# Python爬虫求职信息的整合和百度翻译API测试

前言:
最近在找一些欧洲院校的科研职位,发现德国许多工程类的职位信息只提供了德语版,并且无法通过网页翻译工具直接进行翻译,因此在匹配详细职位信息的时候十分费力且费时,本博客基于此测试了一种Web信息聚合整理小工具。
Python爬虫求职信息的整合和百度翻译API测试
- 1. 测试项目简介
- 2. Dataframe数据整合、翻译结果
- 参考文献资料
1. 测试项目简介
由于浏览器自带的网页翻译功能并不支持对这些网页的翻译,本项目是希望能够设计一个自动化程序,分析德国某大学研究系列岗位的招聘信息并整理成列表,并将德语字符串转换为中文。
项目基本流程如下:
- 格式化爬虫信息
原始的数据信息如下:
Stellvertretende Dezernatsleitung / Wissenschaftliche/r Mitarbeiter/in (w/m/d) (in German only) [V000004876]#Dezernat Publikationen#[published 17/03/2023]Universitätsbibliothek [021000]15/04/2023Wissenschaftliche/r Mitarbeiter/in / Oberverwaltungsrat/Oberverwaltungsrätin (w/m/d) (in German only) [V000004877]#Dezernat Benutzung#[published 17/03/2023]Universitätsbibliothek [021000]15/04/2023...
采用python的字符串处理工具,提取关键信息并构建列表保存。
#
with open(r"...\\Web_spider\\data_source\\data2.txt", 'r', encoding='utf-8') as f:text = f.read()list_text = text.split('')
- 读取特定字段信息
ddl_list = []
str_t_list = []
langua_req_list = []
pos_title_list = []
descrip_list = []
ch_langua_req_list = []
ch_pos_title_list = []
ch_descrip_list = []# 循环遍历每个信息节点
for i in range(len(list_text)):deadline_time = list_text[i].split(' ')[-1]str_time = list_text[i].split('[published')[1].split(']')[0]try:language_req = (list_text[i].split('w/m/d'))[1].split(')')[1]except:language_req = (list_text[i].split('f/m/d'))[1].split(')')[1]# 翻译语言要求信息ch_langua_req = baiduTranslate(language_req)try:pos_title = list_text[i].split('(w/m/d')[0]except:pos_title = list_text[i].split('(f/m/d')[0]ch_pos_title = baiduTranslate(pos_title)a = list_text[i].split('[published')[0]descrip = a.split(']')[1]ch_descrip = baiduTranslate(descrip)# appendddl_list.append(deadline_time)str_t_list.append(str_time)ch_langua_req_list.append(ch_langua_req)ch_pos_title_list.append(ch_pos_title)ch_descrip_list.append(ch_descrip)langua_req_list.append(language_req)pos_title_list.append(pos_title)descrip_list.append(descrip)
- 利用百度翻译API将德语字符串转换为中文
# 百度翻译api调用
def baiduTranslate(translate_text):''':param translate_text: 待翻译的句子,len(q)<2000:return: 返回翻译结果。For example:q=我今天好开心啊!result = {'from': 'zh', 'to': 'en', 'trans_result': [{'src': '我今天好开心啊!', 'dst': "I'm so happy today!"}]}'''appid = 'xxx' # 填写你的appidsecretKey = 'xxx' # 填写你的密钥httpClient = Nonemyurl = '/api/trans/vip/translate' # 通用翻译API HTTP地址fromLang = 'auto' # 原文语种# if flag:# toLang = 'en' # 译文语种# else:# toLang = 'zh' # 译文语种toLang = 'zh'salt = random.randint(3276, 65536)sign = appid + translate_text + str(salt) + secretKeysign = hashlib.md5(sign.encode()).hexdigest()myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(translate_text) + '&from=' + fromLang + \\'&to=' + toLang + '&salt=' + str(salt) + '&sign=' + sign# 建立会话,返回结果try:httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')httpClient.request('GET', myurl)# response是HTTPResponse对象response = httpClient.getresponse()result_all = response.read().decode("utf-8")result = json.loads(result_all)# return resultreturn result['trans_result'][0]['dst']except Exception as e:print(e)finally:if httpClient:httpClient.close()
- 整合为列表
ch_zip_result = zip(ch_pos_title_list, ddl_list, str_t_list, ch_langua_req_list, ch_descrip_list)
ch_zip_result_list = list(ch_zip_result)zip_result = zip(pos_title_list, ddl_list, str_t_list, langua_req_list, descrip_list)
zip_result_list = list(zip_result)ch_df3 = pd.DataFrame(ch_zip_result_list, columns=["位置名称", "ddl", "str_time", "语言要求", "职位说明"])
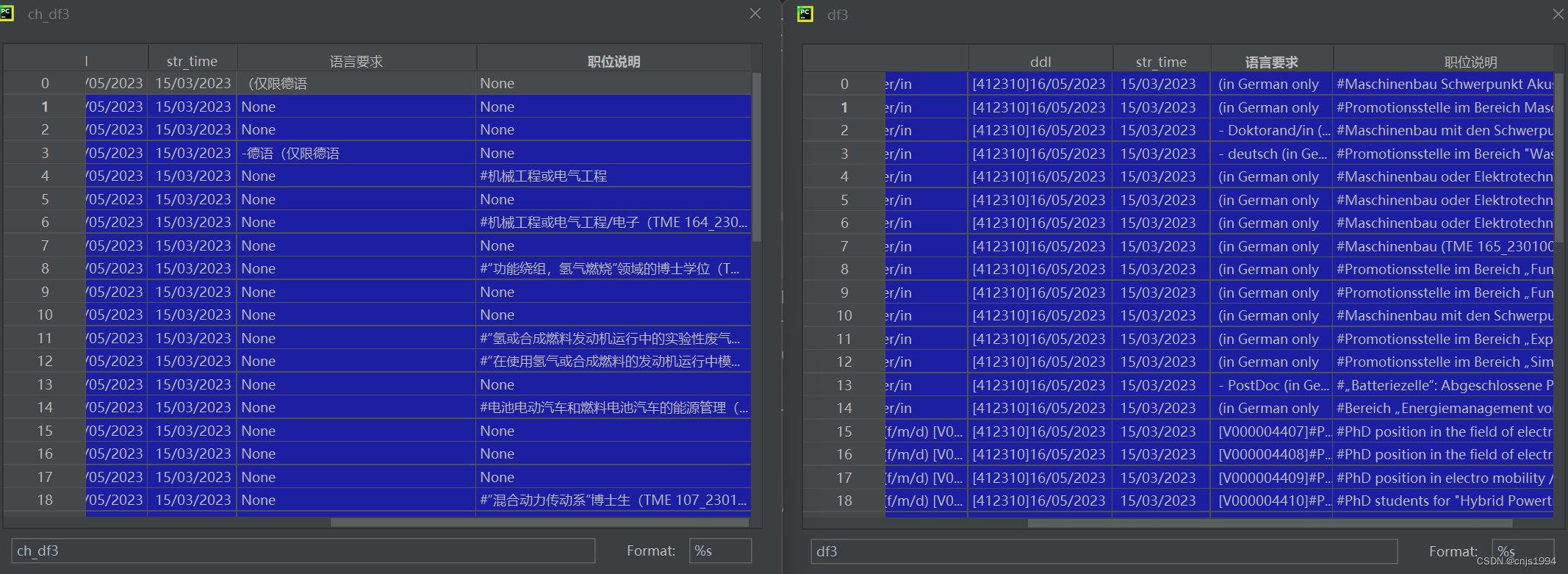
2. Dataframe数据整合、翻译结果
API调用BUG:虽然相比于网页版的完全无法翻译相对好了不少,但还是存在部分可以翻译的字段确显示为信息缺失了
参考文献资料
【1】可参考的百度API调用教程
【2】百度API调用官网
本博客完整代码内容请前往此处