LangChain与大型语言模型(LLMs)应用基础教程:记忆力组件


如果您还没有看过我之前写的两篇博客,请先看一下,这样有助于对本文的理解:
LangChain与大型语言模型(LLMs)应用基础教程:Prompt模板
LangChain与大型语言模型(LLMs)应用基础教程:信息抽取
LangChain与大型语言模型(LLMs)应用基础教程:角色定义
在默认情况下Chain和LLM都是无状态的,这意味着它们独立地处理每个传入的prompt(底层 LLM 和聊天模型也是如此),因此它们不具有记住上下文的能力,但是在很多应用场景中我们需要LLM具有记住上下文的能力,这样会使我们的机器人看起来更加“聪明”,从而给用户带来更好的用户体验。今天我们来介绍几种在LangChain中常用的记忆力组件。
首先我们需要安装如下的python包:
pip -q install openai langchain huggingface_hub transformers1. ConversationBufferMemory
这是最简单的内存记忆力组件,它的功能是直接将用户和机器人之间的聊天内容记录在内存中。下面我们看一个例子:
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
import os
#你申请的openai的api_key
os.environ['OPENAI_API_KEY'] = 'xxxxxx'#定义llm
llm = OpenAI(model_name='text-davinci-003', temperature=0, max_tokens = 256)#定义记忆力组件
memory = ConversationBufferMemory()#定义chain
conversation = ConversationChain(llm=llm, verbose=True, memory=memory
)这里我们首先定义了一个openai的语言模型llm, 一个记忆力组件ConversationBufferMemory,和一个chain, Chain是Langchain中的核心组件,llm必须和Chain结合在一起才能正常工作。接下来就开始我们和openai语言模型的聊天:
print(conversation.predict(input='你好,我是王老六'))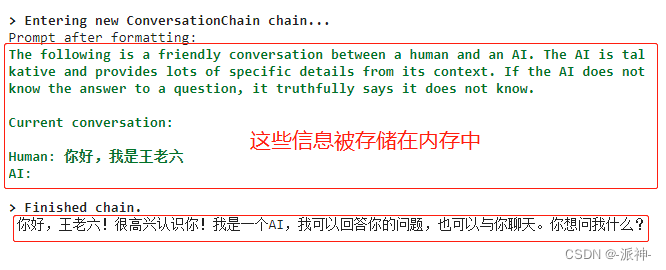
这里我们看到在内存中存放了两部分信息,首先是一个前缀信息:The following is ....,然后是机器人和用户之间的聊天内容。这里的前缀信息有助于让机器人明确自己的角色定义,从而限制机器人不能随心所欲的回答用户提出的问题。
print(conversation.predict(input='你叫什么名字啊?'))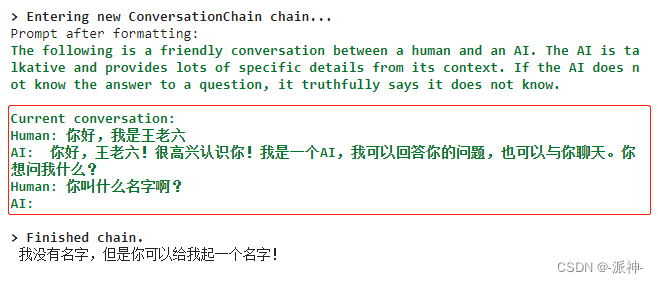
print(conversation.predict(input="那就叫你大聪明吧,怎么样?")) 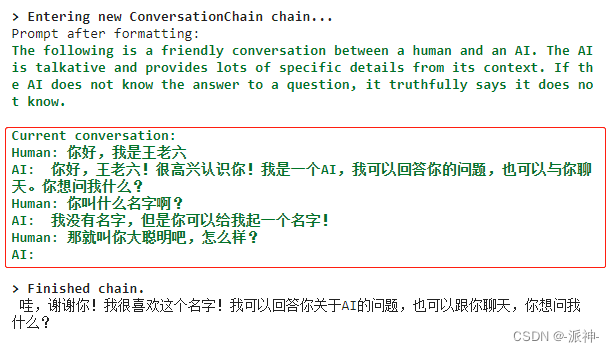
print(conversation.predict(input="你还记得我叫什么名字吗?")) 
这里我们注意到我们和机器人之间的多轮的对话内容全部被自动保存在了内存中。这样机器人就有了记忆力,它能记住我之前说过的话。
2. ConversationBufferWindowMemory
ConversationBufferWindowMemory组件与之前的ConversationBufferMemory组件的差别是它增加了一个窗口参数,它的作用是可以指定保存多轮对话的数量:
#定义openai的语言模型
llm = OpenAI(model_name='text-davinci-003', temperature=0, max_tokens = 256)#定义内存组件,k=2表示只保存最近的两轮对话内容
window_memory = ConversationBufferWindowMemory(k=2)#定义chain
conversation = ConversationChain(llm=llm, verbose=True, memory=window_memory
)这里ConversationBufferWindowMemory的参数k=2表示在内存中只保存最近的2轮对话内容,因此更早的对话内容将被抛弃掉。
print(conversation.predict(input='你好,我是王老六'))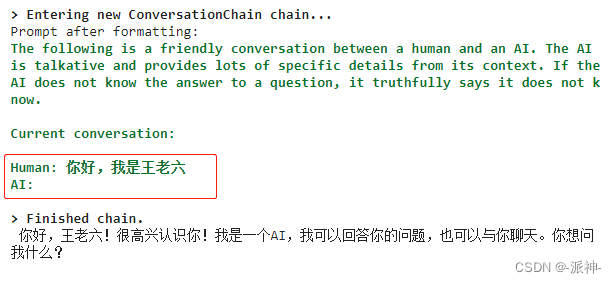
print(conversation.predict(input='你叫什么名字啊?')) 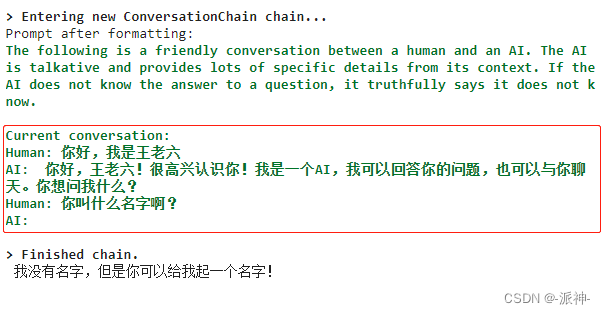
print(conversation.predict(input='那就叫你大聪明吧,怎么样?')) 
print(conversation.predict(input='你还记得我叫什么吗?')) 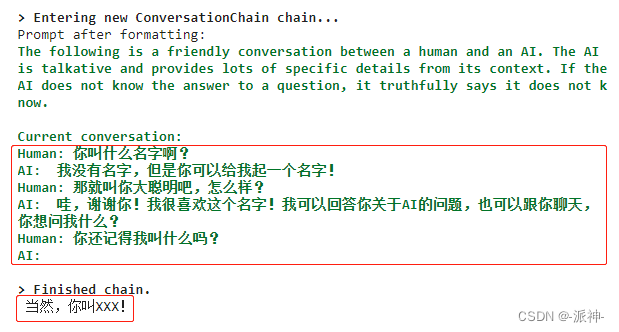
这里我们观察到,在内存中只保留了Human-AI,Human-AI两轮对话内容再加当前用户提出的问题。更早之前的Human-AI的对话内容会被抛弃掉,所以最后机器人不记得我叫什么名字了。
3. ConversationSummaryMemory
与ConversationBufferMemory不同,ConversationSummaryMemory它不会将用户和机器人之前的所有对话都存储在内存中。它只会存储一个用户和机器人之间的聊天内容的摘要,这样做的目的可能是为了节省内存开销和token的数量,因为像openai这样的语言模型是按token数量来收费的,所以能省则省。
#定义openai的语言模型
llm = OpenAI(model_name='text-davinci-003', temperature=0, max_tokens = 256)
#定义内存组件
summary_memory = ConversationSummaryMemory(llm=OpenAI())
#定义Chain
conversation = ConversationChain(llm=llm, verbose=True, memory=summary_memory
)这里我们将内存组件换成了ConversationSummaryMemory,它会在内存中产生聊天内容的摘要信息。
print(conversation.predict(input='你好,我是王老六')) 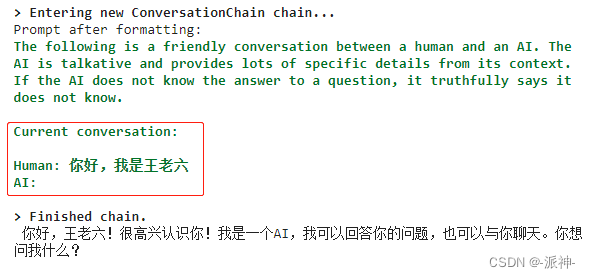
print(conversation.predict(input='你叫什么名字啊?'))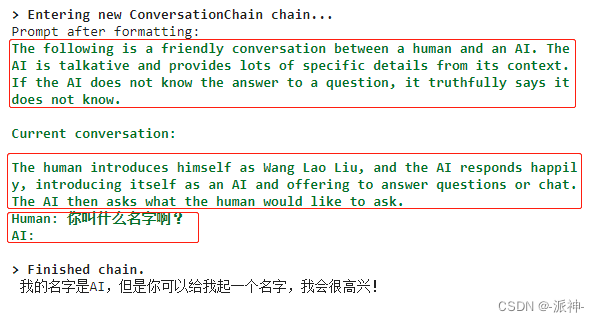
这里我们看到在内存中会保留前缀信息,之前多轮对话的摘要信息,以及用户当前提出的问题这三部分内容。
print(conversation.predict(input='那就叫你大聪明吧,怎么样?')) 
print(conversation.predict(input='你还记得我叫什么吗?'))
4. ConversationSummaryBufferMemory
ConversationSummaryBufferMemory结合了前面的ConversationBufferWindowMemory,ConversationSummaryMemory两种工作方式,即在内存中保留一部分聊天内容的摘要,和一部分的多轮聊天内容,但是要在内存中保留多少轮聊天内容,这取决于参数max_token_limit,如果将max_token_limit设置为较小的值时,那么大部分之前的聊天内容都被转换成了摘要,少部分的聊天内容被保存下来,相反当max_token_limit设置为较大的值时,小部分的之前聊天内容被转换成摘要,而大部分聊天内容被保留下来。
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
import osos.environ['OPENAI_API_KEY'] = 'xxxxx'llm = OpenAI(model_name='text-davinci-003', temperature=0, max_tokens = 256)memory = ConversationSummaryBufferMemory(llm=OpenAI(), max_token_limit=256) conversation = ConversationChain(llm=llm, memory=memory, verbose=True
)这里我们将max_token_limit设置为256,表示当我们多轮聊天内容的prompt长度超过256时,较早的聊天内容将会被转换成摘要,同时小于256个token的聊天内容会被保留下来。
print(conversation.predict(input='你好,我是王老六'))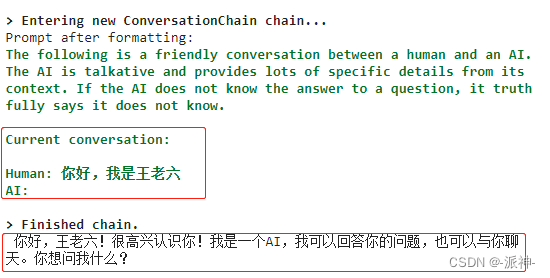
print(conversation.predict(input='你叫什么名字啊?')) 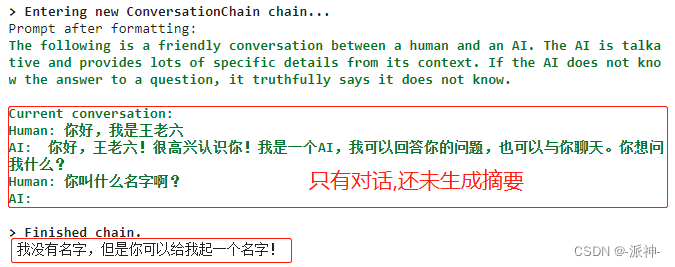
print(conversation.predict(input='我给你取个名字叫大聪明吧,怎么样?'))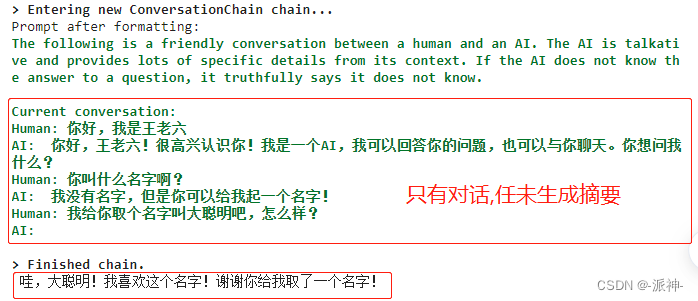
print(conversation.predict(input='你还记得我叫什么吗?'))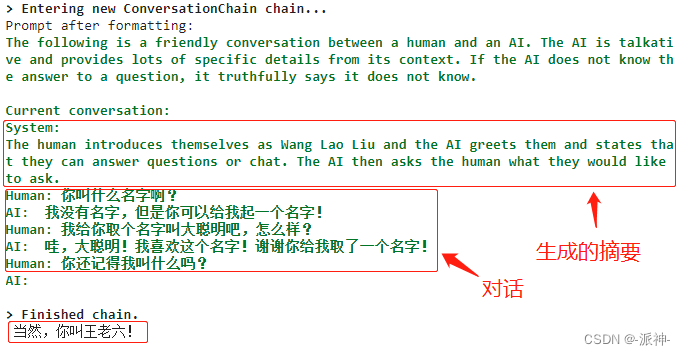
print(conversation.predict(input='你还记得我给你起的名字吗?'))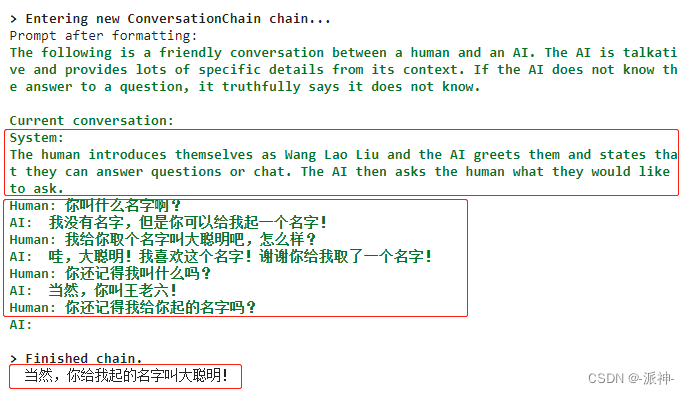
print(conversation.predict(input='我生病了,肚子疼,还呕吐发烧,你说我是自己吃点药对付一下呢还是去医院看一下比较好?'))
从上述多伦聊天内容中我们可以发现,随着聊天轮次的增加,内存中的摘要信息量也在增加,而内存中的多轮聊天内容的长度被限制在256个token,当有新的聊天内容进到内存中后,较早的聊天内容将会被转换成摘要从而被踢出内存中的多伦聊天记录。
5.ConversationKGMemory
我们知道像ChatGPT这样的LLM最大的问题是会“产生幻觉(hallucinate)”,也就是当llm不知道正确答案的情况下,往往会天马行空自由发挥从而导致llm给出了完全不正确的答案,为了避免llm产生幻觉,Langchain提供了ConversationKGMemory组件即“对话知识图谱记忆”组件,该组件可以从和用户的对话中提取出知识图谱信息,即一些核心的关键信息,这些信息比之前的ConversationSummaryMemory组件所保存的信息更为精简。llm将会严格依据知识图谱的中的相关内容来回答用户的问题,从而避免产生幻觉。
from langchain import OpenAI
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationKGMemoryllm = OpenAI(temperature=0)template = """下面是一段人与AI的友好对话。 人工智能很健谈,并根据其上下文提供了许多具体细节。
如果 AI 不知道问题的答案,它会如实说它不知道。 AI 仅使用“相关信息”部分中包含的信息,不会产生幻觉。相关信息:{history}对话内容:
Human: {input}
AI:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=template
)conversation_with_kg = ConversationChain(llm=llm, verbose=True, prompt=prompt,memory=ConversationKGMemory(llm=llm)
)这里我们创建了一个prompt模板,模板中有三部分信息:前缀信息, 相关信息,对话内容。前缀信息之前已经介绍过,这里不再说明,相关信息指的是从之前的多轮对话中提取出来的知识图谱信息,即精简的核心关键信息,对话内容则只保留用户当前所提出的问题。
conversation_with_kg.predict(input="你好")
conversation_with_kg.predict(input="我叫大神,我有一位朋友叫小明,他是一位宠物医院的医生。") 
conversation_with_kg.predict(input="小明是做什么的?") 
conversation_with_kg.predict(input="小明的爸爸也是一位宠物医生")
conversation_with_kg.predict(input="不过你小明的妈妈是位老师")
conversation_with_kg.predict(input="小明的哥哥是个老板")
conversation_with_kg.predict(input="小明的妈妈是做什么的?")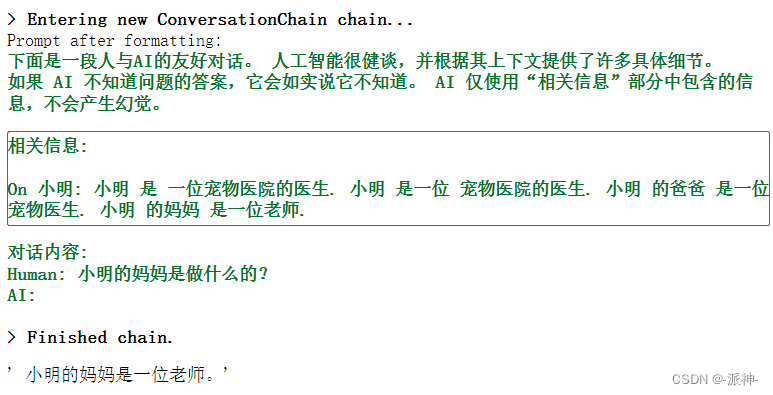
6.Entity Memory
在自然语言处理(NLP)技术中一项基本的功能就是:命名实体识别(Named Entity Recognition,简称NER)又称作专名识别、命名实体,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。Langchain提供的实体记忆(Entity Memory)组件能自动提取AI与人类交互过程中的实体信息,并将其以字典的形式保存在内存中。实体的正确识别能帮助AI能更准确的回答人类提出的关于实体的相关问题。下面我们来看一个例子:
from langchain import OpenAI, ConversationChain
from langchain.chains.conversation.memory import ConversationEntityMemory
from langchain.chains.conversation.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from pydantic import BaseModel
from typing import List, Dict, Any这里我们会使用一个ENTITY_MEMORY_CONVERSATION_TEMPLATE的模板,该模板为内存记忆的固定格式,下面我们看一下该模板的主要内容:
## The propmpt
print(ENTITY_MEMORY_CONVERSATION_TEMPLATE.template)
我们将其翻译成中文:
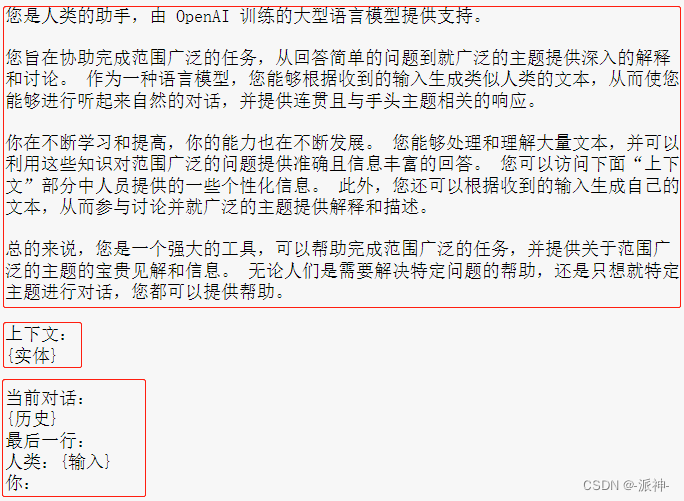
该模板基本上也是由3部分组成:前缀信息, 上下文,历史聊天信息,其中,“上下文”中记录的是历史聊天信息中提取出来的实体信息。
conversation.predict(input="你好,我家的小狗生病了怎么办?") 
conversation.predict(input="我突然想起来我有一个朋友叫小明,他是一位宠物医生。")
conversation.predict(input="可我听说他只会给小猫看病,不会给小狗看病,怎么办?")
conversation.predict(input="我还是去找小王吧,他是一个更专业的兽医。") 
conversation.predict(input="请问小明会给小狗看病吗?")
通过上述简单的几轮对话,我们看到聊天记录中的实体信息被提取出来,并且AI能够根据实体信息来准确回答我的问题。下面我们看一下实体信息中的完整内容:
from pprint import pprint
pprint(conversation.memory.entity_store.store)
总结
今天我们学习了Langchain提供的6种记忆力组件它们分别是:
- ConversationBufferMemory
- ConversationBufferWindowMemory
- ConversationSummaryMemory
- ConversationSummaryBufferMemory
- ConversationKGMemory
- Entity Memory
它们有着各自不能的功能和特点,根据不同的应用场景我们可以选择不同的记忆力组件,当我们开发一个与AI交互的应用程序时选择正确的记忆力组件能够成倍的提高AI的工作效率,同时让AI在回答人类的问题时更加准确,自然,而不会产生幻觉。
参考资料
LangChain官方文档