卡尔曼滤波浅析

文章目录
- 前言
-
- 任务
- 状态预测
-
- 外部影响因素
- 外部不确定性
- 状态更新
-
- 利用测量进一步修正状态
- 合并两个高斯分布
- 公式汇总
- 图形化解释
- 总结(readme)
- references
前言
Kalman Filter算法,是一种递推预测滤波算法,算法中涉及到滤波,也涉及到对下一时刻数据的预测。Kalman Filter 由一系列递归数学公式描述。它提供了一种高效可计算的方法来估计过程的状态,并使估计均方误差最小。卡尔曼滤波器应用广泛且功能强大:它可以估计信号的过去和当前状态,甚至能估计将来的状态,即使并不知道模型的确切性质。
Kalman Filter 只能减小均值为0的测量噪声带来的影响。只要噪声期望为0,那么不管方差多大,只要迭代次数足够多,那效果都很好。反之,噪声期望不为0,那么估计值就还是与实际值有偏差。
任务
假设有一个做一维运动的小车,用x→k=[p,v]T\\overrightarrow x_k = [p, v]^Txk=[p,v]T表示其在k时刻的状态。
目标:预测小车的状态 x→\\overrightarrow xx,包括位置ppp与速度vvv,即可表示为
x^k=[pv]\\hat{x}_k = \\begin{bmatrix}p \\\\ v \\\\ \\end{bmatrix} x^k=[pv]
某个时刻,我们不知道真实的位置与速度到底是多少,二者存在一个所有可能性的组合,大致如下图所示。

卡尔曼滤波假设状态所有的变量都是随机的且都服从高斯分布,每个变量都有其对应的均值uuu以及方差σ2\\sigma^2σ2(它代表了不确定性)。

在上图中,位置和速度是不相关(uncorrelated)的,这意味着某个变量的状态不会告诉你其他变量的状态是怎样的。即,我们虽然知道现在的速度,但无法从现在的速度推测出现在的位置。但实际上并非如此,我们知道速度和位置是有关系的(correlated),这样一来二者之间的组合关系变成了如下图所示的情况。

这种情况是很容易发生的,例如,如果速度很快,我们可能会走得更远,所以我们的位置会更大。如果我们走得很慢,我们就不会走得太远。
这种状态变量之间的关系很重要,因为它可以为我们提供更多信息:One measurement tells us something about what the others could be。这就是卡尔曼滤波器的目标,我们希望从不确定的测量中尽可能多地获取信息!
这种状态量的相关性可以由协方差矩阵表示。简而言之,矩阵 Σij\\Sigma_{ij}Σij 的每个元素是第 iii 个状态变量和第 jjj 个状态变量之间的相关度。(显然地可以知道协方差矩阵是对称的,这意味着交换 iii 和 jjj 都没关系)。协方差矩阵通常标记为“ Σ\\SigmaΣ ”,因此我们将它们的元素称为“ Σij\\Sigma_{ij}Σij ”。

状态预测
我们把状态建模成高斯分布(Gaussian blob,由于二维高斯分布长得像一个个小泡泡)。我们需要求解/估计在时间 kkk 时刻的两个信息:最优估计 x^k\\hat{x}_kx^k 以及它的协方差矩阵 PkP_kPk,我们可以写成下面矩阵形式:
x^k=[positionvelocity]Pk=[ΣppΣpvΣvpΣvv](1)\\begin{matrix} \\begin{matrix} \\hat{x}_k = \\begin{bmatrix}position \\\\ velocity \\\\ \\end{bmatrix} \\\\ P_k = \\begin{bmatrix}\\Sigma_{pp} & \\Sigma_{pv} \\\\ \\Sigma_{vp} &\\Sigma_{vv} \\\\ \\end{bmatrix} \\end{matrix} & (1) \\end{matrix} x^k=[positionvelocity]Pk=[ΣppΣvpΣpvΣvv](1)
(当然,这里我们仅使用位置和速度,但是请记住状态可以包含任意数量的变量,并且可以表示所需的任何变量)
接下来,我们需要某种方式来查看当前状态(k−1k-1k−1时刻)并预测在 kkk 时刻处的状态。请记住,我们不知道哪个状态是“真实”状态,但是这里提到的预测(prediction)并不在乎这些。

我们可以用一个矩阵 FkF_kFk 来表示这个预测过程:

这个矩阵 FkF_kFk 将原始估计中的每个点移动到新的预测位置。
那么问题来了,应该如何使用上述矩阵来预测下一时刻的位置和速度呢?为了阐述这个过程,我们使用了一个非常基础的运动学公式进行描述:
pk=pk−1+Δtvk−1vk=vk−1\\begin{matrix} p_k = p_{k-1} + \\Delta tv_{k-1} \\\\ v_k = v_{k-1} \\end{matrix} pk=pk−1+Δtvk−1vk=vk−1
写成矩阵形式:
x^=[1Δt01]x^k−1(2)=Fkx^k−1(3)\\begin{matrix} \\hat x = \\begin{bmatrix} 1& \\Delta t \\\\ 0 & 1 \\end{bmatrix} \\hat x_{k-1} &(2) \\\\ = F_k \\hat x_{k-1} & (3) \\end{matrix} x^=[10Δt1]x^k−1=Fkx^k−1(2)(3)
现在我们有了一个预测矩阵或者叫做状态转移矩阵,该矩阵可以帮助我们计算下一个时刻的状态。但我们仍然不知道如何更新状态的协方差矩阵,其实过程也是很简单,如果我们将分布中的每个点乘以矩阵 AAA,那么其协方差矩阵 Σ\\SigmaΣ 会发生什么?
Cov(x)=ΣCov(Ax)=AΣAT(4)\\begin{matrix} \\begin{matrix} Cov(x) = \\Sigma \\\\ Cov(Ax) = A \\Sigma A^T \\end{matrix} & (4) \\end{matrix} Cov(x)=ΣCov(Ax)=AΣAT(4)
将公式(3)代入公式(4)我们可以得到:
x^k=Fkx^k−1Pk=FkPk−1FkT(5)\\begin{matrix} \\begin{matrix} \\hat x_k = F_k \\hat x_{k-1} \\\\ P_k = F_k P_{k-1}F_k^T \\end{matrix} & (5) \\end{matrix} x^k=Fkx^k−1Pk=FkPk−1FkT(5)
外部影响因素
不过我们并没有考虑到所有的影响因素。可能有一些与状态本身无关的变化——如外界因素可能正在影响系统。
例如,我们用状态对列车的运动进行建模,如果列车长加大油门,火车就加速。同样,在我们的机器人示例中,导航系统软件可能会发出使车轮转动或停止的命令。如果我们很明确地知道这些因素,我们可以将其放在一起构成一个向量 u→k\\overrightarrow u_kuk,我们可以对这个量进行某些“处理”,然后将其添加到我们的预测中对状态进行更正。
假设我们知道由于油门设置或控制命令而产生的预期加速度 aaa。根据基本运动学原理,我们可以得到下式:
pk=pk−1+Δtvk−1+12aΔt2vk=vk−1+aΔt\\begin{matrix} p_k = p_{k-1} + \\Delta tv_{k-1} + \\frac{1}{2}a\\Delta t^2 \\\\ v_k = v_{k-1} + a\\Delta t \\end{matrix} pk=pk−1+Δtvk−1+21aΔt2vk=vk−1+aΔt
将其写成矩阵形式:
x^k=Fkx^k−1+[Δt22Δt]a=Fkx^k−1+Bku^k(6)\\begin{matrix} \\begin{split} \\hat x_k = F_k \\hat x_{k-1} + \\begin{bmatrix} \\frac{\\Delta t^2}{2}\\\\ \\Delta t \\end{bmatrix} a \\\\ = F_k \\hat x_{k-1} + B_k \\hat u_k \\end{split} & (6) \\end{matrix} x^k=Fkx^k−1+[2Δt2Δt]a=Fkx^k−1+Bku^k(6)
其中 BkB_kBk 被称为控制矩阵,u^k\\hat u_ku^k 被称为控制向量。(注意:对于没有外部影响的简单系统,可以忽略这个控制项)。
下一步为添加外部的不确定性。
外部不确定性
如果状态仅仅依赖其自身的属性进行演进,那一切都会很好。如果状态受到外部因素进行演进,我们只要知道这些外部因素是什么,那么一切仍然很好。
但在实际使用中,我们有时不知道的这些外部因素到底是如何被建模的。例如,我们要跟踪四轴飞行器,它可能会随风摇晃;如果我们跟踪的是轮式机器人,则车轮可能会打滑,或者因地面颠簸导致其减速。我们无法跟踪这些外部因素,如果发生任何这些情况,我们的预测可能会出错,因为我们并没有考虑这些因素。
通过在每个预测步骤之后添加一些新的不确定性,我们可以对与“世界”相关的不确定性进行建模(如我们无法跟踪的事物):

这样一来,由于新增的不确定性原始估计中的每个状态都可能迁移到多个状态。因为我们非常喜欢用高斯分布进行建模,此处也不例外。我们可以说 x^k−1\\hat x_{k-1}x^k−1 的每个点都移动到具有协方差 QkQ_kQk 的高斯分布内的某个位置,如下图所示:

这将产生一个新的高斯分布,其协方差不同(但均值相同):

所以呢,我们在状态量的协方差中增加额外的协方差 QkQ_kQk,所以预测阶段完整的状态转移方程为:
x^k=Fkx^k−1+Bku→kPk=FkPk−1FkT+Qk(7)\\begin{matrix} \\begin{split} \\hat x_k = F_k\\hat x_{k-1} + B_k\\overrightarrow u_k \\\\ P_k = F_kP_{k-1}F_k^T + Q_k \\end{split} &(7) \\end{matrix} x^k=Fkx^k−1+BkukPk=FkPk−1FkT+Qk(7)
换句话说:新的最佳估计是根据先前的最佳估计做出的预测,再加上对已知外部影响的校正。
新的不确定度是根据先前的不确定度做出的预测,再加上来自环境额外的不确定度。
上述过程描绘了状态预测过程,那么当我们从传感器中获取一些测量数据时会发生什么呢?
状态更新
利用测量进一步修正状态
假设我们有几个传感器,这些传感器可以向我们提供有关系统状态的信息。就目前而言,测量什么量都无关紧要,也许一个读取位置,另一个读取速度。每个传感器都告诉我们有关状态的一些间接信息(换句话说,传感器在状态下运作并产生一组测量读数)。

请注意,测量的单位可能与状态量的单位不同。我们使用矩阵 HkH_kHk 对传感器的测量进行建模。

所以我们期望传感器的度数可以被建模成如下形式:
u→expected=Hkx^kΣexpected=HkPkHkT(8)\\begin{matrix} \\begin{split} \\overrightarrow u_{expected} = H_k\\hat x_k \\\\ \\Sigma_{expected} = H_kP_kH_k^T \\end{split} &(8) \\end{matrix} uexpected=Hkx^kΣexpected=HkPkHkT(8)
卡尔曼滤波器的伟大之处就在于它能够处理传感器噪声。换句话说,传感器本身的测量是不准确的,且原始估计中的每个状态都可能导致一定范围的传感器读数,而卡尔曼滤波能够在这些不确定性存在的情况下找到最优的状态。

根据传感器的读数,我们会猜测系统正处于某个特定状态。但是由于不确定性的存在,某些状态比其他状态更可能产生我们看到的读数:

我们将这种不确定性(如传感器噪声)的协方差表示为 RkR_kRk,读数的分布均值等于我们观察到传感器的读数,我们将其表示为 z→k\\overrightarrow z_kzk
这样一来,我们有了两个高斯分布:一个围绕通过状态转移预测的平均值,另一个围绕实际传感器读数。

因此,我们需要将基于预测状态(粉红色)的推测读数与基于实际观察到的传感器读数(绿色)进行融合。
那么融合后最有可能的新状态是什么?对于任何可能的读数 (z1,z2)(z_1, z_2)(z1,z2),我们都有两个相关的概率:(1)我们的传感器读数 z→k\\overrightarrow z_kzk 是(z1,z2)(z_1, z_2)(z1,z2)的概率,以及(2)先前估计值 Hkx^kH_k\\hat x_kHkx^k 是 (z1,z2)(z_1, z_2)(z1,z2)的概率。
如果我们有两个概率,并且想知道两个概率都为真的机会,则将它们相乘。因此,我们对两个高斯分布进行相乘处理:

两个概率分布相乘得到的就是上图中的重叠部分。而且重叠部分的概率分布会比我们之前的任何一个估计值/读数都精确得多,这个分布的均值就是最终我们想要得到的值。

事实证明,两个独立的高斯分布相乘之后会得到一个新的具有其均值和协方差矩阵的高斯分布!下面开始推公式。
合并两个高斯分布
首先考虑一维高斯情况:一个均值为 uuu,方差为 σ2\\sigma^2σ2 的高斯分布的形式为:
N(x,u,σ)=1σ2πe−(x−u)22σ2(9)\\begin{matrix} N(x, u, \\sigma) = \\frac{1}{\\sigma \\sqrt{2\\pi}}e^{-\\frac{(x-u)^2}{2\\sigma^2}} & (9) \\end{matrix} N(x,u,σ)=σ2π1e−2σ2(x−u)2(9)
我们想知道将两个高斯曲线相乘会发生什么。下图中的蓝色曲线表示两个高斯总体的(未归一化)交集:

N(x,u,σ)⋅N(x,u1,σ1)=>N(x,u′,σ′)(10)\\begin{matrix} N(x, u, \\sigma) · N(x, u_1,\\sigma_1) => N(x, u', \\sigma') & (10) \\end{matrix} N(x,u,σ)⋅N(x,u1,σ1)=>N(x,u′,σ′)(10)
将公式(9)代入公式(10),我们可以得到新的高斯分布的均值和方差如下所示:
u′=u0+σ02(u1−u0)σ02+σ12σ′2=σ02−σ04σ02+σ12(11)\\begin{matrix} \\begin{split} u' = u_0 + \\frac{\\sigma_0^2(u_1-u_0)}{\\sigma_0^2+\\sigma_1^2}\\\\ \\sigma'^2 = \\sigma_0^2 - \\frac{\\sigma_0^4}{\\sigma_0^2+\\sigma_1^2} \\end{split} &(11) \\end{matrix} u′=u0+σ02+σ12σ02(u1−u0)σ′2=σ02−σ02+σ12σ04(11)
我们将其中的一小部分重写为kkk:
k=σ02σ02+σ12(12)\\begin{matrix} \\begin{split} k = \\frac{\\sigma_0^2}{\\sigma_0^2+\\sigma_1^2} \\end{split} &(12) \\end{matrix} k=σ02+σ12σ02(12)
u′=u0+k(u1−u0)σ′2=σ02−kσ02(13)\\begin{matrix} \\begin{split} u' = u_0 + k(u_1-u_0) \\\\ \\sigma'^2 = \\sigma_0^2 - k\\sigma_0^2 \\end{split} \\end{matrix} \\tag{13} u′=u0+k(u1−u0)σ′2=σ02−kσ02(13)
这样一来,公式的形式就简单多了!我们顺势将公式(12)和(13)的矩阵形式写在下面:
K=Σ0(Σ0+Σ1)−1(14)\\begin{matrix} \\begin{split} K = \\Sigma_0(\\Sigma_0 + \\Sigma_1)^{-1} \\end{split} \\end{matrix} \\tag{14} K=Σ0(Σ0+Σ1)−1(14)
u→′=u0→+K(u→1−u→0)Σ′=Σ0−KΣ0(15)\\begin{matrix} \\begin{split} \\overrightarrow u' = \\overrightarrow{ u_0} + K(\\overrightarrow u_1-\\overrightarrow u_0) \\\\ \\Sigma' = \\Sigma_0 - K\\Sigma_0 \\end{split} \\end{matrix} \\tag{15} u′=u0+K(u1−u0)Σ′=Σ0−KΣ0(15)
其中 Σ\\SigmaΣ 表示新高斯分布的协方差矩阵,u→\\overrightarrow uu 是每个维度的均值,KKK 就是大名鼎鼎的卡尔曼增益 (Kalman gain)
公式汇总

图形化解释
x^k′\\hat x_k'x^k′ 就是更新后的最优状态!接下来我们可以继续进行预测,然后更新,重复上述过程!下图给出卡尔曼滤波信息流。
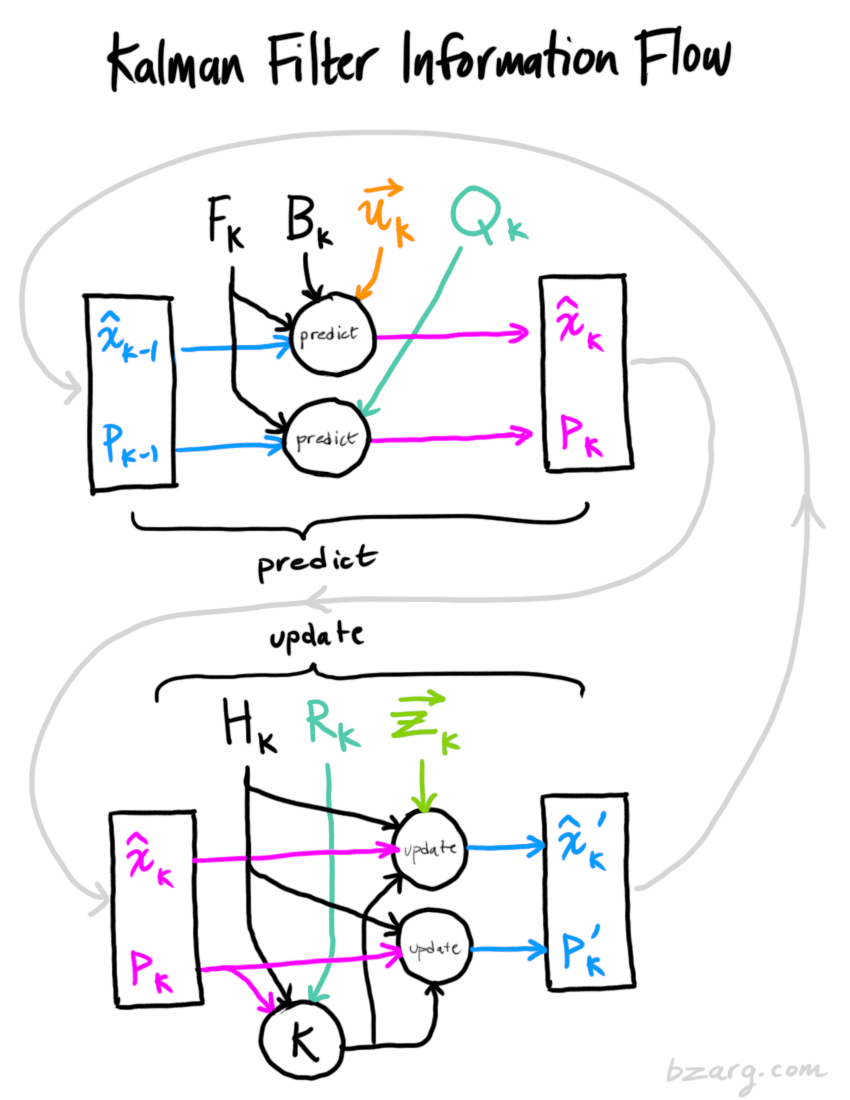
在上述所有数学公式中,你需要实现的只是公式 (7)(18)和(19)。(或者,如果你忘记了这些,可以从等式(4)和(15)重新推导所有内容。)
这将使你能够准确地对任何线性系统建模。对于非线性系统,我们使用扩展卡尔曼滤波器,该滤波器通过简单地线性化预测和测量值的均值进行工作。
总结(readme)
预测:
- 对真实值进行估计,需要考虑噪声,通常假设噪声服从0均值的高斯分布 N(0,σ)N(0, \\sigma)N(0,σ),扩展到高维就是协方差 Xt−1N(X^t−1,Σ)X_{t-1}~N(\\hat X_{t-1}, \\Sigma)Xt−1 N(X^t−1,Σ)
- 系统中每一个时刻的不确定性都是通过协方差矩阵 Σ\\SigmaΣ来给出的。这种不确定性在每个时刻也会进行传递,也就是说不仅当前物体的状态会进行传递,而且物体状态的不确定性也会进行传递
- 预测模型本身也不绝对准确,需要引入一个wtN(0,Q)w_t~N(0, Q)wt N(0,Q)表示预测模型本身的噪声(也即是噪声在传递过程中的不确定性)
Xt−1N(X^t−1,Σ)→Xt=FtXt−1+Btut+wtXtN(FtX^t−1+Btut,FtΣt−1FtT+Q)X_{t-1}~N(\\hat X_{t-1}, \\Sigma) \\xrightarrow[]{X_t = F_tX_{t-1}+B_tu_t+w_t} X_t~N(F_t\\hat X_{t-1}+B_tu_t, F_t\\Sigma_{t-1}F_t^T+Q) Xt−1 N(X^t−1,Σ)Xt=FtXt−1+Btut+wtXt N(FtX^t−1+Btut,FtΣt−1FtT+Q)
根据观测值对预测值进行更新从而得到输出值:
- 真实状态我们其实是无法得知的,只能通过观测值来对真实值进行估计,假设路边布置了速度显示器实时显示车辆的速度
- t时刻小车的观测值为ztz_tzt,小车的真实状态到其观测状态有一个变换关系HtH_tHt,
- 卡尔曼滤波思想:Xupdate=Xpredict+g(Xobservation−Xpredict)X_{update} = X_{predict} + g(X_{observation} -X_{predict})Xupdate=Xpredict+g(Xobservation−Xpredict)其中0<=g<=1,g是根据两者的方差计算的g=Epred/(Epred+Eobserv)g = E_{pred}/(E_{pred}+E_{observ})g=Epred/(Epred+Eobserv)
对于公式(18)(19):
x^k′:滤波后的值\\hat x_k' : 滤波后的值x^k′:滤波后的值
Pk′:滤波后的协方差P_k' :滤波后的协方差Pk′:滤波后的协方差
K′:系数,1.状态空间转换2.考虑协方差K' : 系数,1.状态空间转换 2.考虑协方差K′:系数,1.状态空间转换2.考虑协方差
x^k:预测值\\hat x_k : 预测值x^k:预测值
z→k:观测值\\overrightarrow z_k : 观测值zk:观测值
Hk:观测值与预测值之间空间转换关系H_k : 观测值与预测值之间空间转换关系Hk:观测值与预测值之间空间转换关系
Pk:协方差预测值P_k : 协方差预测值Pk:协方差预测值
Rk:传感器协方差R_k : 传感器协方差Rk:传感器协方差
references
https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247601352&idx=1&sn=080e64b063f9c7c9b69d8ee7c3e526d1&chksm=fb54ae24cc2327325b628cbe903b3daa82f10c73c3afc470f68fc85b82b1cf5aa3c228e82246&scene=27
How a Kalman filter works, in pictures, 图解卡尔曼滤波是如何工作的http://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/#mathybits
A geometric interpretation of the covariance matrix, 协方差矩阵的几何解释: https://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix
Kalman Filter 卡尔曼滤波: https://sikasjc.github.io/2018/05/08/kalman_filter