inplace-operation-error 【已解决】

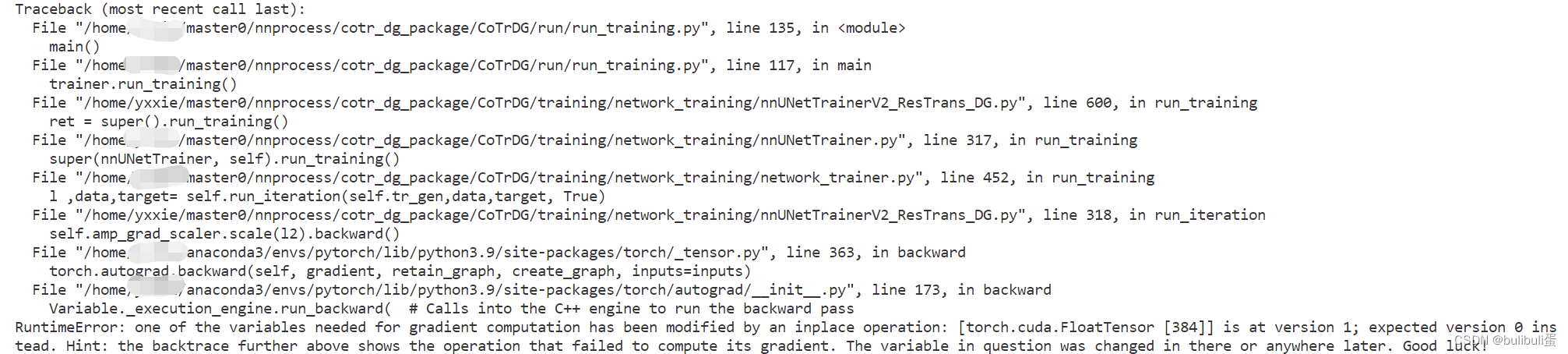
最近在搞CT医学图像分割模型的领域泛化优化,结果就出现了报错:
关于这个问题stackoverflow上有非常多的讨论,可以过去围观:
指路:中文版stackoverflow - 堆栈内存溢出 (stackoom.com)
Stack Overflow - Where Developers Learn, Share, & Build Careers
看了很多问题和我这个问题都不太一样。
one of the variables needed for gradient computation has been modified by an inplace operation 归根结底是梯度计算所需的变量之一已被就地操作修改,相信大家都已经尝试过用
with torch.autograd.set_detect_anomaly(True)来查看问题出错的地方,一般能够通过这个方法来找出错误的人,可以看看报错问题的附近能不能使用.clone()或者将+=和*=写完整,这些一般是修改模型时出问题可以考虑的。
但是我是做领域泛化优化的,只改进了训练方式,并没修改模型。在做优化前,我的模型可以正常运行,但是报错却指出我的normalization有问题,如下图所示:
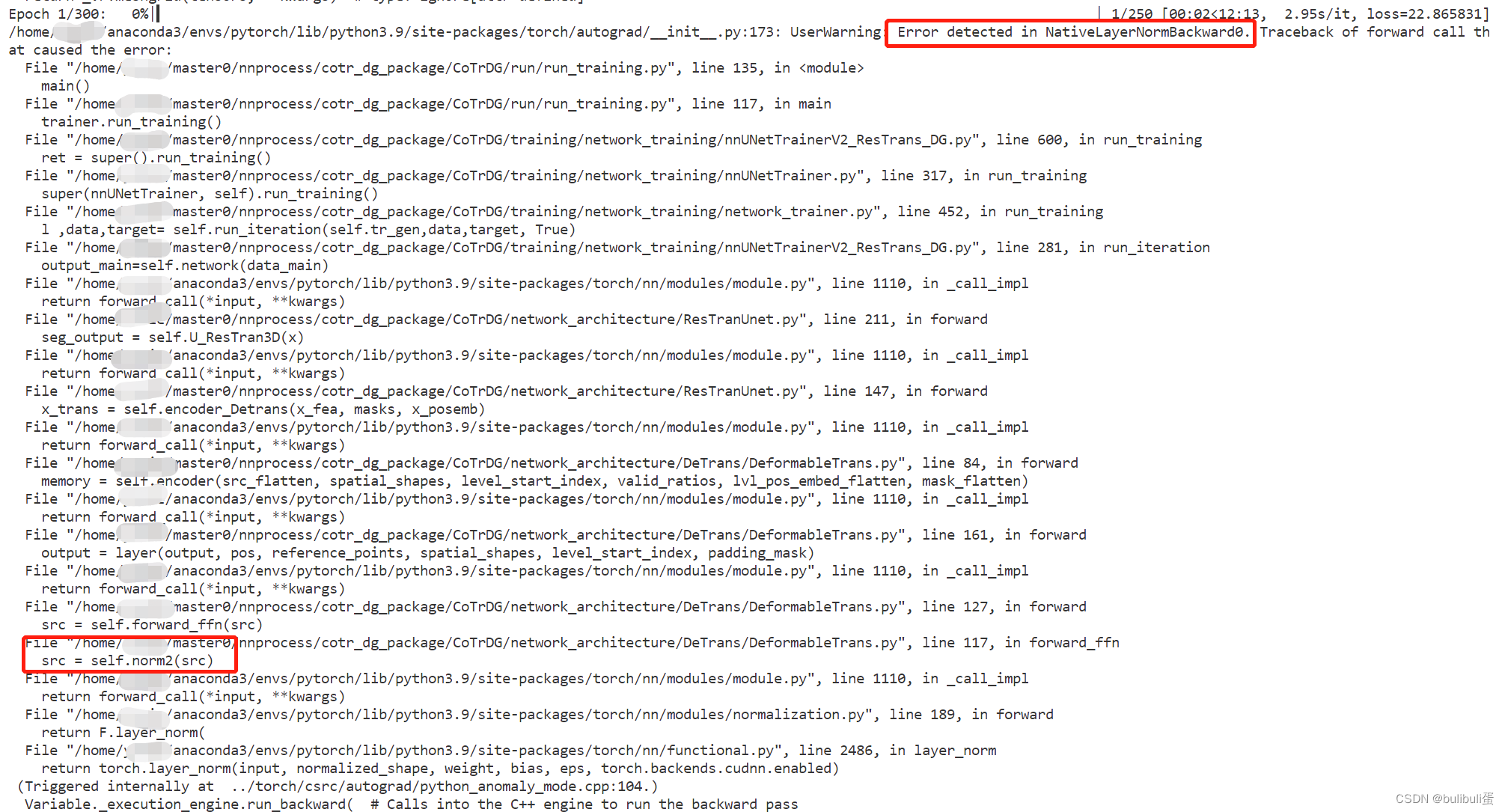
找一下附近的代码:
def forward_ffn(self, src):src2 = self.linear2(self.dropout2(self.activation(self.linear1(src))))src = src.clone() + self.dropout3(src2)src = self.norm2(src)return srcdef forward(self, src, pos, reference_points, spatial_shapes, level_start_index, padding_mask=None):# self attentionsrc2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask)src = src.clone() + self.dropout1(src2)src = self.norm1(src)# ffnsrc = self.forward_ffn(src)return src发现这边的代码写得没毛病啊,到底是哪里的问题呢?
后来仔细观察了一下改写后的训练代码
self.optimizer.zero_grad()self.meta_optimizer.zero_grad()if self.fp16:with torch.autograd.set_detect_anomaly(True):with autocast():output_meta=self.network(data_meta)output_main=self.network(data_main)## theta hat (meta-updata)l1=self.loss(output_meta,target_meta)Lmain=self.loss(output_main,target_main)del output_maindel output_meta# batch for meta updateif do_backprop:## 反向传播梯度self.amp_grad_scaler.scale(l1).backward()# unscale 梯度,可以不影响clip的thresholdself.amp_grad_scaler.unscale_(self.meta_optimizer)# 梯度裁剪,防止梯度爆炸torch.nn.utils.clip_grad_norm_(self.network.parameters(), 12)# 更新模型参数self.amp_grad_scaler.step(self.optimizer)self.amp_grad_scaler.update()self.meta_optimizer.zero_grad()with autocast():output_meta=self.network(data_meta)del data_metaoutput_main=self.network(data_main)del data_mainLadapt=self.loss(output_meta,target_meta)Lrecall=self.loss(output_main,target_main)del output_maindel output_metadel target_meta## theta hat (meta-updata)l2=self.meta_beta*Lrecall+self.meta_gama*Ladapt+Lmainif do_backprop:## 反向传播梯度self.amp_grad_scaler.scale(l2).backward()# unscale 梯度,可以不影响clip的thresholdself.amp_grad_scaler.unscale_(self.optimizer)# 梯度裁剪,防止梯度爆炸torch.nn.utils.clip_grad_norm_(self.network.parameters(), 12)# 更新模型参数self.amp_grad_scaler.step(self.meta_optimizer)self.amp_grad_scaler.update()文章经过四次前向传播,和两次反向传播,但是每次都是第二次反向传播出错,主要原因在于第二次反向传播用到的loss函数中,用到了第一次反向传播之前计算的一个Loss,因此,直接使用该loss就会出现inplace operation error,因此需要Detach一下将其复制过来,而不是在原来的地址上操作。
l2=self.meta_beta*Lrecall+self.meta_gama*Ladapt+Lmain.detach()
后面就没事了!