C语言数据结构初阶(11)----堆

· CSDN的uu们,大家好。这里是C语言数据结构的第十讲。
· 目标:前路坎坷,披荆斩棘,扶摇直上。
· 博客主页: @姬如祎
· 收录专栏: 数据结构与算法

目录
编辑
1. 堆的概念及性质
2. 函数接口一览
3. 函数接口的实现
3.1 void HeapInit(Heap* pHeap) 的实现
3.2 void HeapDestroy(Heap* pHeap) 的实现
3.3 bool HeapEmpty(Heap* pHeap) 的实现
3.4 void HeapPush(Heap* pHeap, HeapDataType x) 的实现
3.5 void HeapPop(Heap* pHeap) 的实现
3.6 HeapDataType HeapTop(Heap* pHeap) 的实现
3.7 int HeapSize(Heap* pHeap) 的实现
4. 堆的应用
4.1 Top-K问题
4.2 堆排序
1. 堆的概念及性质

堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为:大顶堆(大根堆,大堆)(左图);或者每个节点的值都小于或等于其左右孩子节点的值,称为小顶堆(小根堆,小堆)(右图)。

堆的逻辑结构是一棵完全二叉树,但是他的物理结构是内存空间连续的数组。
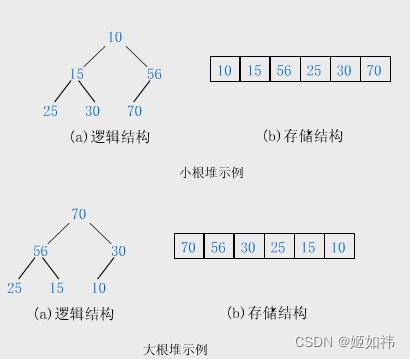
根据堆这种数据结构的存储结构,我们可以得出父节点与左右孩子之间的下标关系:
先看公式: parent = (child - 1) / 2 (这里的除法为整除) ;
leftchild = parent * 2 + 1 ;
rightchild = parent * 2 + 2 ;
rightchild = leftchild + 1;
如果有不理解的地方,可以画图举例哦!
我们可以看到 70 这个节点的下标为 0,根据公式:他的左孩子的下标应该为:0 * 2 + 1 = 1
依次类推哈。
下面是一些有关堆的基础知识的选择题,加深大家对堆这种数据结构的理解。
1.下列关键字序列为堆的是:()
A 100,60,70,50,32,65
B 60,70,65,50,32,100
C 65,100,70,32,50,60
D 70,65,100,32,50,60
E 32,50,100,70,65,60
F 50,100,70,65,60,32
2.已知小根堆为8,15,10,21,34,16,12,删除关键字 8 之后需重建堆,在此过程中,关键字之间的比较次
数是()。
A:1
B:2
C:3
D:4
3.一组记录排序码为(5 11 7 2 3 17),则利用堆排序方法建立的初始堆为
A:(11 5 7 2 3 17)
B:(11 5 7 2 17 3)
C:(17 11 7 2 3 5)
D:(17 11 7 5 3 2)
E:(17 7 11 3 5 2)
F:(17 7 11 3 2 5)
4.最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A:[3,2,5,7,4,6,8]
B:[2,3,5,7,4,6,8]
C:[2,3,4,5,7,8,6]
D:[2,3,4,5,6,7,8]答案:
1.A
2.C
3.C
4.C
2. 函数接口一览
堆的实现与顺序表的实现差不多,只是增删改查的逻辑不同。这里的实现是以构建大堆为准的哦!
这一点请牢记,非常重要!!!
typedef int HeapDataType;
typedef struct Heap
{HeapDataType* a;int size;int capacity;} Heap;//堆的初始化
void HeapInit(Heap* pHeap);//堆的销毁
void HeapDestroy(Heap* pHeap);//堆插入数据
void HeapPush(Heap* pHeap, HeapDataType x);//堆删除数据
void HeapPop(Heap* pHeap);//查看堆顶的数据
HeapDataType HeapTop(Heap* pHeap);//判断堆是否为空
bool HeapEmpty(Heap* pHeap);//堆的大小
int HeapSize(Heap* pHeap);3. 函数接口的实现
3.1 void HeapInit(Heap* pHeap) 的实现
该函数用于初始化堆,为堆的实现的数组分配内存空间,并初始化一些变量。我们初始为数组分配四个整型的空间,如果空间不够了,我们再选择扩容。扩容的大小为原 capacity 的两倍。
//堆的初始化
void HeapInit(Heap* pHeap)
{assert(pHeap);HeapDataType* tmp = (HeapDataType*)malloc(sizeof(HeapDataType) * 4);if (tmp == NULL){perror("HeapInit::malloc");exit(-1);}else{pHeap->a = tmp;pHeap->capacity = 4;pHeap->size = 0;}
}3.2 void HeapDestroy(Heap* pHeap) 的实现
这个函数用于销毁我们在内存的堆区上申请的空间,即堆的实现所需的数组。
//堆的销毁
void HeapDestroy(Heap* pHeap)
{assert(pHeap);free(pHeap->a);pHeap->a = NULL;
}3.3 bool HeapEmpty(Heap* pHeap) 的实现
这个函数用来判断堆是否为空。注意到我们的 Heap 结构体中维护了 size 这个变量。因此我们只需要判断 size 是否为 0 即可。
//判断堆是否为空
bool HeapEmpty(Heap* pHeap)
{assert(pHeap);return pHeap->size == 0;
}3.4 void HeapPush(Heap* pHeap, HeapDataType x) 的实现
这个函数用于向堆中插入数据。插入数据的逻辑是:向数组的末尾插入数据,然后用向上调整的算法将整个数组重新调整为堆。
如下图:我们在 [ 70, 56, 30, 25, 15, 10 ] 的大堆中插入 90 这个元素。
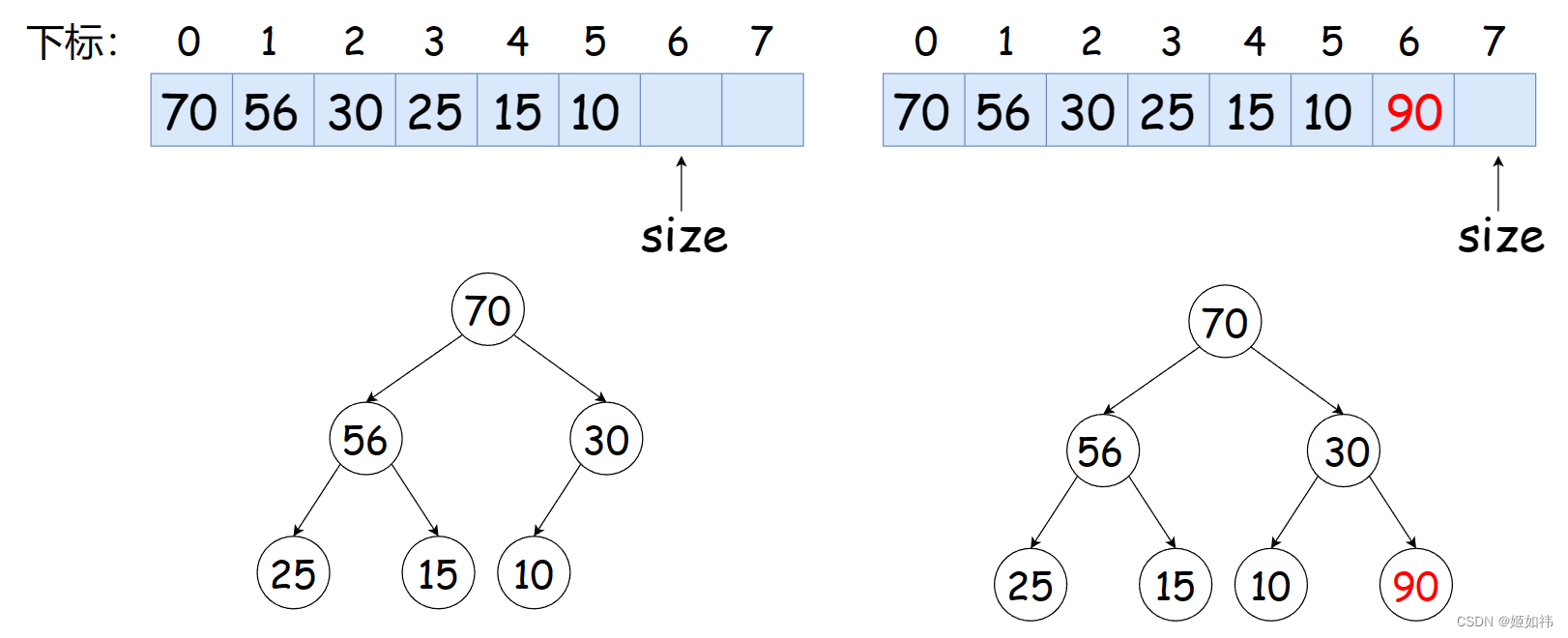
向上调整的步骤为:将插入元素与他的父节点进行比较,如果插入的元素大于父节点交换两个元素,直到与根结点完成比较,或者插入的元素小于他的父节点,退出循环。
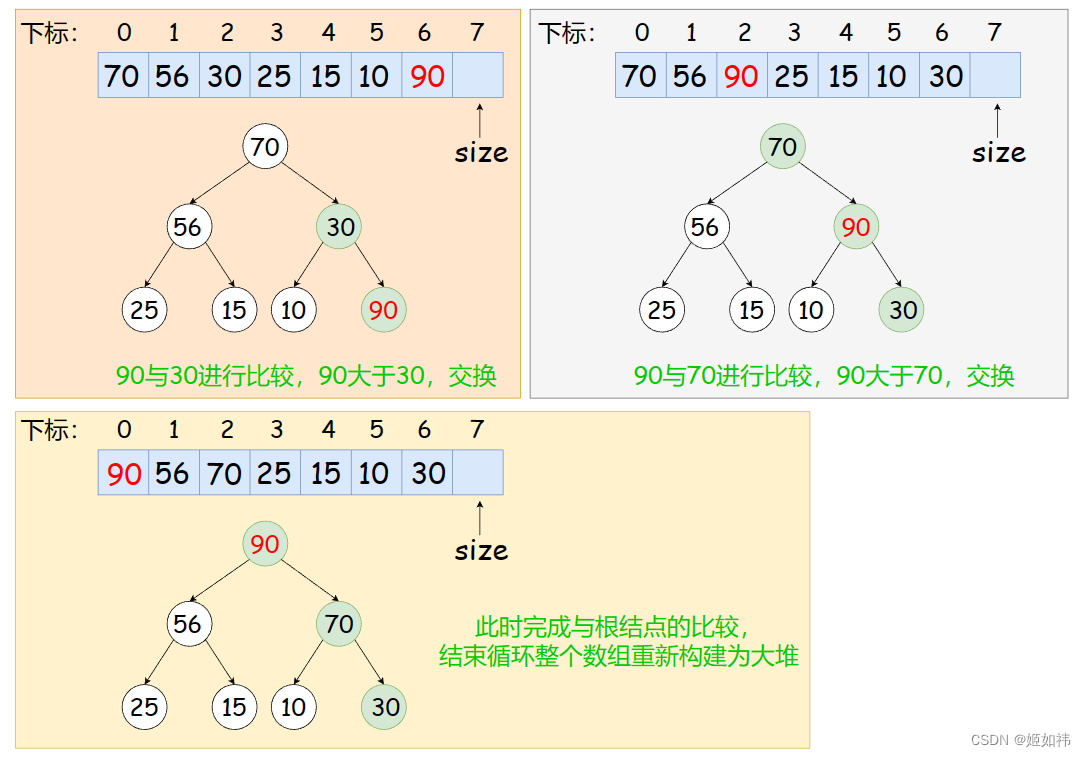
还有一点值得注意的是:插入数据时我们首先得判断堆的大小与容量之间的关系,如果堆满了,需要扩容。
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//向上调整,child表示要向上调整的元素的下标
void AdjustUp(int* a, int child)
{//根据公式找到父节点下标int parent = (child - 1) / 2;//child == 0 表明已经与根结点完成比较,所以循环条件为child > 0while (child > 0){//如果插入的元素大于父节点,交换if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else //否则的话,退出循环,完成建大堆{break;}}
}//堆插入数据
void HeapPush(Heap* pHeap, HeapDataType x)
{assert(pHeap);//堆是否满了if (pHeap->size == pHeap->capacity){HeapDataType* tmp = (HeapDataType*)realloc(pHeap->a, sizeof(HeapDataType) * pHeap->capacity * 2);if (tmp == NULL){perror("HeapPush::realloc");exit(-1);}else{pHeap->a = tmp;pHeap->capacity *= 2;}}//向数组末端插入数据pHeap->a[pHeap->size++] = x;//向下调整AdjustUp(pHeap->a, pHeap->size - 1);
}3.5 void HeapPop(Heap* pHeap) 的实现
这个函数用来删除堆顶数据,删除的方法就是:将堆顶数据与数组最后面的那个数据进行交换,然后将堆顶数据进行向下调整算法即可。
如下图,我们想要删除堆顶的 70 这个元素。
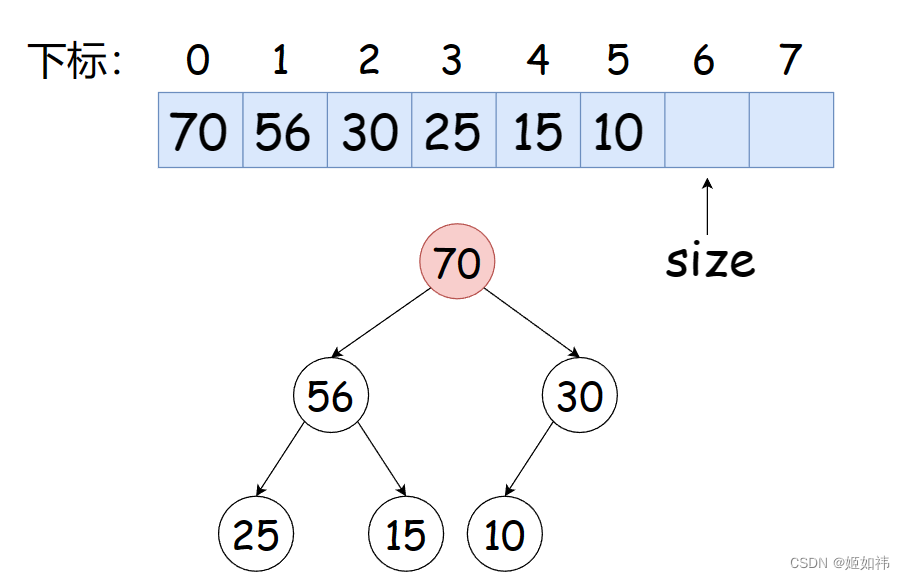
删除的方法是:我们将堆顶的 70 与数组末尾的 10 进行交换,然后对堆顶的数据(下标为0的元素,父节点)进行向下调整算法。根据公式找到下标为 0 的节点(父节点),的左右孩子中的那个较大的元素。如果下标为 0 的这个元素(父节点),小于左右孩子中较大的那个元素,交换他们的值。直到与叶子节点完成比较(交换)。如果比较的过程中父节点均大于他的左右孩子,那么结束循环即可。
//n表示数组的大小(堆的节点个数),parent 表示要向下调整的元素的下标
void AdjustDown(int* a, int n, int parent)
{//假设左孩子是父节点的左右孩子较大的int child = parent * 2 + 1;while (child < n){//如果右孩子存在,并且右孩子比左孩子大,假设错误,进行纠正if (child + 1 < n && a[child + 1] > a[child])child++;//如果比父节点大,交换并更新parent,childif (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else //否则退出循环,重新构建大堆完成{break;}}
}//删除堆顶数据
void HeapPop(Heap* pHeap)
{assert(pHeap);assert(!HeapEmpty(pHeap));Swap(&pHeap->a[0], &pHeap->a[pHeap->size - 1]);pHeap->size--;AdjustDown(pHeap->a, pHeap->size, 0);
}3.6 HeapDataType HeapTop(Heap* pHeap) 的实现
这个函数用于查看堆顶的元素,根据堆的物理结构与逻辑结构的关系,在堆不为空的前提下我们只要返回数组中下标为 0 的的元素即可。
//查看堆顶的数据
HeapDataType HeapTop(Heap* pHeap)
{assert(pHeap);assert(!HeapEmpty(pHeap));return pHeap->a[0];
}
3.7 int HeapSize(Heap* pHeap) 的实现
这个函数用于返回堆的元素个数,注意到我们在结构体中维护了一个变量size,显然,我们只需要返回size即可。
//堆的大小
int HeapSize(Heap* pHeap)
{assert(pHeap);return pHeap->size;
}4. 堆的应用
4.1 Top-K问题
TOP-K问题:即求数据集合中前 K 个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
2. 用剩余的 N - K 个元素依次与堆顶元素来比较,满足一定条件则替换堆顶元素。
将剩余 N - K 个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
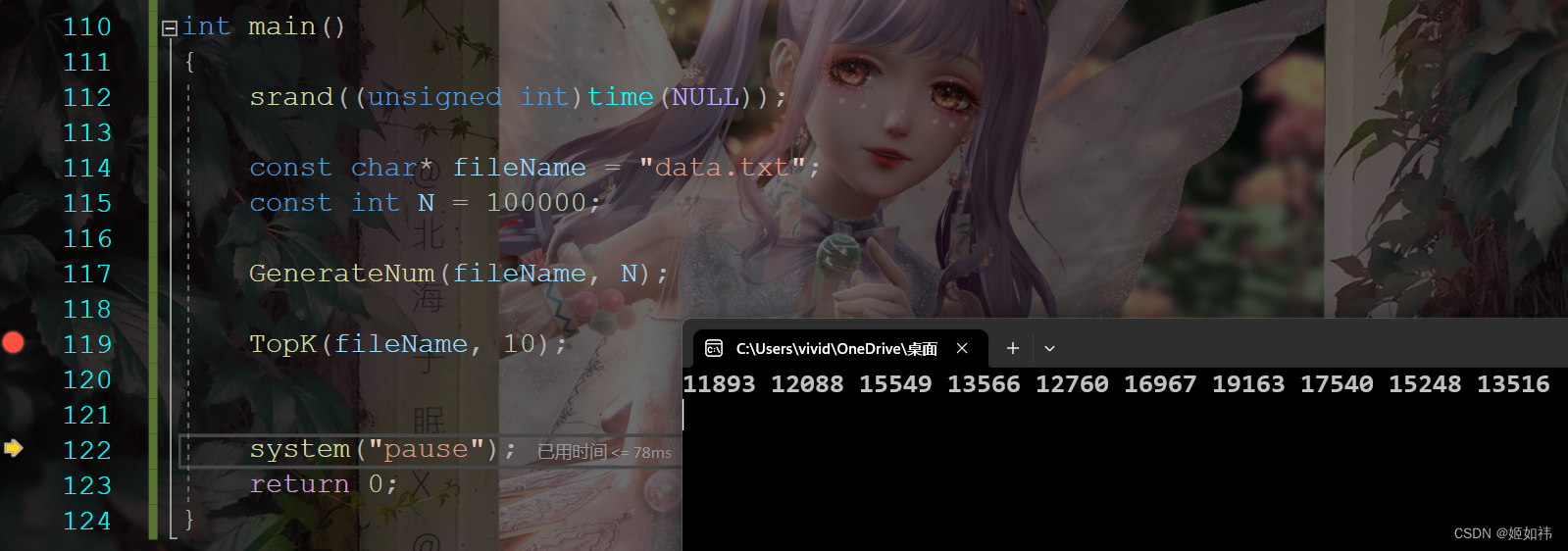
例题:我们随机生成10万个(或者更多)整型数据,将其保存在文件中(因为如果数据量太大内存无法保存这么多数据),然后我们要从中选出前十大的数据。
思路分析:
①:我们利用 rand() 函数生成 10 万个堆积数,将生成的随机数对1万取模,方便我们进行数据的精确选择(取模的原因后面会提到)。
②:将生成的数据逐个保存到文件中,生成完毕后我们将文件中的数据修改10个,要求修改后的值大于1万,这样我们就能够很轻松的验证我们的 Top-10 是否正确了。这里就是随机数对1万取模的原因。
③:然后我们开始读取文件,取前十个数据,构建一个小堆,为什么是小堆呢?因为小堆的堆顶元素是堆中数据最小的那个,一个数想要排进前十,那么你首先得比前十中第十名的那个数大吧。通俗的理解:一个房子里面有十个美女,而看门的是这十个美女中排名第十的那个,你想要进入这个房子的前提就是要比看门的那个美女漂亮。堆顶元素就相当于是一个门槛。
④:继续读取文件,直到将文件读完,我们就选出了全部数据的Top-10。
注意点:
我们的例题是选出前十大的元素因此需要构建小堆,上面的堆实现我们构建的是大堆。不可混用。
改文件的数据可以打断点,将文件的数据改出10个大与等于1万的即可。
//n表示数组的大小(堆的节点个数),parent 表示要向下调整的元素的下标
//构建小堆
void AdjustDown(int* a, int n, int parent)
{//假设左孩子是父节点的左右孩子较小的int child = parent * 2 + 1;while (child < n){//如果右孩子存在,并且右孩子比左孩子小,假设错误,进行纠正if (child + 1 < n && a[child + 1] < a[child])child++;//如果比父节点小,交换并更新parent,childif (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else //否则退出循环,重新构建小堆完成{break;}}
}//向上调整,构建小堆
void AdjustUp(int* a, int child)
{//根据公式找到父节点下标int parent = (child - 1) / 2;//child == 0 表明已经与根结点完成比较,所以循环条件为child > 0while (child > 0){//如果插入的元素小于父节点,交换if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else //否则的话,退出循环,完成建小堆{break;}}
}//将Top-K的数据打印
void PrintTopK(int* a, int n)
{for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\\n");
}//随机生成count个数据到文件
void GenerateNum(const char* file, int count)
{FILE* pf = fopen(file, "w");if (pf == NULL){perror("GenerateNum::fopen");exit(-1);}else{for (int i = 0; i < count; i++){int randNum = rand() % 10000; //对生成的随机数对1完取模,方便后续的操作fprintf(pf, "%d\\n", randNum); //输出到文件}fclose(pf);pf = NULL;}
}//求文件中数据的前k大的元素
void TopK(const char* file, int k)
{FILE* pf = fopen(file, "r");if (pf == NULL){perror("TopK::fopen");exit(-1);}else{int* topK = (int*)malloc(sizeof(int) * k);if (topK == NULL){perror("TopK::malloc");fclose(pf);pf = NULL;exit(-1);}else{int num;for (int i = 0; i < k; i++){fscanf(pf, "%d", &topK[i]); //先从文件中读取k个数据构建小堆AdjustUp(topK, i); //这里使用向上调整构建小堆}while (fscanf(pf, "%d", &num) != EOF) //读取文件中的剩余数据{if (num > topK[0]) //如果该数据比堆顶元素大,那么替换堆顶元素,向下调整{topK[0] = num;AdjustDown(topK, k, 0);}}PrintTopK(topK, k); //打印数据fclose(pf);pf = NULL;}}
}int main()
{//设置随机数的种子srand((unsigned int)time(NULL));//文件名以及数据的总量const char* fileName = "data.txt";const int N = 100000;//生成数据到问价GenerateNum(fileName, N);//选出Top-K的数据TopK(fileName, 10);system("pause");return 0;
}
4.2 堆排序
堆排序相关请戳我->-> 堆排序详解
