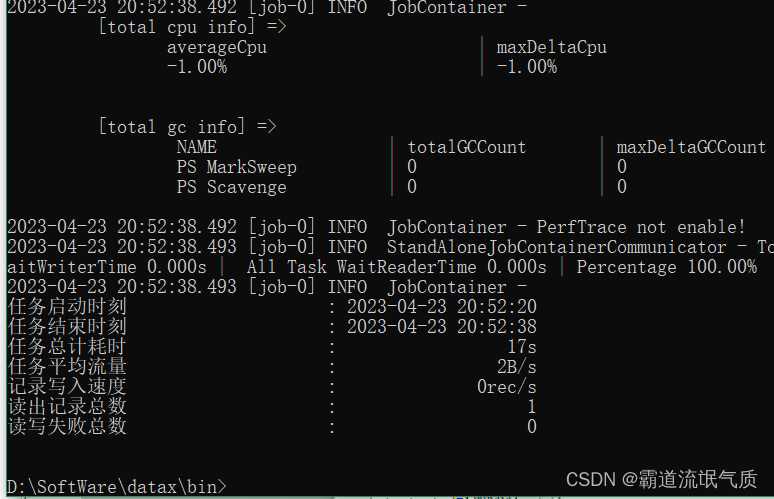
DataX-阿里开源离线同步工具在Windows上实现Sqlserver到Mysql全量同步和增量同步

场景
Kettle-开源的ETL工具集-实现SqlServer到Mysql表的数据同步并部署在Windows服务器上:
Kettle-开源的ETL工具集-实现SqlServer到Mysql表的数据同步并部署在Windows服务器上_etl实现sqlserver报表服务器_霸道流氓气质的博客-CSDN博客
上面讲过Kettle的使用,下面记录下阿里开源异构数据源同步工具DataX
DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、
HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
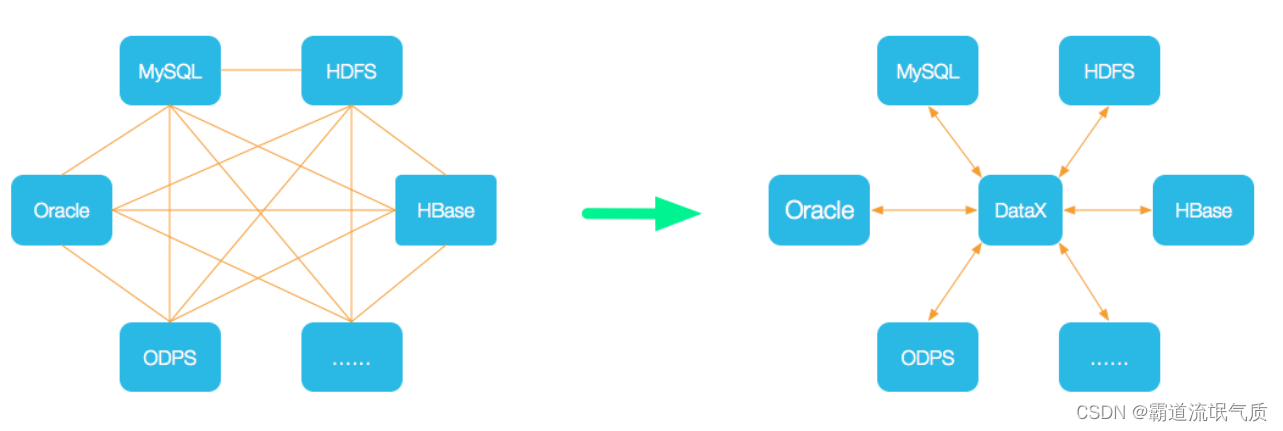
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,
DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,
只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。
目前每天完成同步8w多道作业,每日传输数据量超过300TB
DataX所支持的数据源
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
下面记录一个具体的示例-从Sqlserver同步数据到Mysql中,且表结构一样。
注:
博客:
霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主
实现
1、DataX在Windows上的安装
参考官网快速开始文档:
DataX/userGuid.md at master · alibaba/DataX · GitHub
安装并配置好所需要的环境依赖。

这里不需要自己编译,所以只配置了jdk1.8以及Python3的环境变量。
按照文档下载地址,下载DataX工具包
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz
下载之后解压即可。
2、启动并测试stream2stream数据转换
解压之后来到bin目录下,新建创建作业的配置文件stream2stream.json文件
修改json内容为
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": 10,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 5}}}
}这是官方提供的模板的示例json文件,用来自检是否成功配置和启动DataX。
然后在bin目录下打开cmd执行
python datax.py ./stream2stream.json等待执行完成没有提示报错,但是发现中文乱码
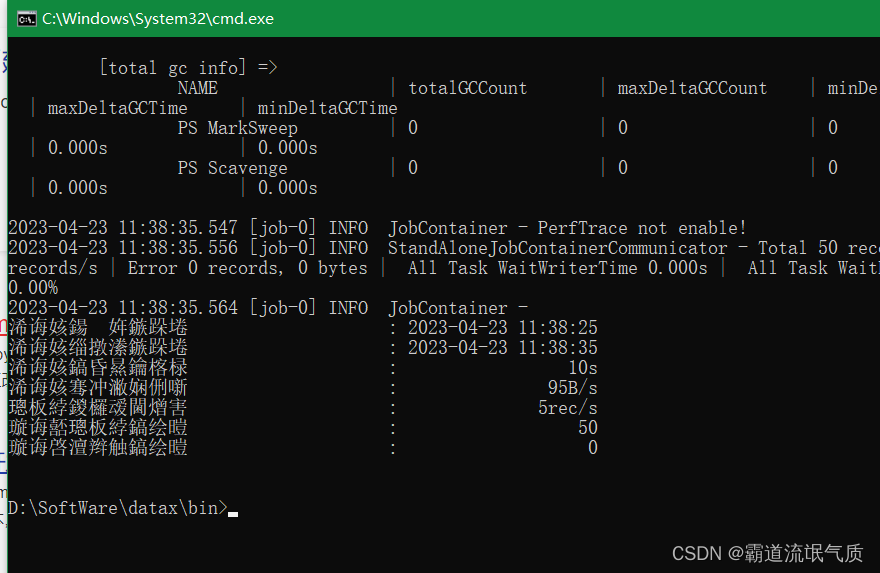
DataX命令框中文乱码需要设置编码格式,先在cmd中输入
chcp 65001然后再执行上面命令
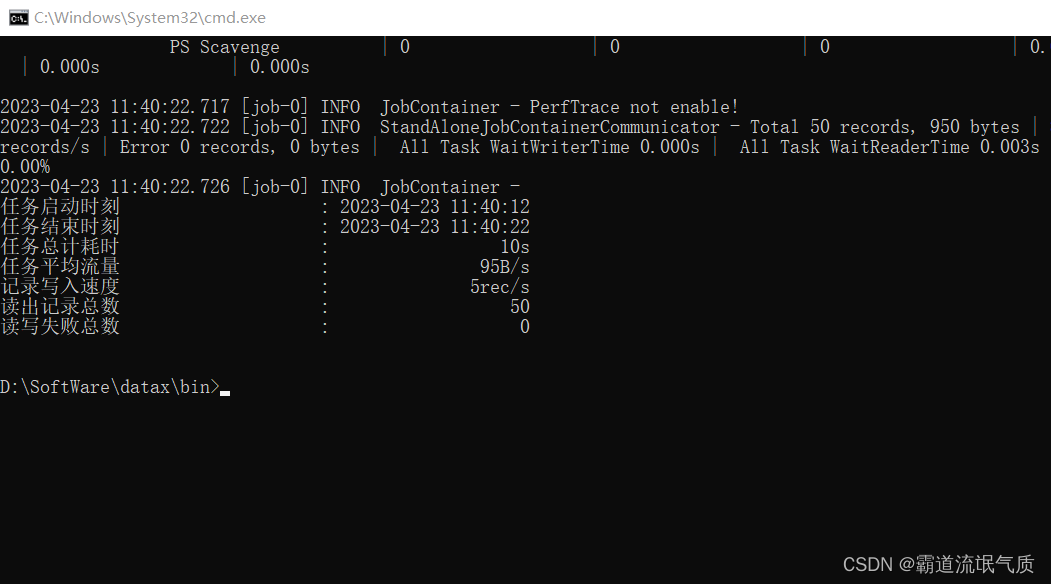
执行过程中的中文输出也不再乱码
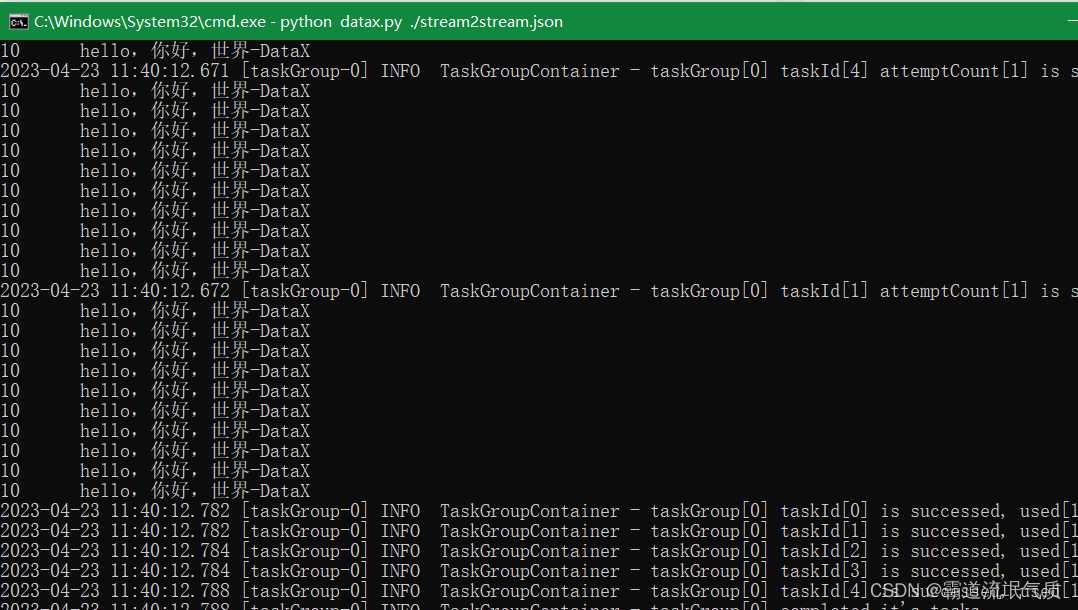
执行结果也不再乱码
3、获取不同数据源转换的json模板。
上面是从stream到stream的数据源转换,如果是其它数据源的json模板如何获取。
DataX提供了获取不同数据源转换的json模板获取的指令
可以通过命令查看配置模板:
python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
如何获取数据源的名称,比如这里从sqlserver读取,写入到mysql,那么获取json模板的命令:
python datax.py -r sqlserverreader -w mysqlwriter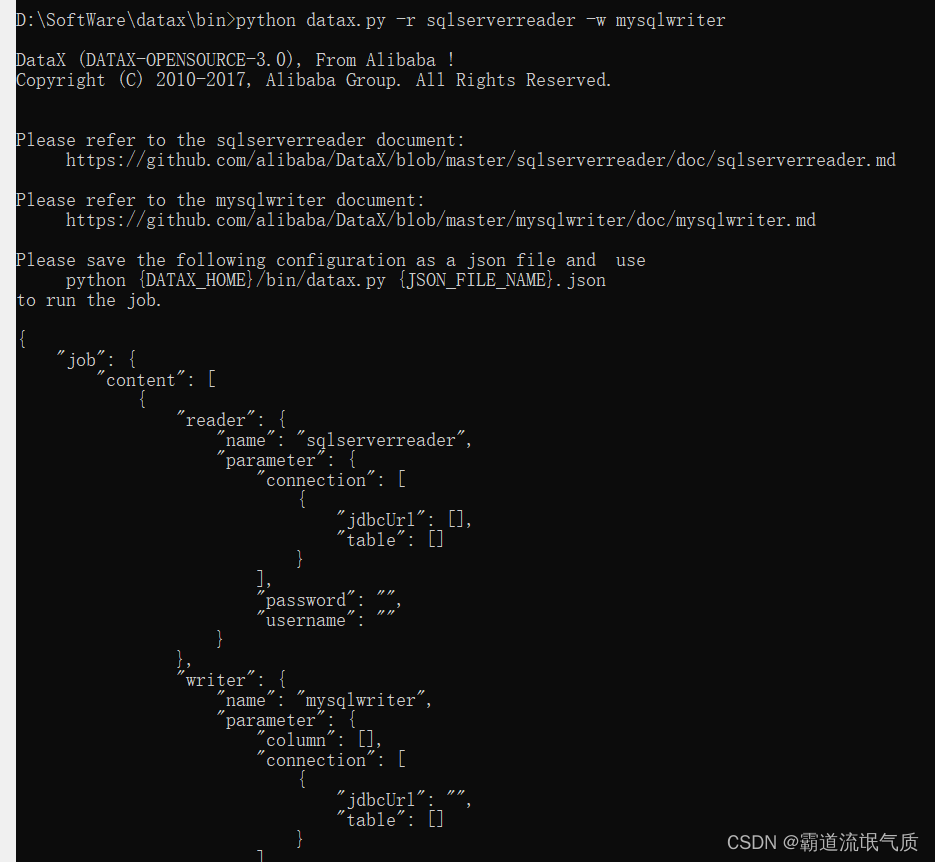
此时会返回一个sqlserver到mysql的json模板。
这是因为在其源码中目录就是这样叫的。
获取说可以直接点击进去里面的doc目录,查看示例的json文件内容
并且每个配置项的参数也有对应的说明
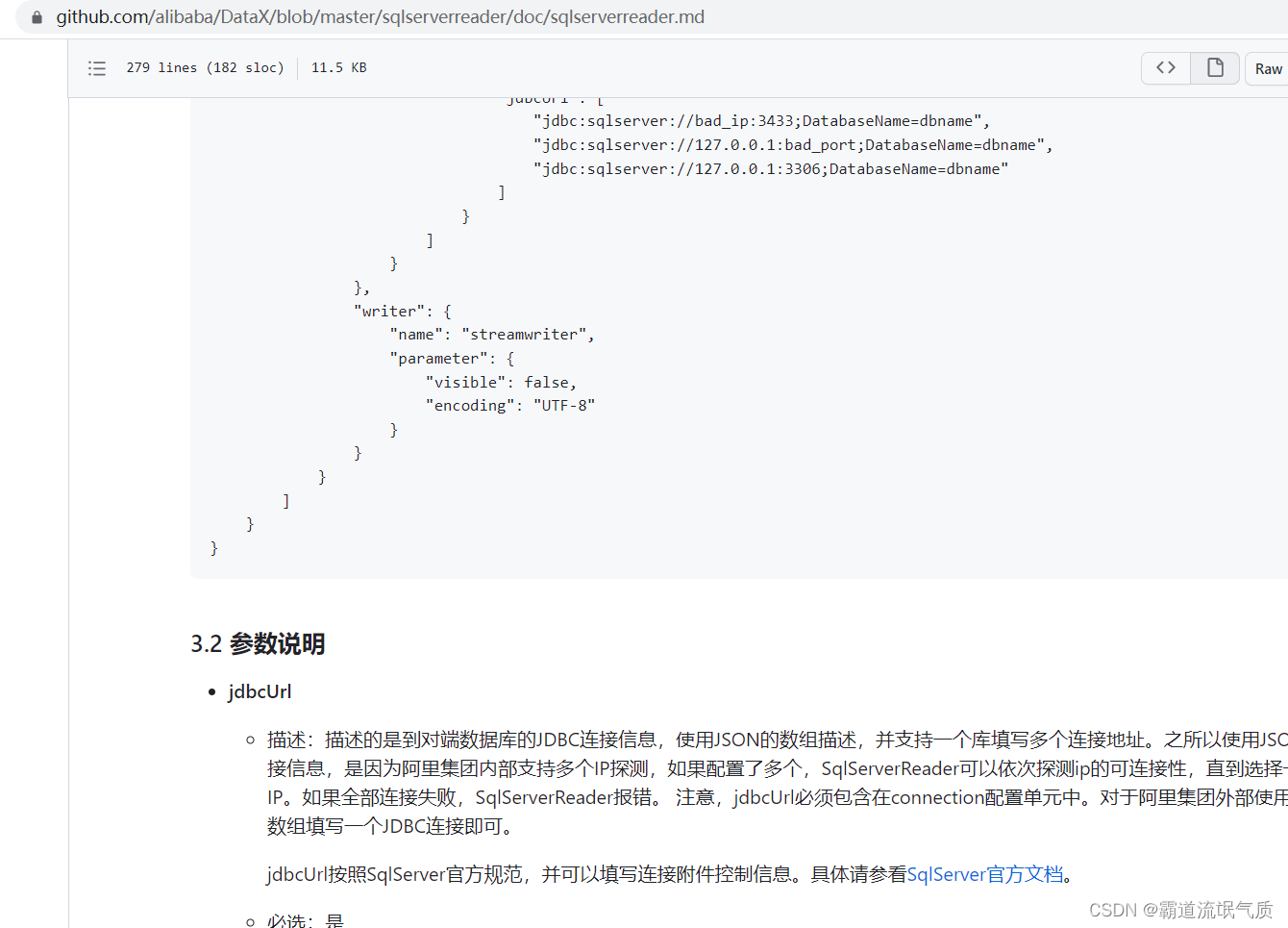
sqlserverreader参数说明
DataX/sqlserverreader.md at master · alibaba/DataX · GitHub
mysqlwriter参数说明
DataX/mysqlwriter.md at master · alibaba/DataX · GitHub
所以这里新建全量更新的json文件sqlserver2mysqlALL.json
{"job": {"content": [{"reader": {"name": "sqlserverreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:sqlserver://localhost:1433;DatabaseName=数据库名"],"table": ["表名"]}],"password": "改成自己的密码","username": "用户名","column": ["checkid","cardID","hphm","startTime","endTime","linenumber","cwgt","cwgtUL","cwgtJudge","cwkc","cwkcResult","cwkcUL","cwkcJudge","cwkk","cwkkResult","cwkkUL","cwkkJudge","cwkg","cwkgResult","cwkgUL","cwkgJudge","wkccJudge",]}},"writer": {"name": "mysqlwriter","parameter": {"column": ["checkid","cardID","hphm","startTime","endTime","linenumber","cwgt","cwgtUL","cwgtJudge","cwkc","cwkcResult","cwkcUL","cwkcJudge","cwkk","cwkkResult","cwkkUL","cwkkJudge","cwkg","cwkgResult","cwkgUL","cwkgJudge","wkccJudge",],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/数据库名?useUnicode=true&characterEncoding=gbk","table": ["表名"]}],"password": "密码","preSql": ["delete from vehicleresult"],"session": [],"username": "用户名","writeMode": "insert"}}}],"setting": {"speed": {"channel": "5"}}}
}注意这里的流程就是从sqlserver中读取指定列的数据,这里的column就是配置的那些列。
然后写入到mysql时需要预先执行一下删除语句,在preSql中配置的
delete from vehicleresult
vehicleresult是表名。然后写入模式是直接插入
然后执行以上json模板的命令
python datax.py ./sqlserver2mysqlALL.json即可实现全量更新。
注意事项,两边的数据结构包括类型、长度、是否非空等要保持一致。
比如sqlserver中某个字段不为空,存在空数据,但是mysql中对应字段设置为不为空,在同步时就会认定为脏数据进而同步失败。
上面全量更新结果
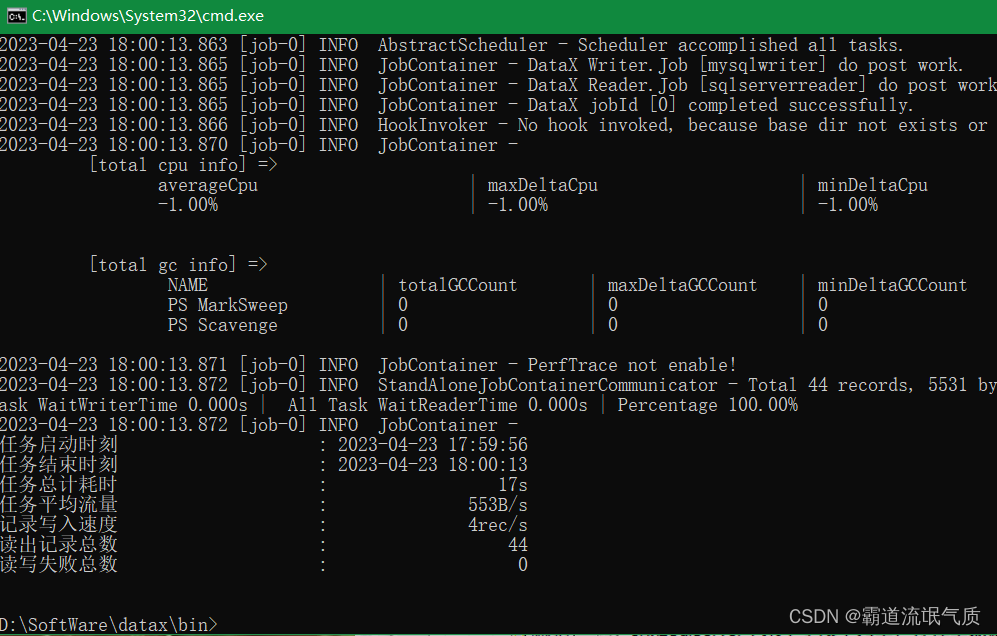
4、以上命令每执行一次,则进行一次全量更新,所以需要一个定时bat脚本来定时执行命令。
新建bat文件并修改内容为
#设置编码
chcp 65001
@echo off
title "同步数据"
set INTERVAL=15
timeout %INTERVAL%:Againpython datax.py ./sqlserver2mysqlALL.jsonecho %date% %time:~0,8%timeout %INTERVAL%goto Again以上内容代表每15秒执行一次
python datax.py ./sqlserver2mysqlALL.json将此bat放在bin下与json文件同级目录下,双击执行即可。
5、以上是全量更新,如何实现增量更新。
注意这里增量更新有条件限制,首先这里的数据没有删除只会新增和更新,而且更新只会更新当天的数据。
所以这里首先执行以上上面的全量更新,确保第一次对接将数据获取,然后后面用定时任务执行增量更新,只需要
查询和替换当前的数据即可。
另外得保证有日期时间字段,那么在读取数据和写入数据时就可以用where条件限制查询当前的数据。
另外这里的主键并不是自增的int型数据,不然也可以根据自增主键id进行增量更新。
这里的sqlserver是由三方系统提供且无法更改为需要的类型

修改上面的sqlserverreader添加where条件,查询当天的数据
Sqlserver中查询当天的数据
where datediff(day,startTime,getdate())=0其中startTime为时间字段。
Mysql中查询当天的数据
WHERE DATE(startTime) = CURDATE()所以修改上面的json文件为
{"job": {"content": [{"reader": {"name": "sqlserverreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:sqlserver://localhost:1433;DatabaseName=数据库名"],"table": ["表名"]}],"password": "改成自己的密码","username": "用户名","where": "datediff(day,startTime,getdate())=0","column": ["checkid","cardID","hphm","startTime","endTime","linenumber","cwgt","cwgtUL","cwgtJudge","cwkc","cwkcResult","cwkcUL","cwkcJudge","cwkk","cwkkResult","cwkkUL","cwkkJudge","cwkg","cwkgResult","cwkgUL","cwkgJudge","wkccJudge",]}},"writer": {"name": "mysqlwriter","parameter": {"column": ["checkid","cardID","hphm","startTime","endTime","linenumber","cwgt","cwgtUL","cwgtJudge","cwkc","cwkcResult","cwkcUL","cwkcJudge","cwkk","cwkkResult","cwkkUL","cwkkJudge","cwkg","cwkgResult","cwkgUL","cwkgJudge","wkccJudge",],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/数据库名?useUnicode=true&characterEncoding=gbk","table": ["表名"]}],"password": "密码","preSql": ["delete from 表名 WHERE DATE(startTime) = CURDATE();"],"session": [],"username": "root","writeMode": "insert"}}}],"setting": {"speed": {"channel": "5"}}}
}此时再用bat脚本定时执行即可,定时时间自行修改上面的15参数。
然后再新增一条今天的数据测试同步效果。
将上面增量更新的json命名为sqlserver2mysqlAdd.json