大数据能力提升项目|学生成果展系列之五


导读
为了发挥清华大学多学科优势,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和应用创新的“π”型人才,由清华大学研究生院、清华大学大数据研究中心及相关院系共同设计组织的“清华大学大数据能力提升项目”开始实施并深受校内师生的认可。项目通过整合建设课程模块,形成了大数据思维与技能、跨界学习、实操应用相结合的大数据课程体系和线上线下混合式教学模式,显著提升了学生大数据分析能力和创新应用能力。
回首2022年,清华大学大数据能力提升项目取得了丰硕的成果,同学们将课程中学到的数据思维和技能成功地应用在本专业的学习和科研中,在看到数据科学魅力的同时,也将自己打造成为了交叉复合型的创新型人才。下面让我们通过来自8个院系的10位同学代表一起领略他们的风采吧!
支持自动规则解译的智能审图系统
一、研究背景与课题来源
建筑环境的整个生命周期(设计、审查、施工、运维)受各种法规、规范和标准的约束。然而长期以来,建筑设计与审查过程高度依赖人工、自动化程度低,致使设计“错漏碰缺”及合规性问题突出,且往往存在施工条件冲突、可施工性差等问题(如图1所示),工期、成本损失最高分别可达9%和20%以上。
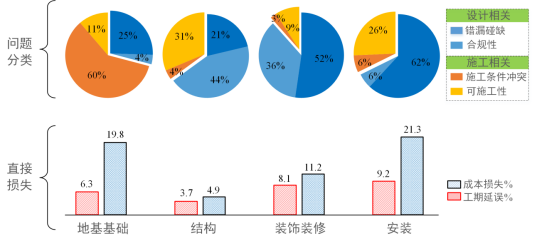
图1 建筑工程设计常见问题及其直接损失分析
传统人工核对的审查方式具有耗时长、易出错等缺点。一方面,传统设计审查方式高度依赖审查人员知识储备与经验积累,规范解读主观性大、尺度不一,严重影响设计审查的客观性与可靠性。另一方面,面对内容庞杂的工程设计图纸及繁琐、复杂的规范条文要求,审查人员肩负巨大压力,往往出现审查错误、纰漏等问题,且效率低下,严重影响设计审查的准确性和效率。
因此,自动规则审查(Automated Rule/Compliance Checking, ARC/ACC)应用而生。ARC系统需要将以自然语言表达的法规文本转化为计算机能够运行的代码,此过程称为规则解译。现有ARC的规则解译方法通常都是聘请土木-计算机复合人才将规范硬编码为可执行代码(称为硬编码),该方法得到的规则很难进行有效维护和修改。因此,亟需提出一种支持自动规则解译(Automated Rule Interpretation, ARI)的智能审图系统。
我受到大数据实践课程《深度学习》以及《自然语言处理与文本挖掘》两门课程的启发,提出了一种基于自然语言处理(Natural Language Processing, NLP)与领域知识的ARC框架,旨在利用领域知识与NLP提升语义对齐的能力更好地支持规则自动解译。最终构建支持自动规则解译的智能审图系统。
二、技术路线与实验效果
2.1 整体技术架构
我提出了一种基于NLP技术与领域知识支持自动规则解译的ARC框架,如图2所示。该框架由四个部分组成:(1)基于本体的知识建模、(2)模型准备、(3)规则解译和(4)模型检查。模型准备旨在将存储在IFC格式的BIM模型数据自动转换为Turtle(Terse RDF Triple Language)格式。本体知识建模旨在为系统提供领域共性知识。模型检查采用GraphGB提供的推理机进行检查。后文内容的介绍重点放在自动规则解译(ARI)。
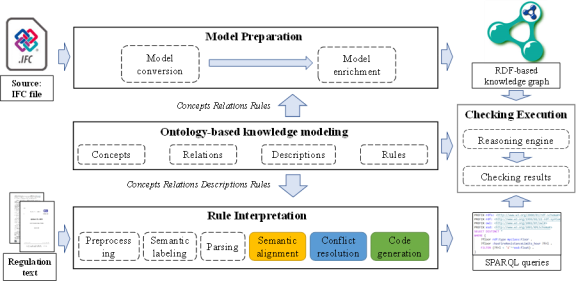
图2 基于 NLP 和知识通知的自动规则审查框架
2.2 自动规则解译(ARI)算法
规则解译旨在基于NLP技术自动将用自然语言表达的强制条文解译为计算机可处理的代码。所提出的方案的处理流程如图3所示。
首先采用BERT模型对规范进行命名实体识别(语义标注),然后采用CFG文法对标注后的语句进行语句解析,从自然语言规范生成语法树(解析);采用维基百科中文语料和中文规范语料库训练词向量模型,从而计算文本表达的概念与本体概念的语义相似度,实现初步语义对齐。随后提出两类冲突消解方法(域-值冲突消解方法和等价类冲突解决方法),根据土木工程领域知识修改语义对齐结果(如图4)。在语义对齐和冲突解决之后是代码生成环节,本文采用一种基于领域关键词与规则的条文分类方法,以识别出适合不同条文的SPARQL函数;最后执行代码生成步骤以将语法树转换为计算机可处理的格式(如图5)。

图3 自动规则解译的示例
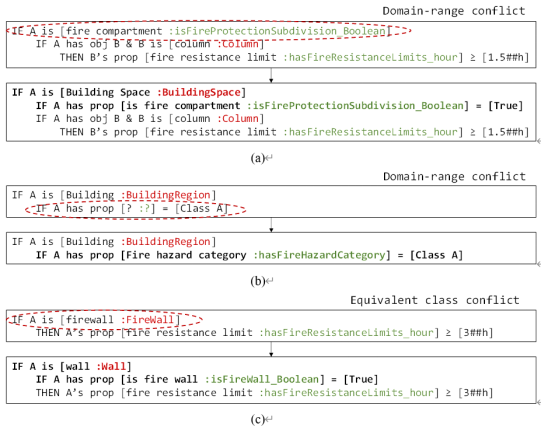
图4 冲突消解的示例

图5 代码生成过程中需要考虑的SPARQL语法
2.3 实验验证
首先对不同语义对齐方法的性能进行评估,以准确率和运行时间作为评价指标,结果如图6所示。所提出的语义相似度和冲突消解算法(W2VavgCR)达到了90.1%的最佳准确率。
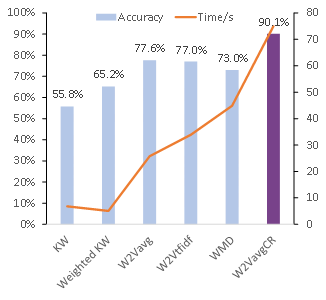
图6 所提出的算法的准确率
选择 4 个直接属性简单条文(Class 1)和 8 个间接属性复杂条文(Classes 2.1 & 2.2)。将所提出的方法所消耗的时间与专家人工解译所消耗的时间进行比较,结果如图7所示。与专业人士手工编写代码对比,自动解译方法效率平均提升5倍以上。
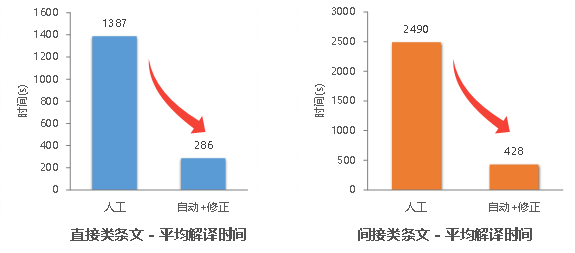
图7 规则解译效率提升5倍以上
编辑:文婧
校对:程安乐
