显存不够用?一种大模型加载时节约一半显存的方法

Loading huge PyTorch models with linear memory consumption
本文主要介绍了一种用于加载巨大模型权重时节约接近一半显存的方法
首先,创建一个模型:
import torch
from torch import nnclass BoringModel(nn.Sequential):def __init__(self):super().__init__()self.in_proj = nn.Linear(2, 10)self.stages = nn.Sequential(nn.Linear(10, 10),nn.Linear(10, 10))self.out_proj = nn.Linear(10, 2)上述创建,模型占用 1x 显存, x是指模型的大小
model = BoringModel()
# model is now in memory
有些时候我们把模型保存到本地硬盘中
torch.save(model.state_dict(), "./checkpoint.pt")
# our models is now stored on disk
之后需要用到之前保存的模型(两倍显存消耗)
# we need to redefine the model
model = BoringModel()# 1x memory used
state_dict = torch.load("./checkpoint.pt")# 2x memory used -> both model and state_dict are in memory!!!
model.load_state_dict(state_dict)
# 1x memory used
我们需要两倍的显存来加载我们之前存储过的权重
如果我们有一个巨大的模型,这是有问题的,因为我们需要两倍的空闲RAM。例如,假设我们有16GB的RAM,而我们的模型使用10GB。加载它需要20GB,我们需要改变我们的策略。
Recently, PyTorch introduced the meta device. When you put a tensor to the meta device, only its metadata (e.g. shape) are stored, and its values are tossed away. Thus, no space is used.
meta例子
x = torch.tensor([1])
x
tensor([1])
x.to(torch.device("meta"))
tensor(…, device=‘meta’, size=(1,), dtype=torch.int64)
因此,我们可以通过这种方法使用一倍的显存消耗来加载我们的模型
-
定义我们的模型
1x显存 -
实例化到meta设备上
1x显存 -
加载state_dict,
1x显存 -
replace all empty parameters of our model with the values inside the state_dict
1x显存
我们首先需要弄清楚如何将所有模型的参数替换为加载的“state_dict”中的原始参数
Let’s create the load_state_dict_with_low_memory function.
from typing import Dictdef load_state_dict_with_low_memory(model: nn.Module, state_dict: Dict[str, torch.Tensor]):# 通过把模型放到meta设备上来释放一半的显存model.to(torch.device("meta"))# 我们需要将state_dict中的每个键关联到一个子模块# we need to associate each key in state_dict to a submodule# 然后,迭代地使用' state_dict '中的值重新创建所有子模块的参数then, iteratively, re-creat all submodules' parameters with the values in `state_dict`pass
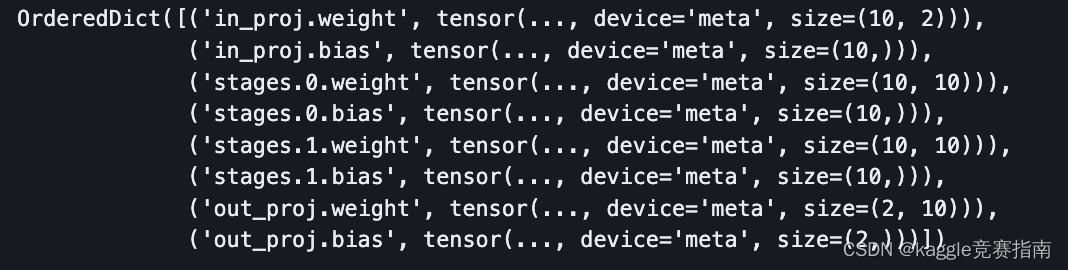
load_state_dict_with_low_memory(model, {})model.state_dict()
OrderedDict([('in_proj.weight', tensor(..., device='meta', size=(10, 2))),('in_proj.bias', tensor(..., device='meta', size=(10,))),('stages.0.weight', tensor(..., device='meta', size=(10, 10))),('stages.0.bias', tensor(..., device='meta', size=(10,))),('stages.1.weight', tensor(..., device='meta', size=(10, 10))),('stages.1.bias', tensor(..., device='meta', size=(10,))),('out_proj.weight', tensor(..., device='meta', size=(2, 10))),('out_proj.bias', tensor(..., device='meta', size=(2,)))])
模型现在是空的。
现在我们必须计算出来自state_dict的每个参数必须放入模型的哪个submodule of model中。一种方法是使用[key_in_state_dict] -> [submodule_in_module]创建一个字典。Now we have to figure out in which submodule of model each parameter from state_dict has to go. One way to do it is to create a dictionary with [key_in_state_dict] -> [submodule_in_module].
因此,我们知道我们必须将加载的state_dict中的值放在哪里。记住,一旦模型被放置在元设备中,它的所有权重都将被丢弃。
So we know where we have to place the values from the loaded state_dict. Remember, as soon as the model is placed inside the meta device, all its weights are tossed away.)
from typing import Dictdef get_keys_to_submodule(model: nn.Module) -> Dict[str, nn.Module]:keys_to_submodule = {}# iterate all submodulesfor submodule_name, submodule in model.named_modules():# iterate all paramters in each submobulefor param_name, param in submodule.named_parameters():# param_name is organized as <name>.<subname>.<subsubname> ...# the more we go deep in the model, the less "subname"s we havesplitted_param_name = param_name.split('.')# if we have only one subname, then it means that we reach a "leaf" submodule, # we cannot go inside it anymore. This is the actual parameteris_leaf_param = len(splitted_param_name) == 1if is_leaf_param:# we recreate the correct keykey = f"{submodule_name}.{param_name}"# we associate this key with this submodulekeys_to_submodule[key] = submodulereturn keys_to_submodule
get_keys_to_submodule(model)
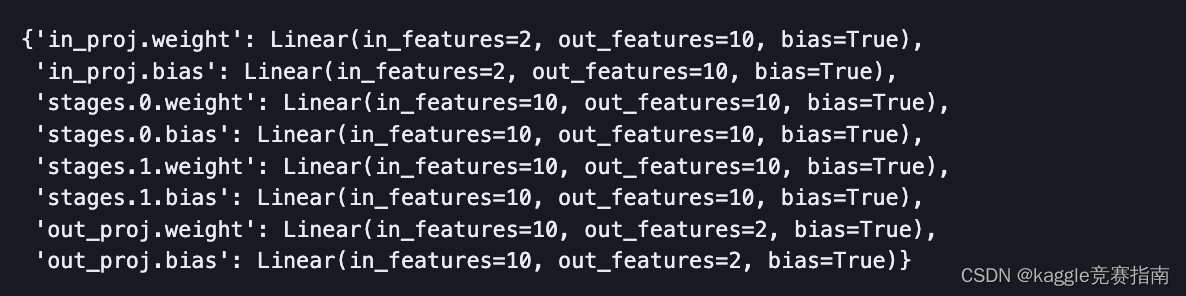
现在我们有办法知道哪个键对应’ model 的哪个submodule of model。让我们回到我们的load_state_dict_with_low_memory函数并使用来自state_dict的正确值将每个子模块的参数具体化
def load_state_dict_with_low_memory(model: nn.Module, state_dict: Dict[str, torch.Tensor]):# free up memory by placing the model in the `meta` devicemodel.to(torch.device("meta"))keys_to_submodule = get_keys_to_submodule(model)for key, submodule in keys_to_submodule.items():# get the valye from the state_dictval = state_dict[key]# we need to substitute the parameter inside submodule, # remember key is composed of <name>.<subname>.<subsubname># the actual submodule's parameter is stored inside the # last subname. If key is `in_proj.weight`, the correct field if `weight`param_name = key.split('.')[-1]param_dtype = getattr(submodule, param_name).dtypeval = val.to(param_dtype)# create a new parameternew_val = torch.nn.Parameter(val, requires_grad=False))setattr(submodule, param_name, new_val)model.state_dict()
load_state_dict_with_low_memory(model, torch.load("checkpoint.pt"))
model.state_dict()
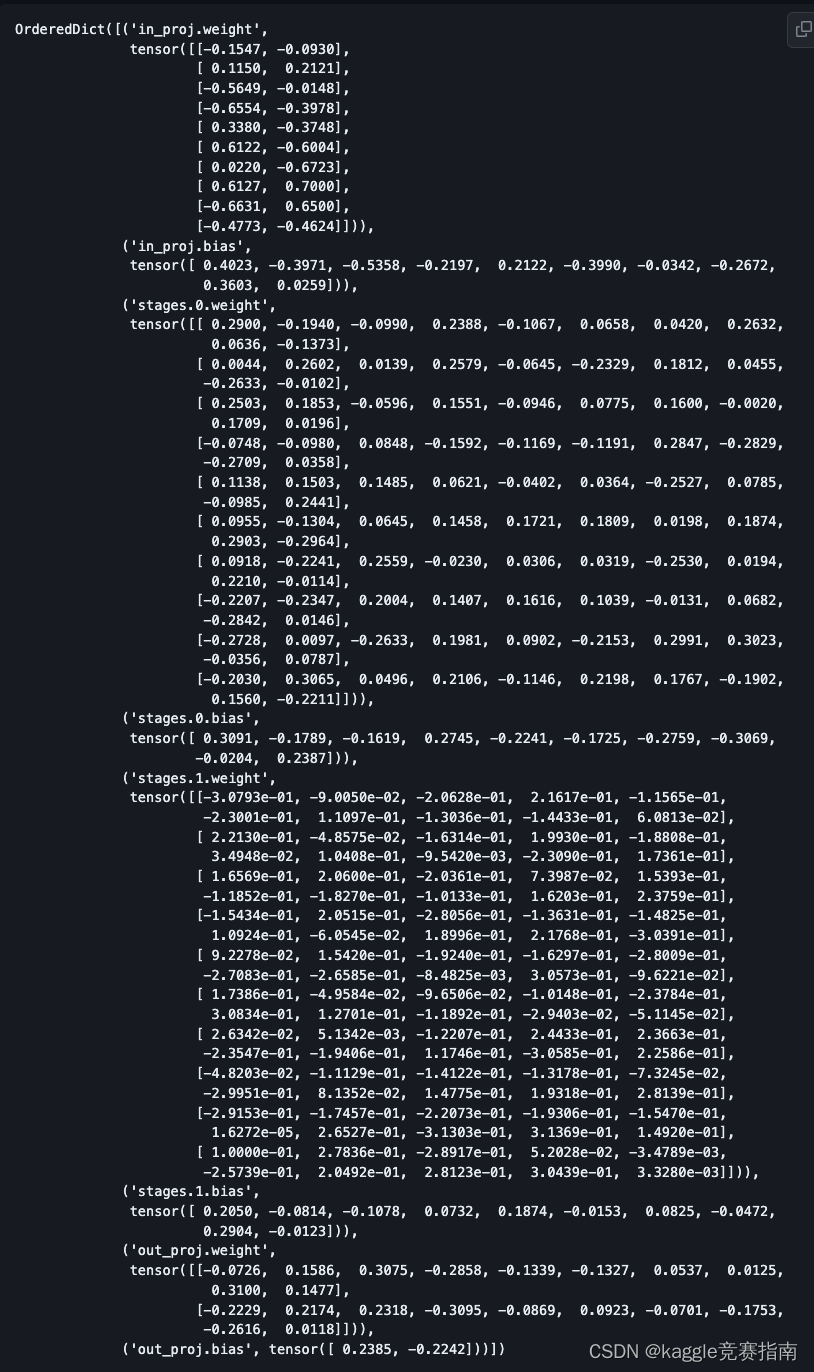
🎉 We have successfully loaded our checkpoint inside our model with linear memory consumption!