快速识别 SLI 指标的方法:VALET

SLI,Service Level Indicator,服务等级指标,其实就是我们选择哪些指标来衡量我们的稳定性。而 SLO,Service Level Objective,服务等级目标,指的就是我们设定的稳定性目标,比如“几个 9”这样的目标。
VALET 是 5 个单词的首字母,分别是 Volume、Availability、Latency、Error 和 Ticket。这 5 个单词就是我们选择 SLI 指标的 5 个维度。我们还是结合 trade_cart 这个例子,一起看一下每个维度具体是什么。
1、Volume- 容量
Volume(容量)是指服务承诺的最大容量是多少。比如,一个应用集群的 QPS、TPS、会话数以及连接数等等,如果我们对日常设定一个目标,就是日常的容量 SLO,对双 11 这样的大促设定一个目标,就是大促 SLO。对于数据平台,我们要看它的吞吐能力,比如每小时能处理的记录数或任务数。
2、Availablity- 可用性
Availablity(可用性)代表服务是否正常。比如,我们前面介绍到的请求调用的非 5xx 状态码成功率,就可以归于可用性。对于数据平台,我们就看任务的执行成功情况,这个也可以根据不同的任务执行状态码来归类。
3、Latency- 时延
Latency(时延)是说响应是否足够快。这是一个会直接影响用户访问体验的指标。对于任务类的作业,我们会看每个任务是否在规定时间内完成了。
因为通常对于时延这个指标,我们不会直接做所有请求时延的平均,因为整个时延的分布也符合正态分布,所以通常会以类似“90% 请求的时延 <= 80ms,或者 95% 请求的时延 <=120ms ”这样的方式来设定时延 SLO,熟悉数理统计的同学应该知道,这个 90% 或 95% 我们称之为置信区间。
因为不排除很多请求从业务逻辑层面是不成功的,这时业务逻辑的处理时长就会非常短(可能 10ms),或者出现 404 这样的状态码(可能就 1ms)。从可用性来讲,这些请求也算成功,但是这样的请求会拉低整个均值。
同时,也会出现另一种极端情况,就是某几次请求因为各种原因,导致时延高了,到了 500ms,但是因为次数所占比例较低,数据被平均掉了,单纯从平均值来看是没有异常的。但是从实际情况看,有少部分用户的体验其实已经非常糟糕了。所以,为了识别出这种情况,我们就要设定不同的置信区间来找出这样的用户占比,有针对性地解决。
4、Errors- 错误率
错误率有多少?这里除了 5xx 之外,我们还可以把 4xx 列进来,因为前面我们的服务可用性不错,但是从业务和体验角度,4xx 太多,用户也是不能接受的。或者可以增加一些自定义的状态码,看哪些状态是对业务有损的,比如某些热门商品总是缺货,用户登录验证码总是输入错误,这些虽不是系统错误,但从业务角度来看,对用户的体验影响还是比较大的。
5、Tickets- 人工介入
是否需要人工介入?如果一项工作或任务需要人工介入,那说明一定是低效或有问题的。举一个常见的场景,数据任务跑失败了,但是无法自动恢复,这时就要人工介入恢复;或者超时了,也需要人工介入,来中断任务、重启拉起来跑等等。
Tickets 的 SLO 可以想象成它的中文含义:门票。一个周期内,门票数量是固定的,比如每月 20 张,每次人工介入,就消耗一张,如果消耗完了,还需要人工介入,那就是不达标了。
Google 提供的,针对类似于 trade_cart 的一个应用服务,基于 VALET 设计出来的 SLO 的 Dashboard 样例,结合上面介绍的部分,就一目了然了。
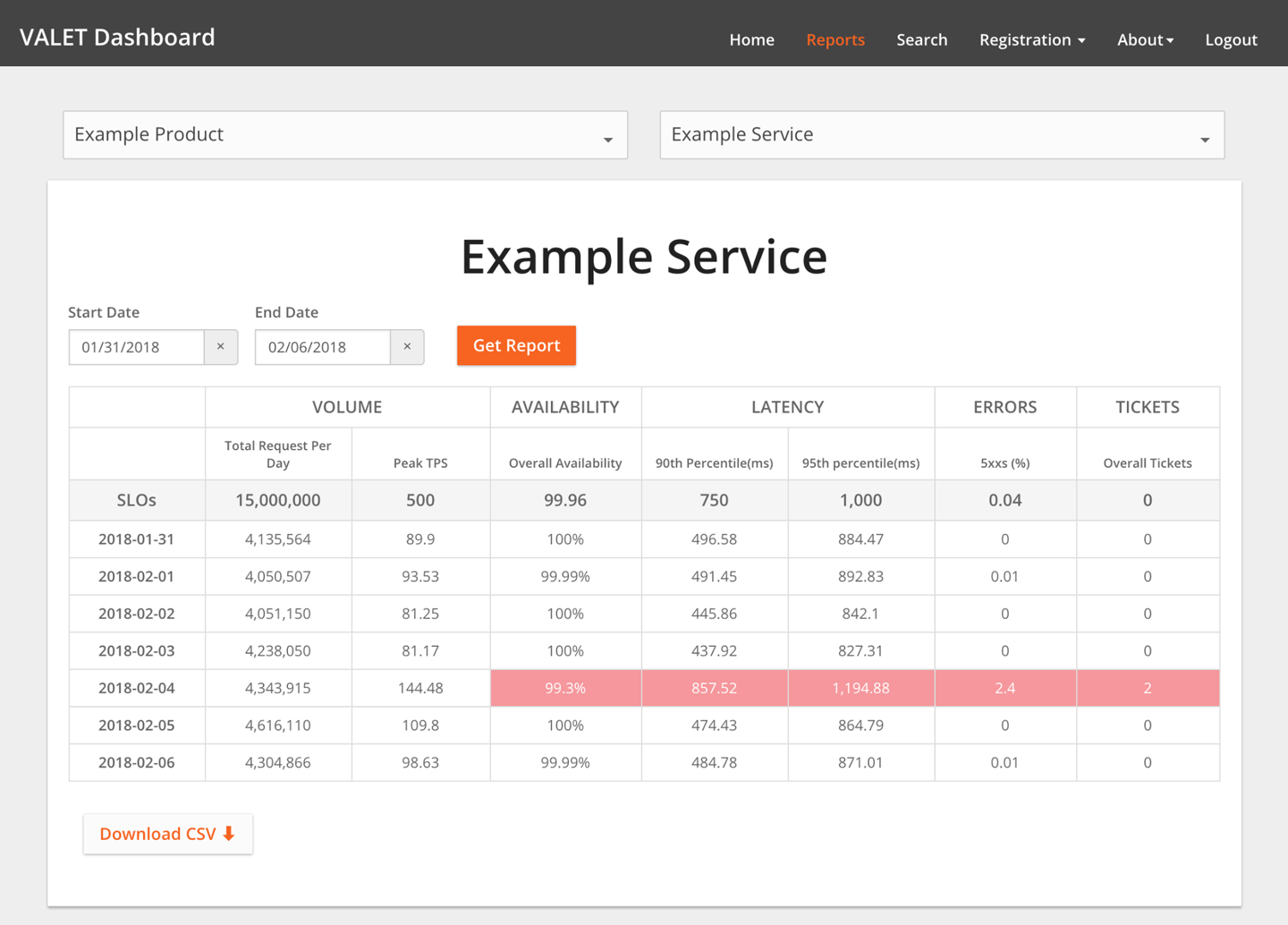
此文章为4月Day23 学习笔记,内容来源于极客时间《SRE 实战手册》,推荐该课程。