数据迁移实践 | MySQL到ClickHouse,HTAP黄金搭档

MySQL是世界上最流行的开源数据库,也是OLTP界的顶流,但是对于OLAP分析型业务场景的能力太弱。ClickHouse是最近几年数仓OLAP分析查询领域的黑马,当红炸子鸡,有意思的是天然兼容MySQL语法。所以很多用户喜欢OLTP放MySQL,OLAP放ClickHouse,中间加一层数据同步,称之为HTAP黄金搭档。
我司的DBMotion是在线数据迁移SaaS服务,也可以docker run一键式本地化运行。对于MySQL迁移同步到ClickHouse,提供了结构迁移/全量初始化/增量同步/数据校验功能支持,并且为实时数据同步提供了精准一致性查询视图。里面一些功能点的设计,可以分享给大家,供参考。
▌全量初始化性能
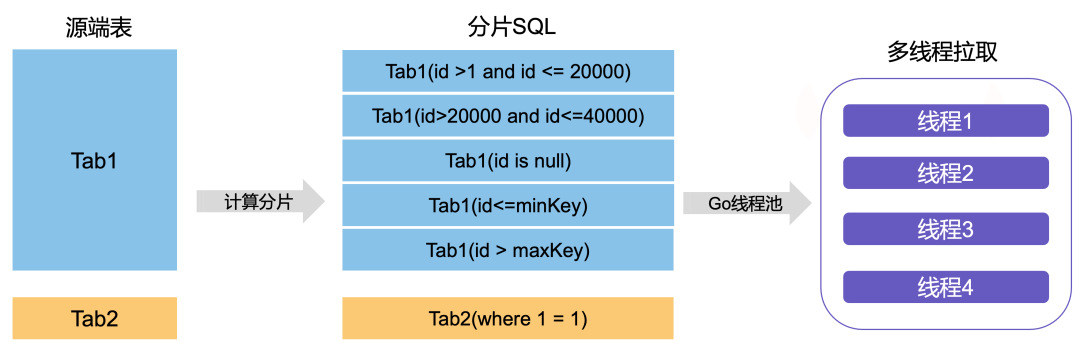
ClickHouse全量初始化,往往是最耗时的,一般迁移工具都会采用多线程并发模式去拉取源端数据,然后并发load到目标端,多线程可以是行级并发或表级并发,DBMotion是采用的行级并发,因为如果有一些超大表,表级并发会受限于这些大表,我们处理的流程大致如下:
-
dbmotion核心模块会设定迁移任务的工作线程数,表数据切片行数split-rows,fetch批次大小等配置
-
每张表,根据总行数,split-rows估算出切片数量,根据PK/唯一键或时间/数据字段,计算每个分片的where边界,最终会获得一张切片list
-
将切片均匀分发给多线程去消费,每个线程负责这个切片的数据拉取和数据装载,直到所有切片都完成
一般我们切片大小设置为50000行,如果是超小表不足一个切片,这个线程会立刻完成,再处理其他切片,经过实际测试,每个线程的处理工作是比较均匀的,吞吐量基本可以打满主机网卡(生产注意流控)。
▌全量断点续传
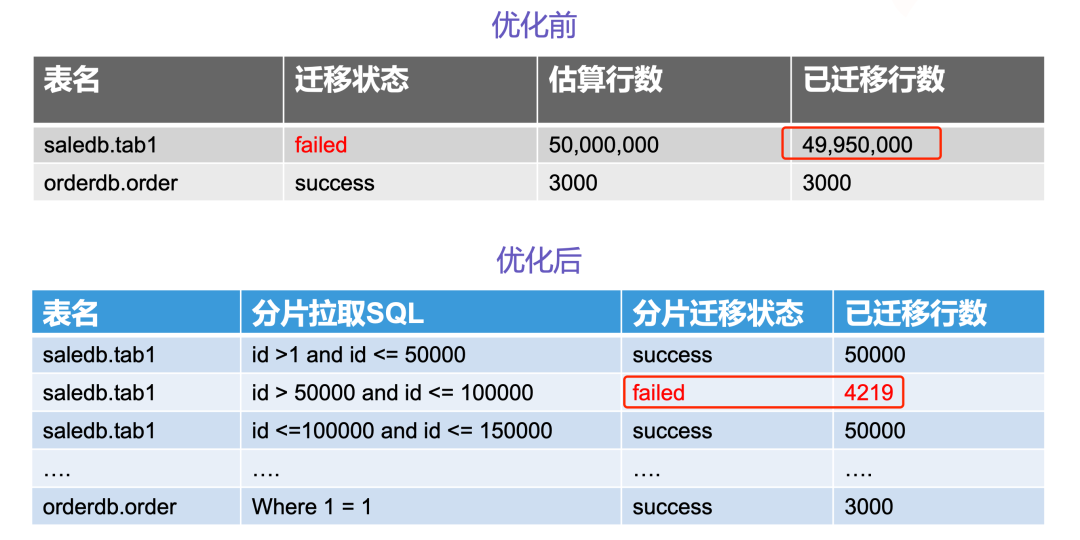
只说增量需要断点续传,现在全量也要断点续传?其实这个需求是非常合理的,比如说一张表有5千万行,我初始化了4995万行的时候,机器网络抖了下,失败了,就差这5万行了,难道重新来一遍?
写过SQL的知道,游标fetch数据时,你是不知道他具体到了表的哪一行的,重新查询是没法从断点开始的。不过得益于全量切片的并发设计,我们保留了每一个切片的元数据,对于切片数据同步的行数,状态做了异步刷新。当一个迁移任务重新运行时,可以只处理失败的切片。由于切片粒度一般是50000行以内,少量失败切片处理起来会非常快,这个基本类似故障的断点续接了。
▌ClickHouse增量同步
MySQL增量数据的获取都是基于binlog event解析,根据他的前印象后印象,拼凑同步SQL,中间引入并发线程消费,控制好进度位点,DDL对齐,操作幂等,基本不会有什么问题。但是这套方式换到ClickHouse就很成问题,因为ClickHouse的常用存储引擎是LSM结构的MergeTree,而且是列存储,适合大批量插入,不适合update和delete。
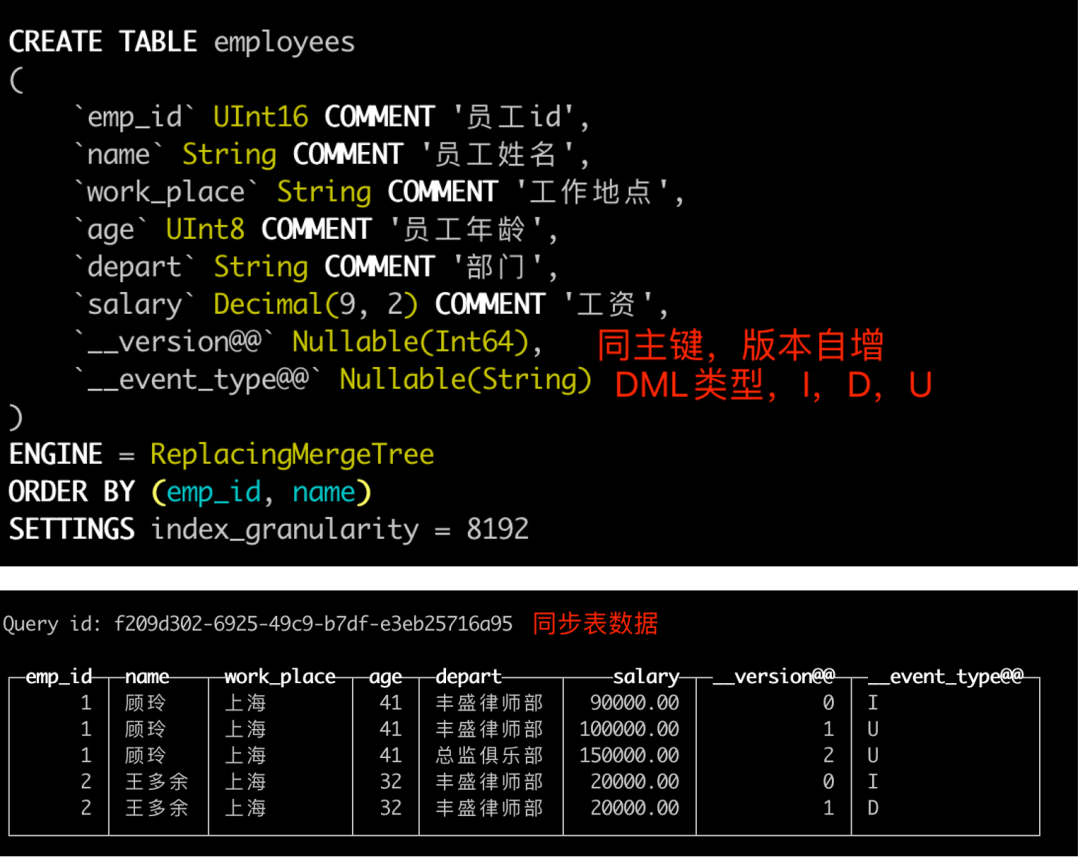
你看他的update语句都是alter xxx update xxx = xxx,这种反常态的语法,骨子里就是要你别更新,别删除。而MySQL的增量数据,就是离散的I/U/D,没法控制的。如果硬套上ClickHouse的DML语法,同步性能是暴差的,也会引起很多无谓的part合并,所以我们是结合ClickHouse的ReplacingMergeTree解决了这个问题。
-
binlog解析的所有数据,无论是u/d/i,都拼凑成insert语句,新增版本和event类型两个隐含字段,所有的DML都是以插入方式到达CK,适当的积累下批量,性能指标会很不错
-
同一行数据,会因为更新删除而产生多行数据,ReplacingMergeTree的分区合并会自动滤重,保留最新版本的数据,而这个版本号是我们按照事务操作的顺序投放进来的,合乎逻辑
-
D类型的数据,DBMotion会有后台任务异步批量处理
-
如果要使用partition分区,需要注意一点,ReplacingMergeTree只能保证一个分区内的合并去重,多分区需要保证分区维度和主键维度的一致性,否则最终结果会是重复的
▌查询一致性
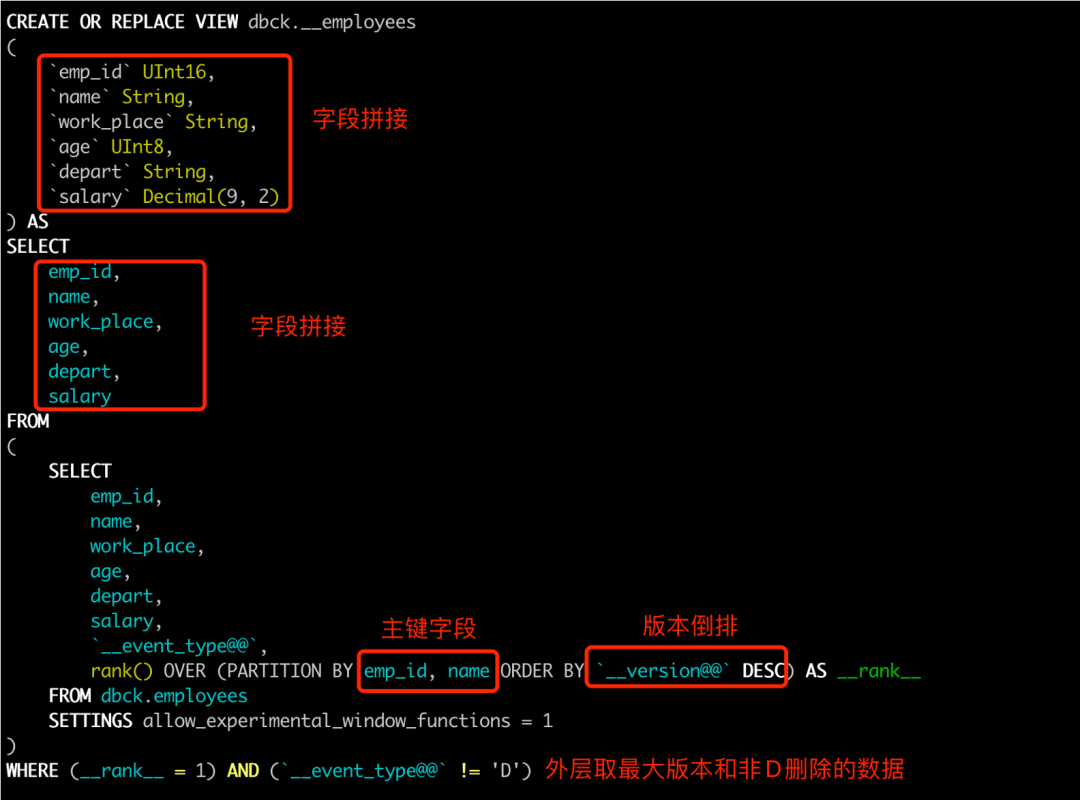
对于上述经过增量同步的表,如果业务需要使用,还是得写段SQL的,重复数据,取其中版本最大的一条,并过滤掉Delete类型的数据。如果每张表你都要套这么大的SQL,会很麻烦,在此DBMotion会自动为同步表提供了查询视图,相信ClickHouse强悍的计算能力,处理这种分析函数,是so easy的。
▌最快的ClickHouse数据装载姿势
MySQL到CK,只是分析数据的冰山一角,很多页面、事件、日志、用户行为数据才是最大量的。要知道CK的主业,是根据分析师的模型跑大SQL,数据装载入库是迫不得已的副业。CK为这个副业也是绞尽脑汁,提供了很多方法。最有意思的当属clickhouse-local,官方文档对这个工具的解释是你无需安装启动clickhouse server端,仅仅用clickhouse-local就可以解析处理本地文件,它和clickhouse server有相同的核心。
我们可以看看下面的示例:
echo "1\\t2023-4-21\\n2\\t2024-12-04\\n3\\t2025-9-07"| \\clickhouse-local -S "id Int64,thetime String" -N "cktable" \\-q "CREATE TABLE cklocal (id Int64,thetime Date) ENGINE = MergeTree() \\PARTITION BY toYYYYMM(thetime) ORDER BY id;\\INSERT INTO TABLE cklocal SELECT id,thetime FROM cktable;" --path /mydir
然后看看/mydir下出现了什么:
# ls -l /mydirtotal 0drwxr-xr-x. 4 root root 34 Apr 20 14:52 datadrwxr-xr-x. 4 root root 150 Apr 20 14:52 metadatadrwxr-xr-x. 3 root root 17 Apr 20 14:52 storedrwxr-xr-x. 2 root root 6 Apr 20 14:52 user_defined
clickhouse-local可以直接将输入数据生成clickhouse server可以识别的数据文件,而这些数据文件挂载到server端,是直接能用的。
按照这个思路,我们可以将clickhouse-local分发给应用端,由他们事先生成好数据文件。这样算力消耗就分散在众多的业务机器,而不是服务端。后面再将这些文件,按照一定的规则上传copy到server端并挂载,从而实现了海量数据的快速装载。
从小编的使用经验看,clickhouse的内功是相当不错的,丰富的存储引擎,高压缩列存,数据预处理,强大的功能函数,爆表的性能等等,但外功就不是一般的差劲。运维管理一个多副本,分布式集群还是要花相当的功夫的,数据扩容伸缩也很原始。如果这些短板一直存在,后续被rockstar反超应该不会太久。最后来句硬广:上squids.cn,品全网ZUI低价数据库云服务,也包含ClickHouse哦!
更多内容请关注“云原生数据库”