Redis7高级之案例实战 hyperloglog(五)
今天咱们聊一个Redis里面的高级玩法——HyperLogLog。在海量数据的统计中,这小家伙可是个宝贝。那什么是HyperLogLog呢?简单概括,它是一个用来估算基数的统计工具,比如UV(独立访客)啦,PV(页面浏览量)啦。特别是在数据量巨大的情况下,它的表现尤其惊艳——只需12KB的内存就能处理接近2^64个元素的基数,这个内存占用比Bitmap少了不知道多少倍呢!
你可能会问,为什么不用MySQL?嘿嘿,MySQL在这种高并发下就会扛不住,像个过度的网红店,人少还好,人一多就崩溃了。那Bitmap呢?虽然精确,但内存吃得太厉害,1个亿的数据就要12M,10000个这样的样本,就要120G的内存,简直是天价啊!
那HyperLogLog的原理是什么呢?它牺牲了点儿精度,误差只有0.81%左右,就像一位睿智的老者,不在乎细节,但抓住了大势。对于UV统计来说,这点误差完全可以接受,毕竟谁也不会介意差个0.8%的用户数吧!
所以啊,当你需要统计亿级的UV时,HyperLogLog就是你的最佳选择。而且代码实现起来也很简单,用Redis自带的API就能轻松搞定。你要是还在为选择存储方案发愁,试试HyperLogLog,保证你会感叹:“这才是真正的大法啊!”

5.1 系统中常见的四种统计
1.聚合统计
统计多个集合元素的聚合结果(交并差集合统计) set集合
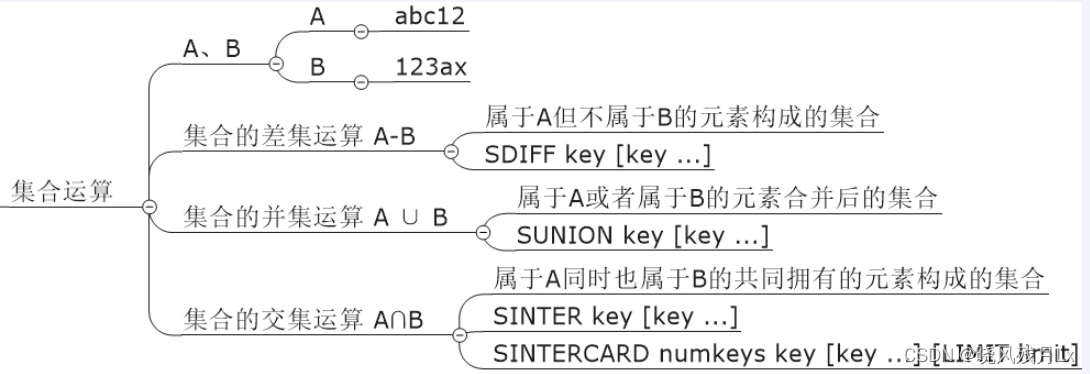
2.排序统计
抖音短视频最新评论留言的场景,设计一个展现列表
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用zset
3.二值统计
集合元素的取值就只有 0 和 1 ,来记录签到还是没签到 bitmap
4.基数统计
只统计一个集合中不重复的元素个数 hyperloglog
5.2hyperloglog
1.名词解释
- UV (Unique Visitor) 独立访客,一般理解为客户端IP (需要考虑去重)
- PV (Page View) 页面浏览量,不用去重
- DAU(Daily Active User)日活跃用户量,登录或者使用了某个产品的用户数(去重复登录的用户),常用于反映网站、互联网应用或者网络游戏的运营情况
- MAU(Monthly Active User)月活跃用户量
2.需求
很多计数类场景,比如 每日注册 IP 数、每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。
因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
统计单日一个页面的访问量(PV),单次访问就算一次。
统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。
多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
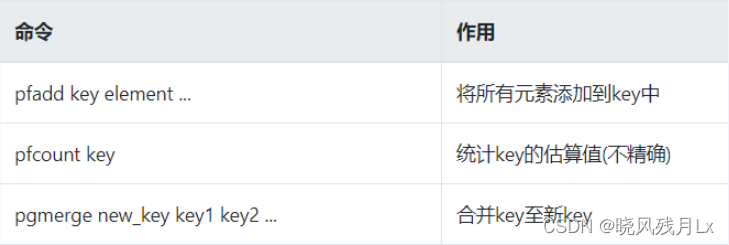
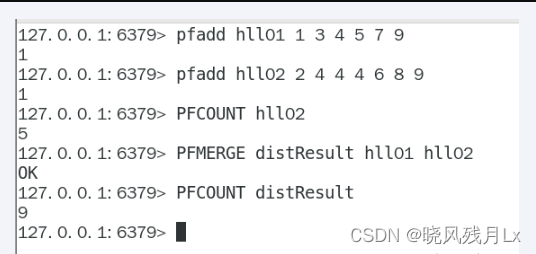
3.hyperloglog复习
- 基数
- 是一种数据集,去重复后的真实个数
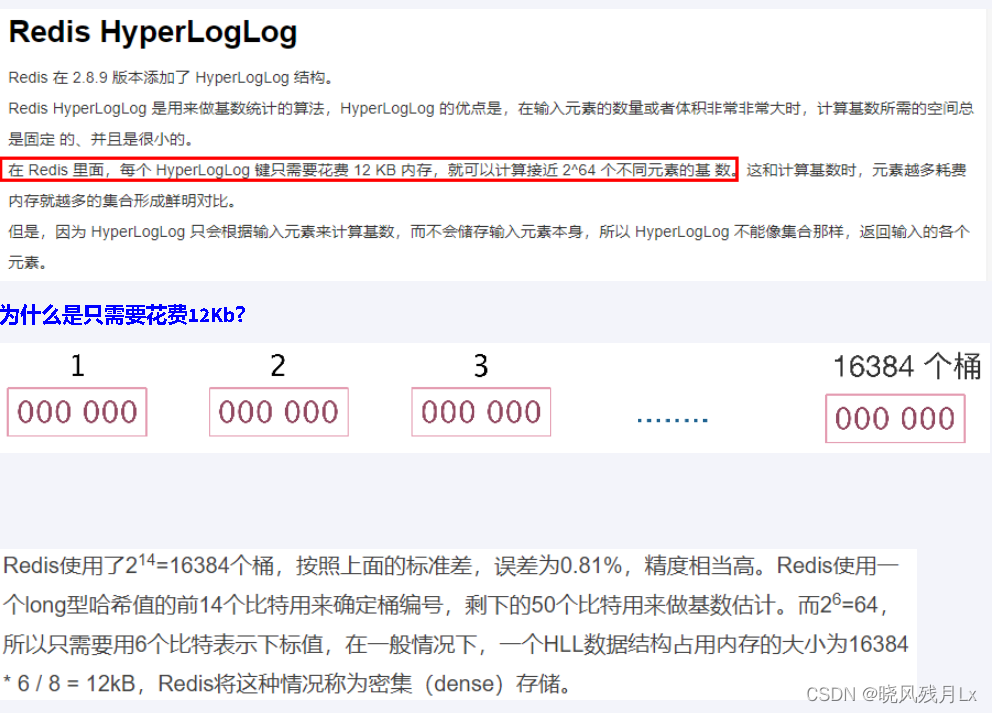
- 在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2的64次方个不同元素的基数
-
基数统计就是 HyperLogLog
-
去重复统计功能
- hashSet
- bitmap
- bitmap是通过用位bit数组来表示各元素是否出现,每个元素对应一位,所需的总内存为N个bit。
- 新进入的元素只需要将已经有的bit数组和新加入的元素进行按位或计算就行。这个方式能大大减少内存占用且位操作迅速。
- 如果数据较大,比如一个样本案例就是一亿个基数拉值数据,一个样本就是一亿,如果要统计一亿个数据的基数拉值,大约需要内存 1100000000/8/1024/1024 约等于 12M,内存减少占用的效果显著。这样得到统计一个对象样本的基数值需要12M。
- 如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用bitmaps还是不适用大数据量下(亿级)的基数计数场景,
- 但是bitmap是精确计算的
- 结论
- 量变会引起质变
- 办法
- 概率算法
- 通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身
- HyperLogLog就是一种概率算法的实现。
- 概率算法
-
原理说明
-
只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容
-
有误差
- hyperloglog提供不精确的去重技术方案
- 牺牲准确率来换取空间,误差仅仅只是 0.81% 左右
-
-
5.3统计亿级UV的Redis方案
1.对于技术的选型
- 用mysql
- mysql扛不住稍微大一点的并发,而且都需要存入mysql中,导致mysql的检索也会变慢
- 用redis的hash结构存储
- 按照ipv4的结构来说明,一个ip最多15个字节(ip=“192.168.238.1xx”),某一天 1.5亿*15个字节 = 2G,一个月60G,内存直接没了,加内存条都没用
- hyperloglog
- 在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2的64次方个不同元素的基数
2.编码(yml和pom与上次一致)
-
HypeLogLogService
/* @author 晓风残月Lx* @date 2023/3/27 20:18*/ public interface HypeLogLogService {public long uv(); } -
HyperLogLogServiceImpl
import com.xfcy.service.HypeLogLogService;import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Random;
import java.util.concurrent.TimeUnit;/* @author 晓风残月Lx* @date 2023/3/27 20:18*/
@Slf4j
@Service
public class HypeLogLogServiceImpl implements HypeLogLogService {@Resourceprivate RedisTemplate redisTemplate;/* 模拟后台有用户点击网站首页,每个用户来自不同的IP地址 @PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器执行一次。*/@PostConstructpublic void initIp(