YARN On Mapreduce搭建与wordCount案例实现

文章目录
1.前言
YARN的基本思想是将资源管理RM,和作业调度、监控功能拆分成单独的守护进程。这个思想中拥有一个全局的资源管理器以及每个应用的MASTER,AM。每一个应用 都是单个作业或者一个DAG作业。
架构图:
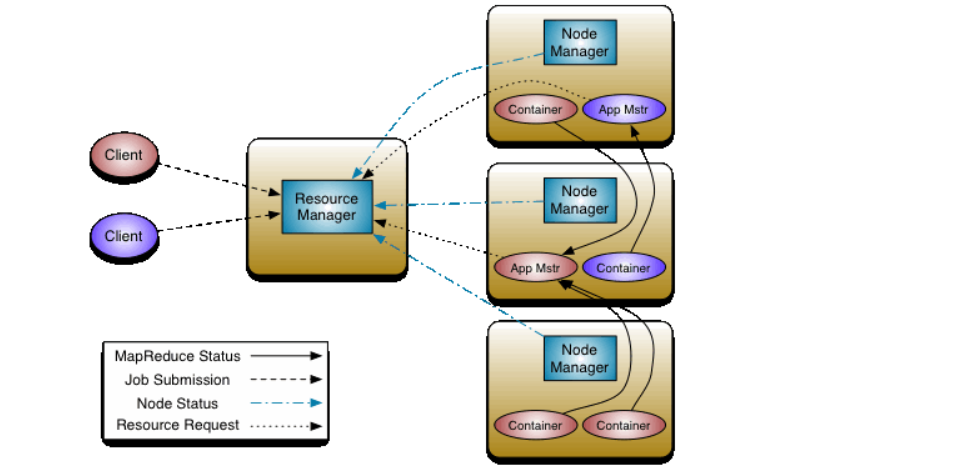
1.YARN 集群搭建
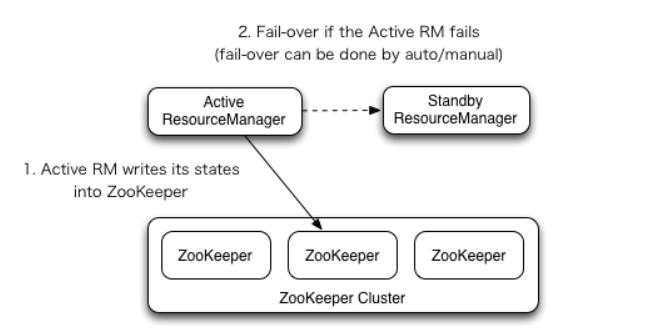
1.1 ResourceManager High Availability 架构图
1.2 配置文件
mapred-site.xml
cp mapred-site.xml.template mapred-site.xmlvi mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node02:2181,node03:2181,node04:2181</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>mashibing</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node03</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node04</value></property>
配置节点分发到其他节点。
1.3 启动服务和rm
启动yarn
start-yarn.sh
启动rm资源管理
yarn-daemon.sh start resourcemanager
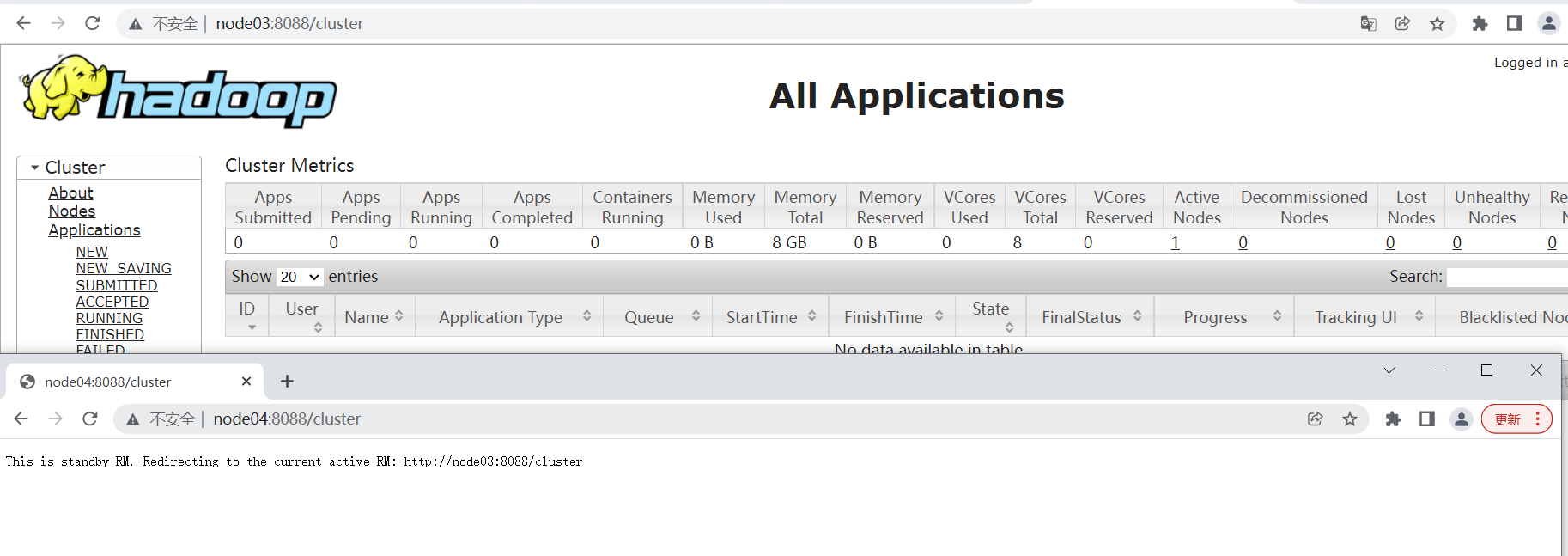
访问页面查看集群状态
http://node03:8088
http://node04:8088
2.运行官方的WC案例
/opt/bigdata/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
2.1 运行jar
准备一个data.txt文件
hello word
elite hello
hello word
hadoop yarn
hive hbase
hive haoop
# 创建目录
hdfs dfs -mkdir -p /data/wc/input
#上传文件
hdfs dfs -D dfs.blocksize=1048576 -put data.txt /data/wc/input
# 运行
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output日志
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output
23/04/23 06:50:41 INFO input.FileInputFormat: Total input paths to process : 1
23/04/23 06:50:41 INFO mapreduce.JobSubmitter: number of splits:1
23/04/23 06:50:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1682257192920_0002
23/04/23 06:50:41 INFO impl.YarnClientImpl: Submitted application application_1682257192920_0002
23/04/23 06:50:41 INFO mapreduce.Job: The url to track the job: http://node03:8088/proxy/application_1682257192920_0002/
23/04/23 06:50:41 INFO mapreduce.Job: Running job: job_1682257192920_0002
23/04/23 06:50:53 INFO mapreduce.Job: Job job_1682257192920_0002 running in uber mode : false
23/04/23 06:50:53 INFO mapreduce.Job: map 0% reduce 0%
23/04/23 06:51:02 INFO mapreduce.Job: map 100% reduce 0%
23/04/23 06:51:10 INFO mapreduce.Job: map 100% reduce 100%
23/04/23 06:51:11 INFO mapreduce.Job: Job job_1682257192920_0002 completed successfully
23/04/23 06:51:11 INFO mapreduce.Job: Counters: 49
查看输出
# 查看输出
[root@node01 mapreduce]# hdfs dfs -ls /data/wc/output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2023-04-23 06:51 /data/wc/output/_SUCCESS
-rw-r--r-- 2 root supergroup 62 2023-04-23 06:51 /data/wc/output/part-r-00000
[root@node01 mapreduce]# hdfs dfs -cat /data/wc/output/part-r-00000
elite 1
hadoop 1
haoop 1
hbase 1
hello 3
hive 2
word 2
yarn 1