【学术搬砖】第一期

“一期一会” —— 珍惜我们遇见的论文,把和每个论文的相遇,当做一种缘分。我们会定期推荐若干优质学术论文,并分享一段总结,非常欢迎提出任何建议和想法。
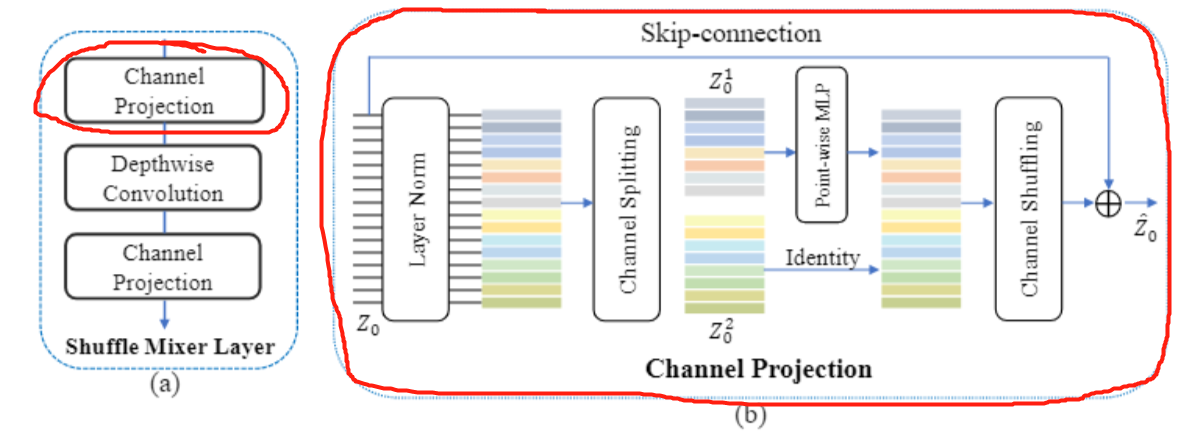
【NeurIPS2022】ShufflfleMixer: An Effificient ConvNet for Image Super-Resolution
NTIRE2022图像超分辨率冠军,来自南京理工大学。
核心是Shuffle Mixer Layer,包括 Channel Projection 和 大核卷积(7X7 的depth-wise conv)。
Channel projection把通道分成两部分,一半做FC,一半做做 identity。
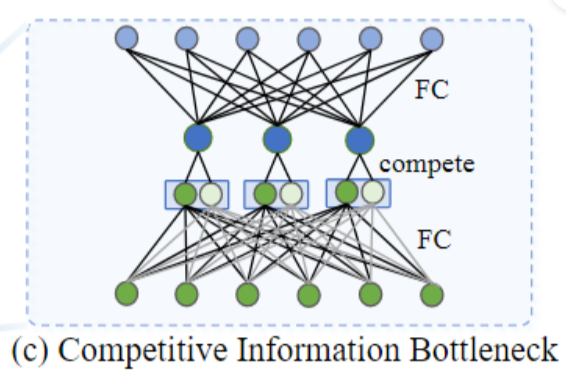
【ARXIV2212】A Close Look at Spatial Modeling: From Attention to Convolution
解读文章:https://zhuanlan.zhihu.com/p/602537181
bottleneck 的竞争机制,中间层全连接到两个节点,选择较大的一个做为输出。
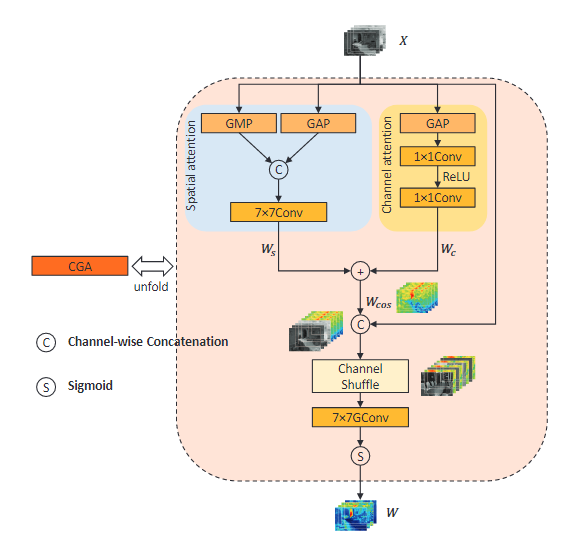
【ARXIV2301】DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
CBAM和channel shuffle组合,先使用CBAM进行并行处理,再将特征分为两组,进行channel shuffle。
【ICLR2023】SeaFormer: 轻量高效的注意力模块助力高分辨率语义分割端侧应用
论文解读:https://zhuanlan.zhihu.com/p/605083925
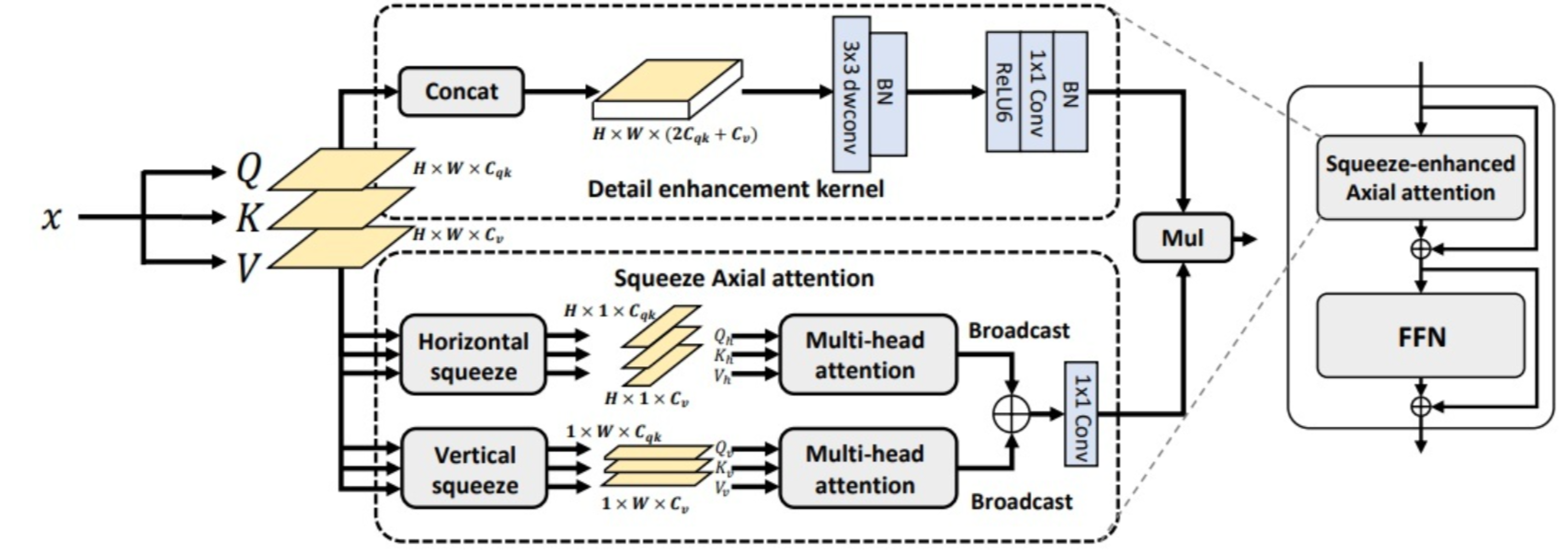
核心思想是上图,Q,K是共享的,上面 detail enhancement kernel 就是做卷积。下面的squeeze axial attention就是分别在H,W方向上压缩做 attention。
【CVPR2022】X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval
论文解读:https://zhuanlan.zhihu.com/p/608289445
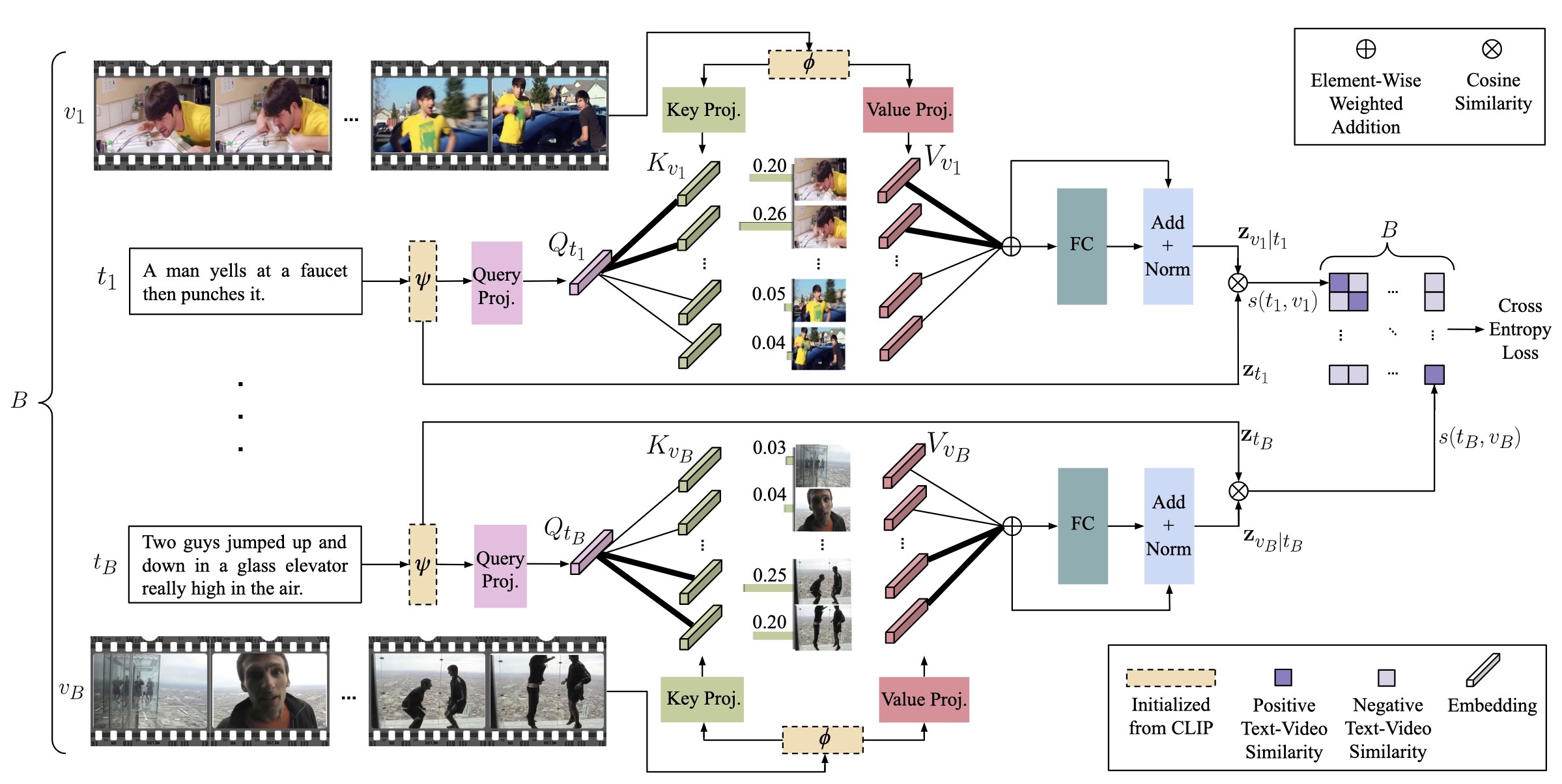
通过让文本学会关注其语义最相似的帧来进行聚合。在上面的例子中,输入的文本 t1 与视频 v1 中显示的前几帧最相关,这几帧是一个男人对着水槽大喊大叫并打了一拳。后面的视频和文本无关,是干扰。通过给最相关的帧分配更高的注意力权重,实现更好的聚合。
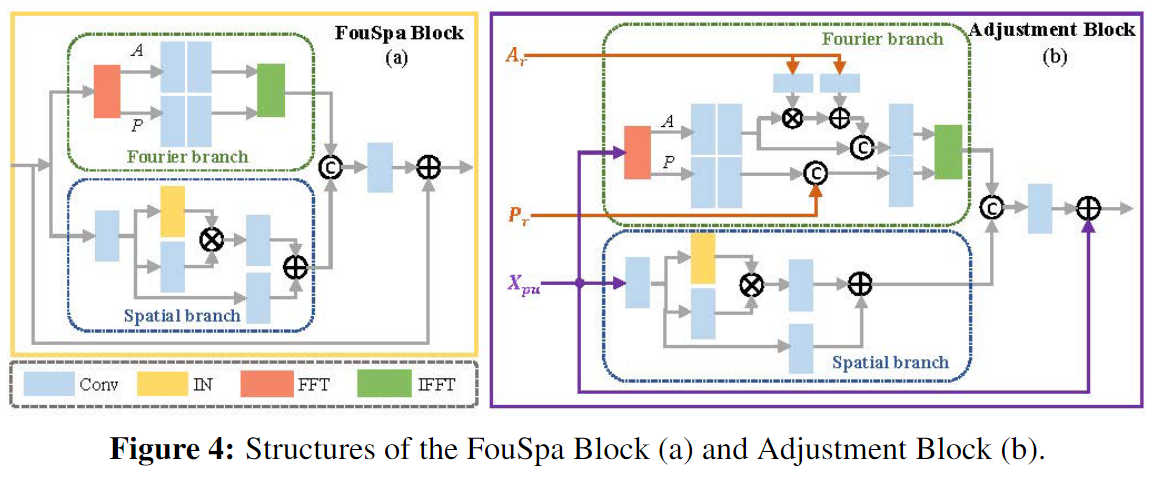
【ICLR2023】Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
论文解读:https://zhuanlan.zhihu.com/p/612994410
作者在低光图像的傅里叶域观察到两个现象:1、亮度和噪声在傅里叶域中可以在一定程度上分解,亮度表现为振幅,噪声与相位密切相关。2、不同分辨率图像的振幅模式相似。根据以上现象,本文提出了基于傅里叶变换的图像增强方法UHDFour,在傅里叶域中分别处理亮度和噪声,避免了在增强亮度时放大噪声,并且由于不同分辨率图像的振幅模式相似,可以先在低分辨率区域进行处理,只在高分辨率范围内进行必要的调整,从而节省计算量。