);//创建新节点,用来复制原本的结点,将cur结点的值,给新节点map.put(cur,node);//将cur作为key,node作为value放进map对象中。cur = cur.next;//cur向后遍历}cur = head;//将链表遍历完成之后,回到链表的头节点位置while(cur != null){//get返回cur结点对应的value(新节点的地址)map.get(cur).next = map.get(cur.next);//新节点的next域等于cur结点的next域地址所对应的value值map.get(cur).random = map.get(cur.random);//random域同理cur = cur.next;//cur向后遍历}return map.get(head);//返回新链表的头节点(原本链表的头节点(key)所对应的value值)}
}3、宝石和石头
【题目要求】

【思路理解】
- 这道题使用Set,因为这里不存在建立对应位置的键值对。
- 将宝石中的字符放入set中。
- 然后使用石头中的字符进行对比,如果set中存在该字符,则+1,如果不存在,则向后遍历。
【代码示例】
public int numJewelsInStones(String jewels,String stones){int count = 0;Set<Character> set = new HashSet<>();//遍历宝石,将宝石中的字符放入set中for (int i = 0; i < jewels.length(); i++) {char ch = jewels.charAt(i);//charAt()方法是将索引处的值返回set.add(ch);}//遍历石头,将石头中的字符域set中的字符进行对比,存在相同的字符+1for (int i = 0; i < stones.length(); i++) {char ch = stones.charAt(i);if(set.contains(i)){count++; }}return count;//返回石头中存在的宝石个数}4、坏键盘打字
【题目要求】
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出肯定坏掉的那些键。
输入描述
输入在2行中分别给出应该输入的文字、以及实际被输入的文字。每段文字是不超过80个字符的串,由字母A-Z(包括大、小写)、数字0-9、 以及下划线“_”(代表空格)组成。题目保证2个字符串均非空。
输出描述
按照发现顺序,在一行中输出坏掉的键。其中英文字母只输出大写,每个坏键只输出一次。题目保证至少有1个坏键。
【示例】
7_This_is_a_test :目标输入
_hs_s_a_es :实际输入
输出结果:坏了的键 7TI
【思路理解】
- 首先将实际输入的字符串(str1)中的字符放入到Set中,在放入的过程中,将str1字符串中的所有字母转化为大写并将字符串转化为字符类想的数组。
- 创建一个setBroken对象,用来存放坏键(目标字符串当中的字符与set当中的字符进行对比,set当中没有的字符并且setBroken当中没有的字符放入setBroken中)。每个坏了的键在输出结果中只出现一次。所以setBroken当中存在的字符,不会再放入Set当中。
【代码示例】
public static void main(String[] args) {Scanner scan = new Scanner(System.in);while (scan.hasNextLine()) {String str1 = scan.nextLine();String str2 = scan.nextLine();func2(str1, str2);}}public static void func2(String str1, String str2) {Set<Character> set = new HashSet<>();//先定义一个set用来存放实际输入的字符//toUpperCase()用来将小写字母转化位大写字母,toCharArray()用来将字符转化位字符类型的数组for (char ch : str2.toUpperCase().toCharArray()) {//char ch表示的意思是数组当中的元素是char类型的set.add(ch);//将数组元素ch中的字符放入set中}Set<Character> setBroken = new HashSet<>();//再创建一个setBroken,用来将坏了的键放入其中//在遍历的同时将,字符串转化为数组,并且数组当中的元素为大写for (char ch:str1.toUpperCase().toCharArray()){//遍历目标输入的数组//将目标字符串中遍历到的字符与set当中的元素进行对比,如果set中没有,则将这个字符放入setBroken对象当中,并且当setBroken当中有相同的字符时,if(!set.contains(ch)&&!setBroken.contains(ch)){//不会将set中没有的字符放入setBroken中setBroken.add(ch);System.out.print(ch);//每放入一个,输出一个字符}}}5、前K个高频单词【难】
【题目要求】

【题目分析】
1、上述题目中说返回前K个出现次数最多的单词。这里就是一个TOP-K问题。
TOP-K问题:
- 返回前k个最大的数据,则是建立小根堆。 将一组数据的前k个先建成小根堆,然后用这组数据当中的剩余元素依次与它的堆顶元素进行比较,比堆顶元素大,先将堆顶元素弹出,再将这个元素放入堆中,这样依次比较完成之后,就会将这组数据当中前k个最大的元素找出。
- 返回前k个最小的数据,则是建立大根堆。 将元素与堆顶元素进行比较,比堆顶元素小的放入堆中(大根堆中堆顶元素是k个元素当中最大的),依次将剩余元素与堆顶元素进行比较之后,堆中放入的元素就是前k个最小的数据。
2、上述题目中说到返回的答案按照出现频率由高到低排序。
- 这里就需要我们将堆中的数据,放入到一个集合当中(List),将集合当中的元素顺序翻转。这样就可以达到效果
3、上述中还说到如果不同的单词出现相同的频率,按字典序顺序排序。
- 这里就涉及到了比较器的问题。 在创建小根堆的时候,通过匿名内部类实现一个外部比较器。 当然比较器要设计两种,当按频率比较是,两个不同的单词具有相同的频率的时候,就需要按照字典序比较。
【代码示例】
public static List<String> topKFrequent(String[] words,int k){//1、遍历数组 统计每个单词出现的频率Map<String,Integer> hashMap = new HashMap<>();for (String s:words) {if (hashMap.get(s) == null){//这里得到的S元素的Value值为引用类型的数据,所以不能将其于0作比较,只能于null作比较。hashMap.put(s,1);}else{hashMap.put(s,hashMap.get(s)+1);}}//建立小根堆 并提供比较器 PriorityQueue默认创建的是小根堆PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(k, new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {if(o1.getValue().compareTo(o2.getValue()) == 0){return o2.getKey().compareTo(o1.getKey());}return o1.getValue().compareTo(o2.getValue()) ;}});//3、遍历hashMap 把里面的数据放到小根堆for (Map.Entry<String,Integer> entry:hashMap.entrySet()) {if(minHeap.size() < k){//小根堆当中的元素个数小于k时,将Set当中的元素放入minHeap当中。minHeap.offer(entry);}else{//小根堆放满k个, 下一个entry和堆顶元素比较Map.Entry<String,Integer> top = minHeap.peek();//堆顶的频率小于当前entry的频率 就出堆 然后入队entryif(top.getValue().compareTo(entry.getValue()) < 0){minHeap.poll();minHeap.add(entry);}else{//堆顶的频率大于等于当前entry频率的时候//频率相同的情况if(top.getValue().compareTo(entry.getValue()) == 0){if (top.getKey().compareTo(entry.getKey()) > 0){//如果entry元素的键(key)小于堆顶元素的键(key),则将堆顶的元素弹出,将entry放入堆中minHeap.poll();minHeap.add(entry);}}}}}//4、此时小根堆当中一定有了结果List<String> ret = new ArrayList<>();for (int i = 0; i < k; i++) {String key = minHeap.poll().getKey();ret.add(key);}Collections.reverse(ret);//将ret中的结果逆置return ret;}
【代码理解】
1、创建小根堆
创建一个k个结点大小的小根堆,小根堆的结点类型是Map.Entry<String,Integer>类型。通过外部比较器,对堆当中的结点进行比较。第一种比较器,根据数据的频率进行比较。第二种比较器根据数据的大小(字符的字典序)进行比较。
当两个单词出现的频率不同的时候,用单词出现的频率进行比较,当两个不同的单词出现的频率相同的时候,则使用字符的比较器进行比较。
//创建一个k个结点的小根堆 PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>( //创建一个匿名内部类,实现一个外部比较器k, new Comparator<Map.Entry<String, Integer>>() { //重写compare比较方法,比较的对象类型是Map.Entry<String,Integer>类型@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {if(o1.getValue().compareTo(o2.getValue()) == 0){return o2.getKey().compareTo(o1.getKey());}return o1.getValue().compareTo(o2.getValue()) ;}});2、这句代码的意思是:通过foreach对Set集合进行遍历。
hashMap.entrySet(),调用hashMap中的entrySet()方法,这个方法的返回值是Set<Map.Entry<K,V>>,相当于将每个hashMap类型的结点作为元素放入Set集合当中。
遍历的Set集合当中的结点(entry)类型为Map.Entry<String,Integer>.
这步操作是将Set当中的前K个元素,放入到小根堆当中。
for (Map.Entry<String,Integer> entry:hashMap.entrySet())3、逆置List集合当中的元素
堆当中放入一组单词的当中频率最高的k个元素都在小根堆当中。题目要求只输出单词,并没有要求输出单词出现的频率。所以我们将小根堆当中的元素放入List集合当中,在List集合当中,数据还是按照频率的从小到大存放的,题目要求按照从大到小输出,所以这里我们使用Collections接口的reserve方法将List当中的元素逆置。
List<String> ret = new ArrayList<>();for (int i = 0; i < k; i++) {String key = minHeap.poll().getKey();ret.add(key);}Collections.reverse(ret);//将ret中的结果逆置return ret;