GDB调试实验

一、实验准备
在 Linux 环境软件开发中,GDB 是调试 C 和 C++ 程序的主要工具。本次实验围绕着GDB常用的调试操作进行。
1、设置断点的意义
当我们想查看变量内容,堆栈情况等等,可以指定断点。程序执行到断点处会暂停执行。break 命令用来设置断点,缩写形式为b。设置断点后,以便我们更详细的跟踪断点附近程序的执行情况。
2、C源代码准备
//test.c
#include <stdio.h>void judge(int num){if ((num & 1) == 0){printf("%d is even\\n",num);return;}else{printf("%d is odd\\n",num);return;}
}int main(int argc, char *argv[]){judge(0);judge(1);judge(4);return 0;
}注意:要调试C/C++的程序,首先在编译时,要使用gdb调试程序,在使用gcc编译源代码时必须加上“-g”参数。保留调试信息,否则不能使用GDB进行调试。
gcc -g test.c -o test
二、实验内容
1、通过行号设置断点
break [行号] 或简写为 b [行号]
break 行号,断点设置在该行开始处,注意:该行代码未被执行
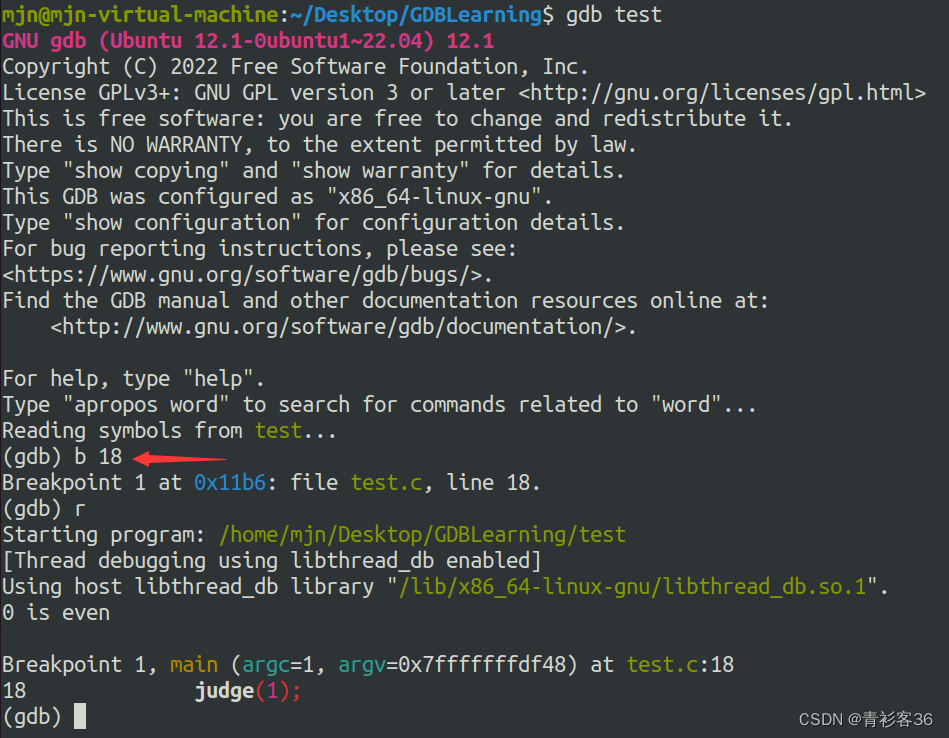
如果有多个源文件的话,也可以使用“文件名:行号”的形式设置断点。示例如下:
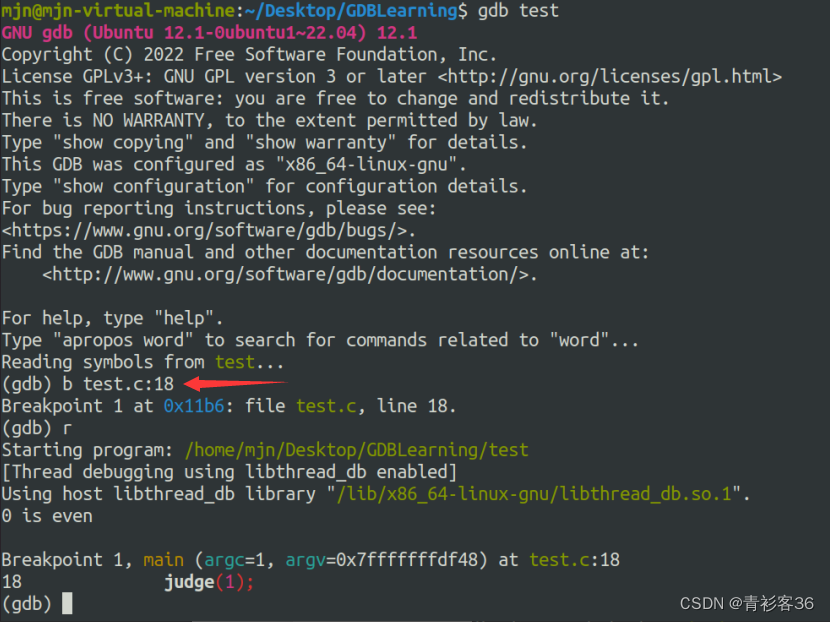
上图中的(gdb) b test.c:18是设置了断点。断点的位置是test.c文件的18行。使用r命令执行脚本时,当运行到18行时就会暂停。注意:该行代码未被执行。
2、通过函数设置断点
break [函数名] 或简写为 b [函数名]
break 函数名,断点设置在该函数的开始处,断点所在行未被执行:
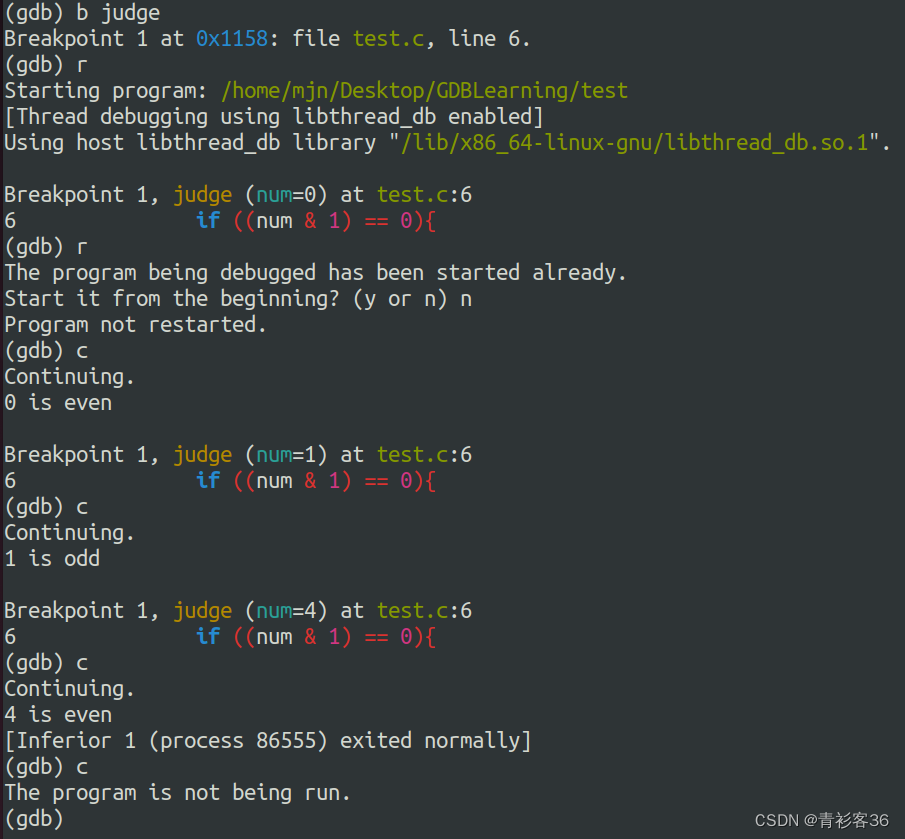
如果按上面的方法设置断点后,每次执行到断点位置都会暂停。然而,有时候我们只想在指定条件下才暂停。这时候可以根据条件设置断点。设置条件断点的形式,就是在设置断点的基本形式后面增加if条件。示例如下:
b 6 if num > 0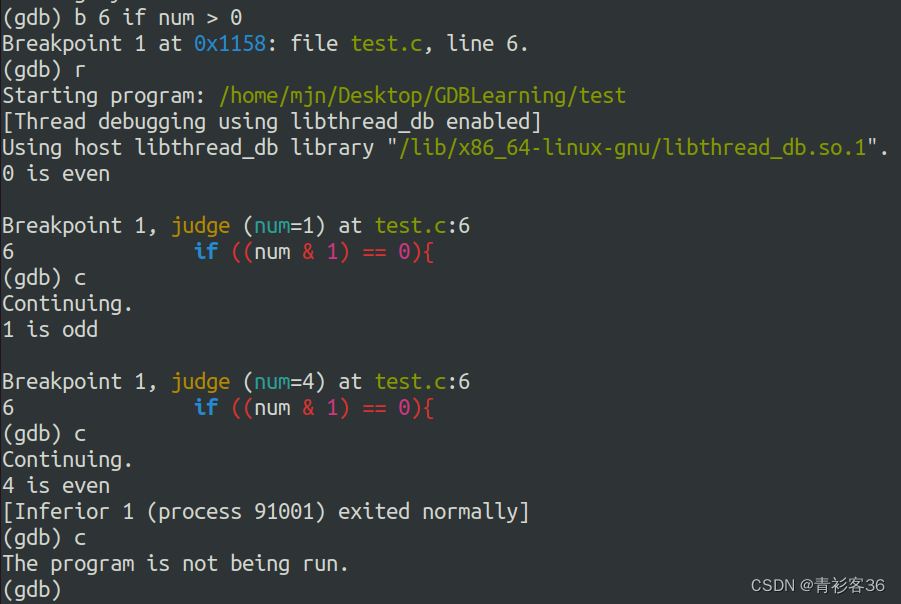
此时,只有当num>0时,程序才会在第6行断住。
3、查看断点信息
info breakpoints 或简写为 info b
可以使用info breakpoints查看断点的相关信息。包含都设置了哪些断点,断点被命中的次数等信息。示例如下:
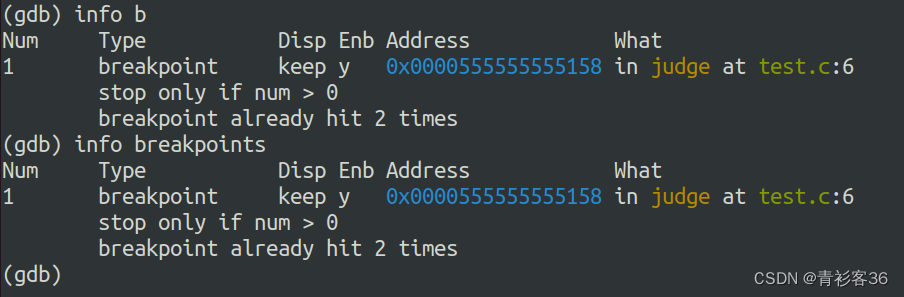
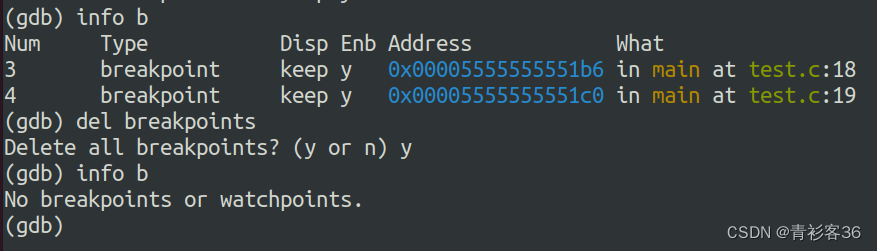
使用info breakpoints命令后,将会列出所有已设置的断点,每一个断点都有一个标号,用来代表这个断点。
4、删除断点
delete breakpoint 或简写为 del breakpoint
对于不再使用的断点我们可以将其删除。删除的命令格式为 delete breakpoint 断点编号。info breakpoint命令显示结果中的num列就是编号。删除断点的示例如下:
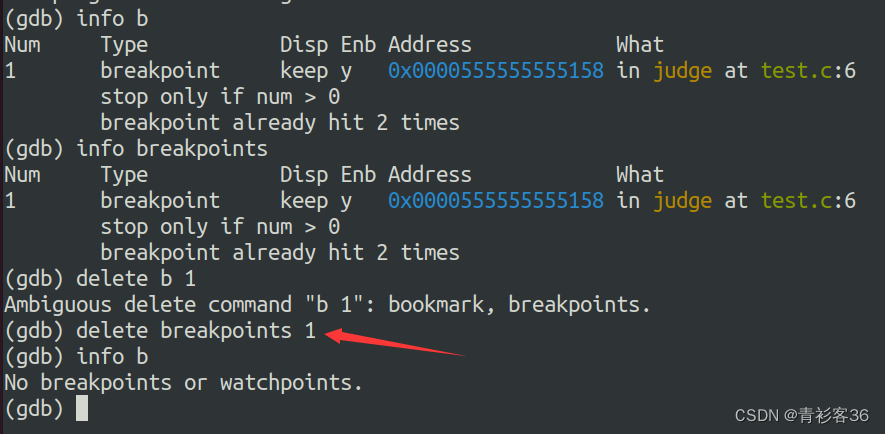
(看样子还不能简写为b,哈哈),再来看一种有多个断点的情况
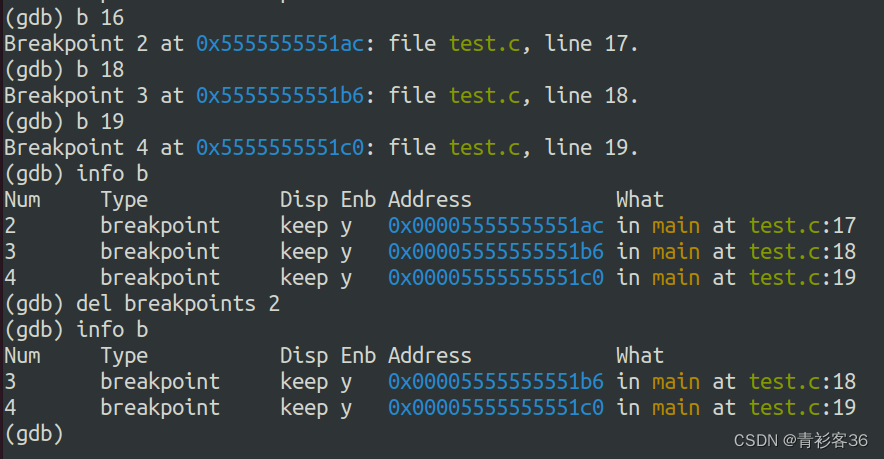
不指定断点编号的话,默认删除全部断点(会有confirm提示的,别担心hh~)
5、查看源码
断点设置完后,当程序运行到断点处就会暂停。暂停的时候,我们可以查看断点附近的代码。查看代码的子命令是list,缩写形式为l(L的小写字母)。
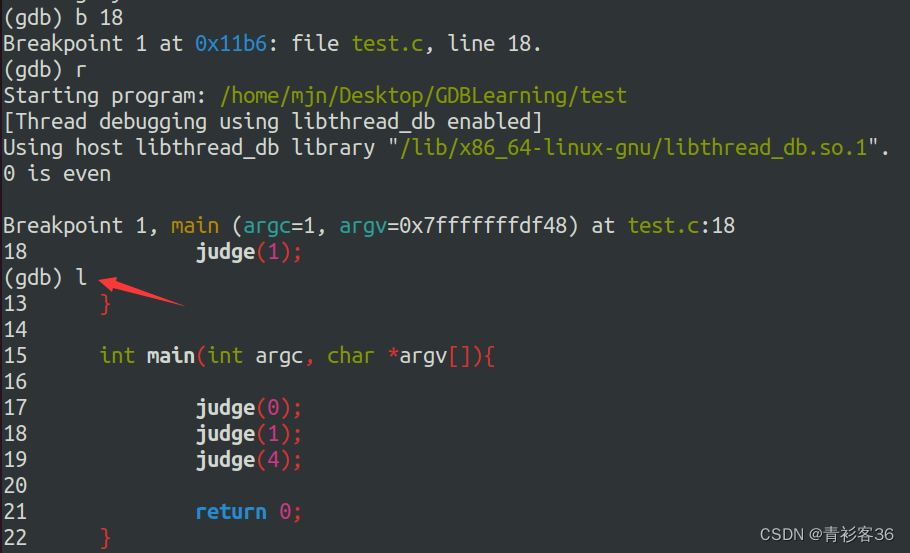
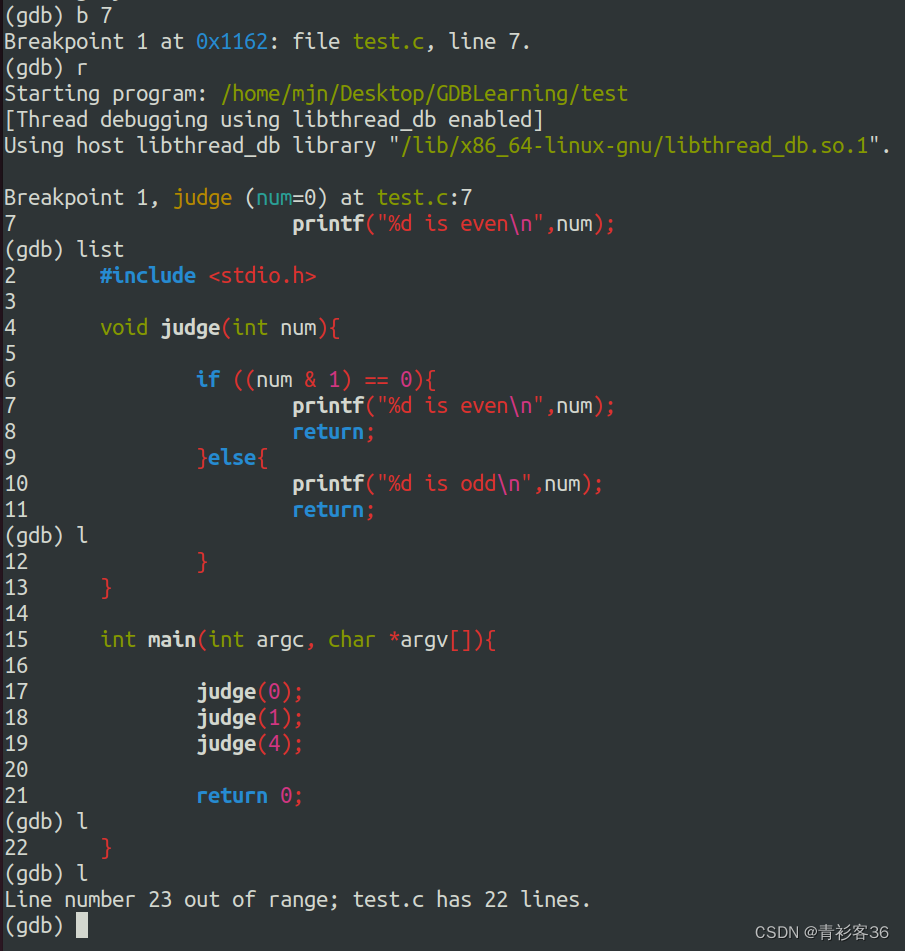
因为上面设置的断点是judge(1),所以list会展示出judge(1)附近的代码,再次执行list,会将后面的代码展示出来,直到代码全部展示完毕。ps:我数了一下,应该是每次展示附近的10行代码。
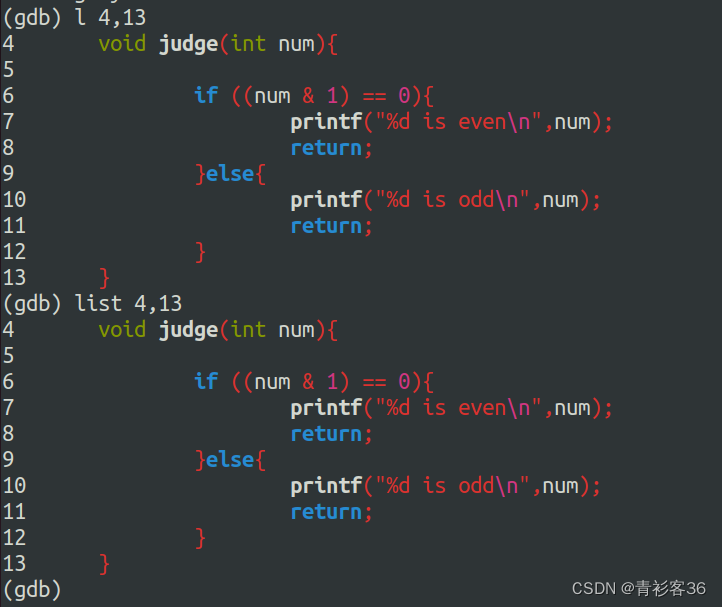
6、指定行号查看代码
list first,last 或简写为 l first,last # 小写的L
7、列出指定文件的源码
前面执行list命令时,默认列出test.c的源码,如果想要看指定文件的源码呢?可以使用下面的指令
list 文件名+行号/函数名
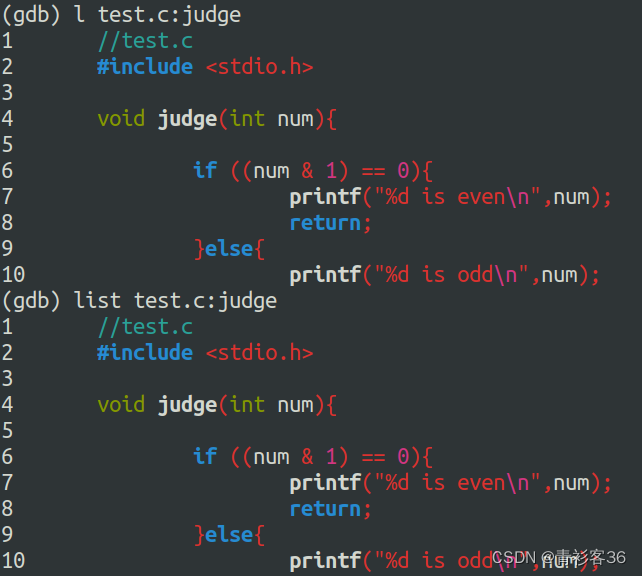
断点附近的代码了解之后,这时候就可以使用单步执行一条一条语句的去执行。可以随时查看执行后的结果。接下来你可能会想知道程序运行的一些情况,就需要查看变量的值。下面介绍单步调试与设置变量。
8、单步调试
单步执行有两个命令,分别是step和next。我们可能打了多处断点,或者断点打在循环内,这个时候,可以使用continue命令。这三个命令的区别在于:
1、next命令(可简写为n)用于在程序断住后,继续执行下一条语句。
2、step命令(可简写为s),它可以单步跟踪到函数内部。
3、continue命令(可简写为c)或者fg,它会继续执行程序,直到再次遇到断点处。
单步进入-step
step 一条语句一条语句的执行。它有一个别名s。它可以单步跟踪到函数内部。详细来讲,step 就是单步执行,遇到子函数就进入并且继续单步执行;在其他调试其中相当于step-into命令,作用是移动到下一个可执行的代码行。如果当前行是一个函数调用,则调试器进入函数并停止在函数体的第一行。step可以帮助初步揭开代码位置的谜团,例如:函数调用和函数本身可能在不同的文件中。
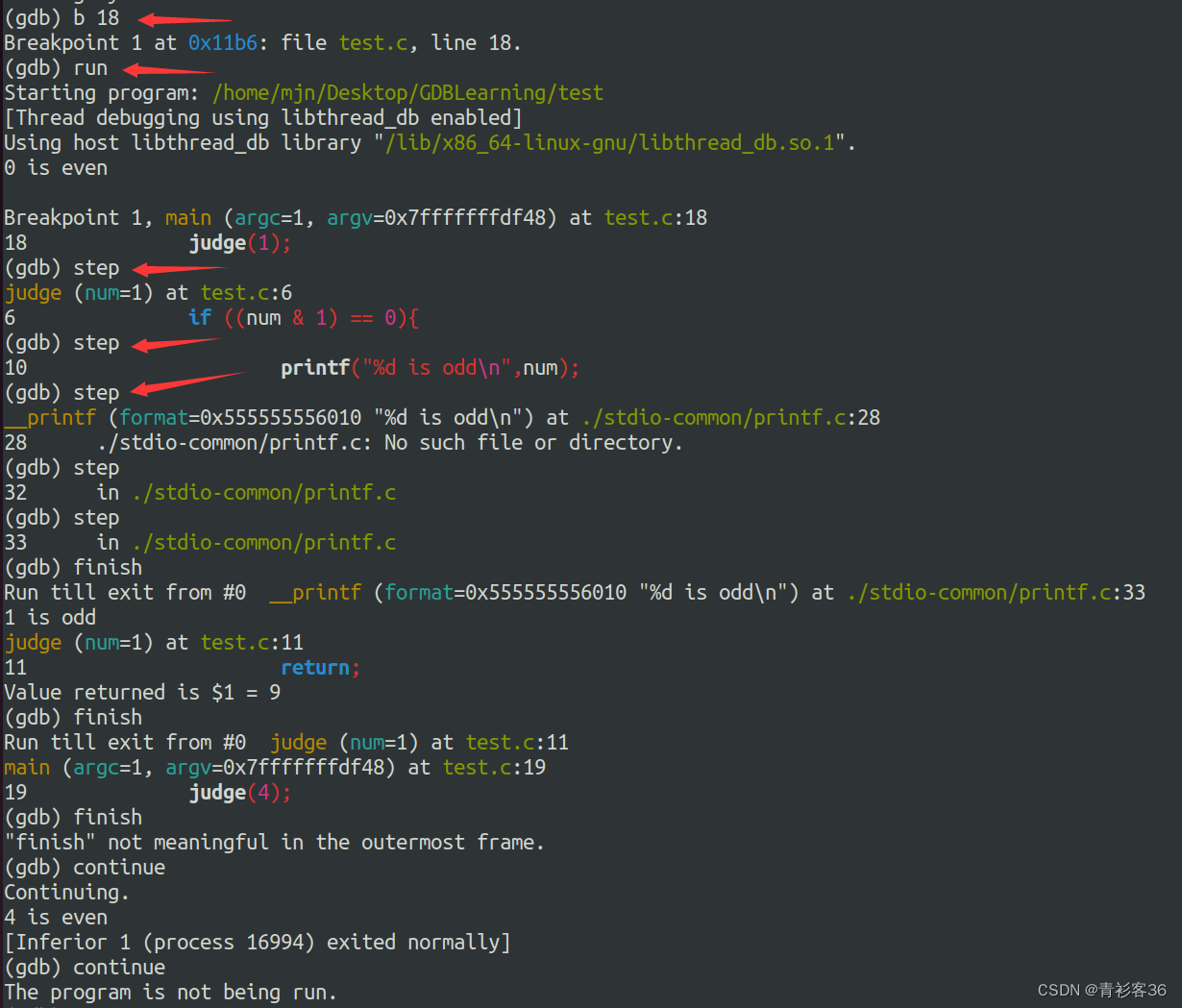
我在第18行打了断点,然后执行run命令,到18行断点处停下,然后用step命令进入judge函数内部,step 就是单步执行,遇到子函数就进入并且继续单步执行,比如在源程序第6行没有函数调用,只是一个if判断,所以执行step就会继续向下走,而如果该行有函数调用,比如printf,继续执行step就会深入到printf函数里面,如果我们想从printf库函数中跳出来,可以执行finish命令。
finish就是单步执行到子函数内时,用step out就可以执行完子函数余下部分,并返回到上一层函数。在其他调试器中相当于step-out,作用是在栈中前进到到下一层,并在调用函数的下一行停止。
单步执行-next
next命令(可简写为n)用于在程序断住后,继续执行下一条语句。详细来讲,next 是在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止,也就是把子函数整个作为一步。在其他调试器中相当于step-over,作用是在同一个调用栈层中移动到下一个可执行的代码行。调试器不会进入函数体。如果当前行是函数的最后一行,则,next将进入下一个栈层,并在调用函数的下一行停止。
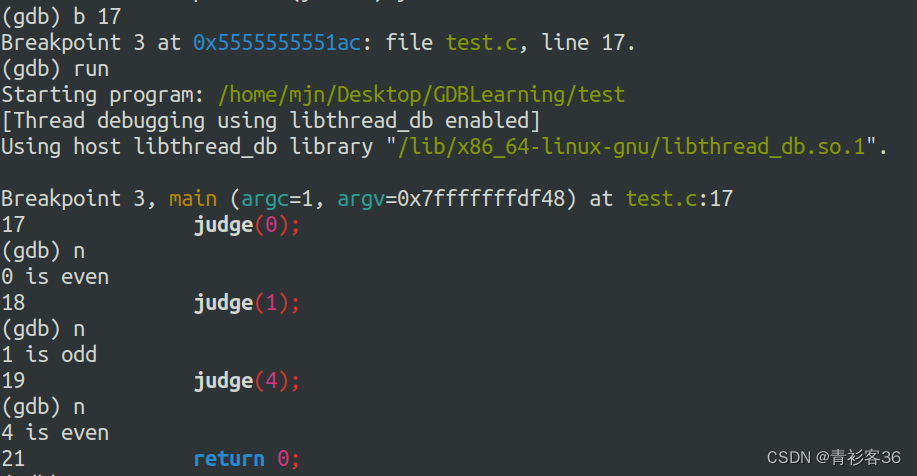
由上图我们可以看出,next指令不会进入judge函数内部,而是将子函数judge整个执行完再停止,也就是把子函数整个作为一步。
继续执行到下一个断点-continue
我们可能打了多处断点,或者断点打在循环内,若想跳过这个断点,甚至跳过多次断点继续执行该怎么做呢?可以使用continue命令。它的作用就是从暂停处继续执行。命令的简写形式为c。
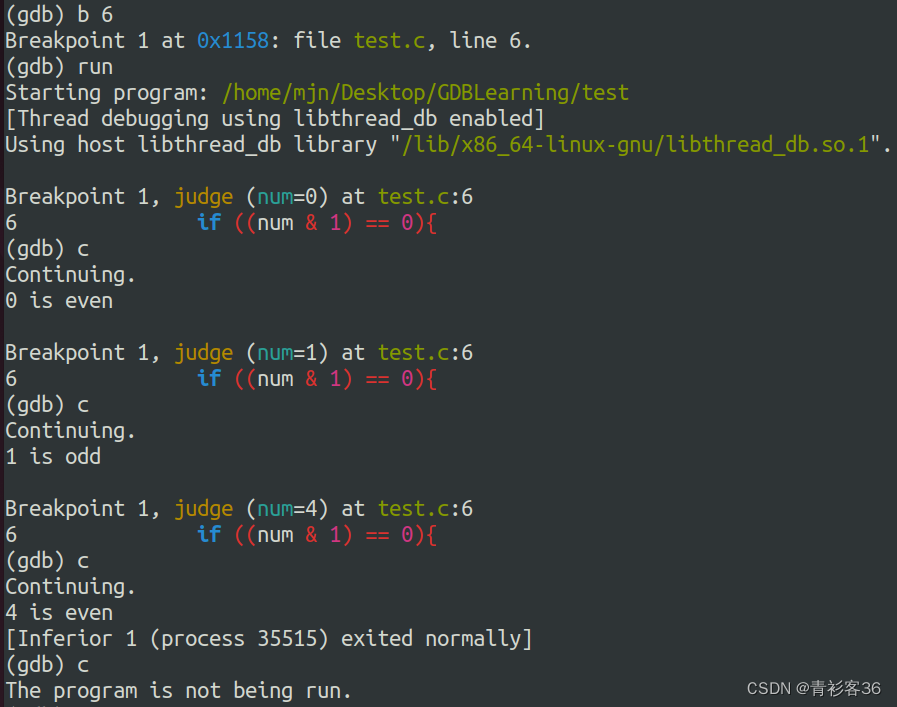
我把断点打在了子函数judge,函数体的开始位置,因为在主函数中要三次调用子函数judge,相当于打了三个断点,执行continue命令后,就会跳到下一处的断点位置。
跳过执行–skip
在下图可以看到,使用skip之后,将不会进入judge_sd函数。好处就是skip可以在step时跳过一些不想关注的函数或者某个文件。
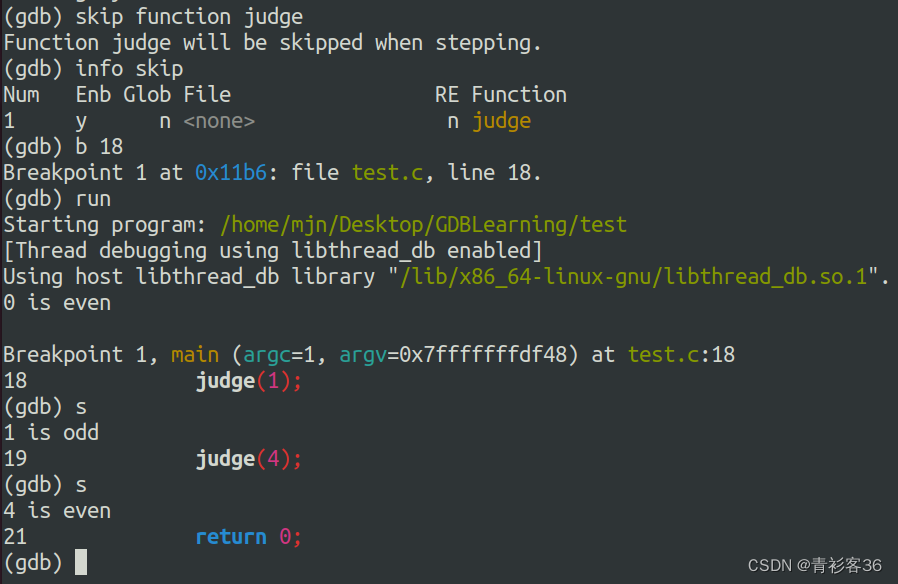
可以看到,再使用skip之后,使用step将不会进入judge函数。
- skip delete [num] 删除skip
- skip enable [num] 使能skip
- skip disable [num] 去使能skip
其中num是前面通过info skip看到的num值,上面可以带或不带该值,如果不带num,则针对所有skip,如果带上了,则只针对某一个skip。
为方便在终端查看下面讲述的内容,我们换一个源程序文件(如下所示)
#include<stdio.h>
#include<stdlib.h>int main( int argc , char *argv[] )
{int a = 1;int i = 0;int b[3] = {0,1,2};for(i = 0; i < 3;i++)b[i] = b[i] + 1;printf("%d\\n",a);int *p;p = b;printf("%d\\n",p[0]);return 0;
}编译产生可执行文件main:
gcc -g main.c -o main
9、查看变量
打印基本类型变量,数组
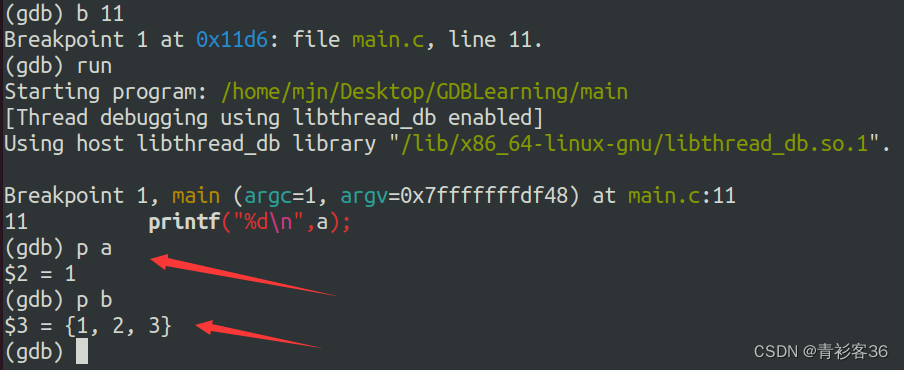
上面讲述了如何设置断点,查看断点附近的代码,并可以单步执行和继续执行。接下来可能会想知道程序运行的一些情况,如查看变量的值。此时我们可以使用print命令,以帮助我们进一步定位问题。
print [变量名] 或简写为 p [变量名]
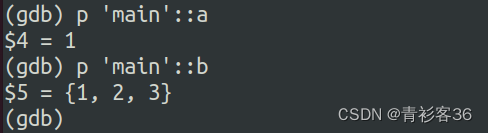
若多个函数或者多个文件有同一个变量名,这个时候可以在前面加上函数名或者文件名来区分:
打印指针指向内容
如果还是使用上面的方式打印指针指向的内容,那么打印出来的只是指针地址,例如:

而如果想要打印指针指向的内容,需要解引用:

从上面可以看到,仅仅使用*只能打印第一个值,如果要打印多个值,后面跟上@并加上要打印的长度。
另外值得一提的是,$可表示上一个变量,而假设此时有一个链表linkNode,它有next成员代表下一个节点,则可使用下面方式不断打印链表内容:
(gdb) p *linkNode
( 这里显示linkNode节点内容 )
(gdb) p *$.next
( 这里显示linkNode节点下一个节点的内容 )
10、按照特定格式打印变量
对于简单的数据,print默认的打印方式已经足够了,它会根据变量类型的格式打印出来,但是有时候这还不够,我们需要更多的格式控制。常见格式控制字符如下:
- x 按十六进制格式显示变量。
- d 按十进制格式显示变量。
- u 按十六进制格式显示无符号整型。
- o 按八进制格式显示变量。
- t 按二进制格式显示变量。
- a 按十六进制格式显示变量。
- c 按字符格式显示变量。
- f 按浮点数格式显示变量。
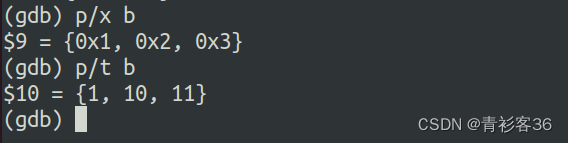
如果我们要查看b数组的十六进制和二进制格式打印,根据上面的规则得到:
查看内存内容
使用examine命令(简写为x)来查看内存地址中的值。x命令的语法如下:
x/[n][f][u] addr其中:
- n 表示要显示的内存单元数,默认值为1
- f 表示要打印的格式,前面已经提到了格式控制字符
- u 要打印的单元长度
- addr 内存地址
单元类型常见有如下:
- b 字节
- h 半字,即双字节
- w 字,即四字节
- g 八字节
我们通过一个实例来看,假如我们要把int变量a按照二进制方式打印,并且打印单位是一字节:

查看寄存器内容
info registers
以上是对GDB调试做了简单的实验总结,本实验涉及到GDB调试的常见用法,了解这些之后能够使用GDB定位大部分问题。但是GDB的使用远不止如此,当遇到更加复杂的情况时,可以再去学习更多相关操作。
本次实验的完成参考了许多其他博主的博客,笔者在此向各位致谢,感谢各位精彩的分享,让我受益匪浅。
参考链接:
GDB调试指南(入门,看这篇够了)_程序猿编码的博客-CSDN博客
GDB调试入门指南 - 知乎
【Linux】GDB调试教程(新手小白)_gdb p_爪可摘星辰的博客-CSDN博客
gdb中查看内存方法总结_gdb看的是物理内存还是虚拟内存_angus_monroe的博客-CSDN博客
https://www.cnblogs.com/J1ac/p/9113669.html