自己的完整c++ cuda包

pytorch关于c++的所有文档集合
Welcome to PyTorch Tutorials — PyTorch Tutorials 2.0.0+cu117 documentation
1.前置条件
使用编辑器clion,安装好cudatoolkit,cudnn,pytorch环境,编译工具gcc等等。
记得要设置好cudatoolkit的环境变量和动态链接库,这样到时候才能找到cudatoolkit和cudnn
安装教程可看
https://mp.csdn.net/mp_blog/creation/editor/new/129111146
注意我们如果要使用pytorch 的c语言版,是不需要安装额外的libpytorch的,因为pytorch下载的时候就自动整合了这些。
官方教程
CUDA projects | CLion Documentation
Installing C++ Distributions of PyTorch — PyTorch master documentation
2.通过clion创建cuda可执行项目
参照Installing C++ Distributions of PyTorch — PyTorch master documentation
这两个文件
![]()
以及 CMakeLists.txt我们是不需要的,我们使用setup.py代替 CMakeLists.txt
setup.py
参考官方文档
2. Writing the Setup Script — Python 3.6.15 documentation
以及pytorch的 setup.py教程,写的很详细
Custom C++ and CUDA Extensions — PyTorch Tutorials 2.0.0+cu117 documentation
文件项目结构
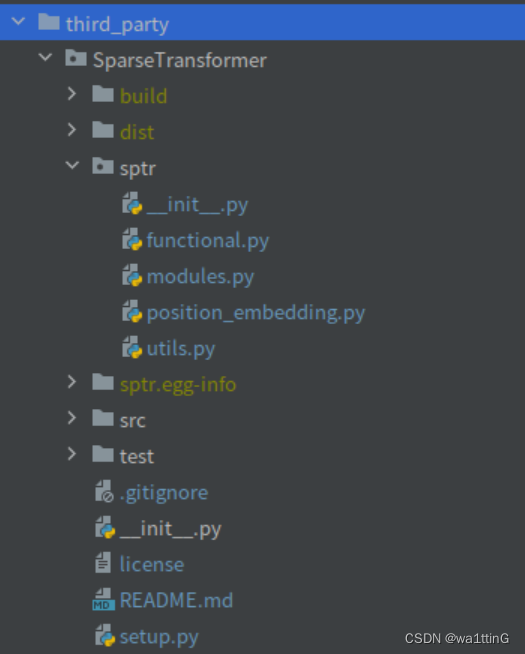
setup.py的安装代码模板
#python3 setup.py install
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
import os
from distutils.sysconfig import get_config_vars(opt,) = get_config_vars('OPT')
os.environ['OPT'] = " ".join(flag for flag in opt.split() if flag != '-Wstrict-prototypes'
)setup(name='sptr',ext_modules=[CUDAExtension('sptr_cuda', ['src/sptr/pointops_api.cpp','src/sptr/attention/attention_cuda.cpp','src/sptr/attention/attention_cuda_kernel.cu','src/sptr/precompute/precompute.cpp','src/sptr/precompute/precompute_cuda_kernel.cu','src/sptr/rpe/relative_pos_encoding_cuda.cpp','src/sptr/rpe/relative_pos_encoding_cuda_kernel.cu',],extra_compile_args={'cxx': ['-g'], 'nvcc': ['-O2', '-g', '-G']})],cmdclass={'build_ext': BuildExtension}
)
- setup的是一个包,要将什么包给安装上来,是我们要生成的动态链接库的名字
- name='sptr' 是包名,执行python3 setup.py install会安装一个叫sptr的包
- ext_modules表明我要输出的模块,模块才是真正能被python代码调用的,而不是包!,比如我写
- import sptr是找不到模块的,因为他根本就不是模块!,调用import sptr_cuda才会有效。
- CUDAExtension就是拓展模块,比如我有模块sptr_cuda,与他绑定的有哪些cpp文件我写过来,配合pointops_api.cpp(也就是第一行),可以将指定的cpp接口暴露给sptr_cuda模块,使得python代码可以调用。
- extra_compile_args 就是传给 gcc 的额外的编译参数,比方说你可以传一个 -std=c++11
这里c语言的编译器用的是cxx应该也就是gcc不知道为啥要叫做cxx,nvcc就是cu代码的编译器,它也可以编译c++语言。
'nvcc': ['-O2', '-g', '-G'] -O2参数含义O2该优化选项会牺牲部分编译速度,除了执行-O1所执行的所有优化之外,还会采用几乎所有的目标配置支持的优化算法,用以提高目标代码的运行速度。
-g,-G
NVCC, the NVIDIA CUDA compiler driver, provides a mechanism for generating the debugging information necessary for CUDA-GDB to work properly. The
-g -Goption pair must be passed to NVCC when an application is compiled for ease of debugging with CUDA-GDB; for example,也就是生成调试信息,只有nvcc 添加上这两个选项,后面才能链接生成可以被cuda-gdb调试的可执行文件

gcc -g只是编译器,在编译的时候,产生调试信息,通俗来讲是后面生成的可执行文件能够被gdb调试,如果不加-g的话 gdb是无法调试的。
GCC中-O1 -O2 -O3 优化的原理是什么? - 知乎
- cmdclass将BuildExtension类给传入了,
-
torch.utils.cpp_extension.BuildExtension(dist, kw )
简单来说就是提供参数的,我们直接写就好了
自定义
setuptools构建扩展。
setuptools.build_ext子类负责传递所需的最小编译器参数(例如-std=c++11)以及混合的C ++/CUDA编译(以及一般对CUDA文件的支持)。当使用
BuildExtension时,它将提供一个用于extra_compile_args(不是普通列表)的词典,通过语言(cxx或cuda)映射到参数列表提供给编译器。这样可以在混合编译期间为C ++和CUDA编译器提供不同的参数。
(opt,) = get_config_vars('OPT')
os.environ['OPT'] = " ".join(flag for flag in opt.split() if flag != '-Wstrict-prototypes'
) #设置环境变量opt
目的:创建环境变量opt,里面是执行setup.py传入的默认参数
Wstrict-prototypes:确定是否为未指定参数类型声明或定义的函数发出警告
原先的opt为字符串'-DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes'
结果os.environ['OPT'] 为 '-DNDEBUG -g -fwrapv -O3 -Wall',将-Wstrict-prototypes去除了,其他和get_config_vars('OPT')一样,就是不发出这一种警告了。
执行安装
python3 setup.py install
可以看到我们安装好的sptr在和其他包相同的位置

包是叫sptr-0.0.0-py3.7-linux-x86_64.egg的文件夹

打开后就可以看到我们导出的模块了,我们import导入的就是sptr_cuda.py,然后他又指向动态链接库sptr_cuda.cpython-37m-x86_64-linux-gnu.so,他是我们编译好的动态链接库(就是在运行时去动态的找头文件对应的实现的编译内容),pycache文件就是sptr_cuda.py的对应pyc文件。

EGG-INFO文件夹下存储了一些包的相关信息,其中比如source文件夹就记录了源代码的名称
README.md
setup.py
sptr.egg-info/PKG-INFO
sptr.egg-info/SOURCES.txt
sptr.egg-info/dependency_links.txt
sptr.egg-info/top_level.txt
src/sptr/pointops_api.cpp
src/sptr/attention/attention_cuda.cpp
src/sptr/attention/attention_cuda_kernel.cu
src/sptr/precompute/precompute.cpp
src/sptr/precompute/precompute_cuda_kernel.cu
src/sptr/rpe/relative_pos_encoding_cuda.cpp
src/sptr/rpe/relative_pos_encoding_cuda_kernel.cu
test/test_attention_op_step1.py
test/test_attention_op_step2.py
test/test_precompute_all.py
test/test_relative_pos_encoding_op_step1.py
test/test_relative_pos_encoding_op_step1_all.py
test/test_relative_pos_encoding_op_step2.py可以据此定位到项目的源代码的位置(可能之后的调试代码的定位也是基于这个原理)
头文件在include文件夹下,so文件在ld_library_path下,然后暴露接口(使用PYBIND11_MODULE),最终导出模块,此时python就可以调用模块的接口了,所以so文件也就是封装好的c语言函数或者类。python调用c++接口的步骤如下:python导入模块,这个模块在site-packages里被找到,比如叫sptr_cuda.py,sptr_cuda.py里代理了很多c++的函数,这些实现都在sptr_cuda.cpython-37m-x86_64-linux-gnu.so中,当python调用函数,就在这里进行寻找实现,so文件完成计算后返回给接口,python程序就得到返回值了。
pointops_api.cpp
可以将指定的cpp接口暴露给sptr_cuda模块,使得python代码可以调用。
pybind11 具体用法
参考
跟我一起学习pybind11 之一 - 腾讯云开发者社区-腾讯云
绑定简单函数
让我们以一个极度简单的函数来开始创建python绑定,函数完成两数相加并返回结果
int add(int i, int j)
{return i + j;
}为简单起见,我们将函数和绑定代码都放在example.cpp这个文件中
#include <pybind11/pybind11.h>
namespace py = pybind11;int add(int i, int j)
{return i + j;
}PYBIND11_MODULE(example, m)
{m.doc() = "pybind11 example plugin"; // 可选的模块说明m.def("add", &add, "A function which adds two numbers");
}PYBIND11_MODULE()宏函数将会创建一个函数,在由Python发起import语句时该函数将会被调用(也就是生成模块)。模块名字“example”,由宏的第一个参数指定(千万不能出现引号),比如下面代码就传入sptr。第二个参数"m",定义了一个py::module的变量,实际也就是我们调用的moudle,传入python的模块。
m.doc:定义该模块的模块文档
m.def:定义该模块的映射参数,函数py::module::def()生成绑定代码,将add()函数暴露给Python。
第一个参数"add",表示我以后要在python中通过 模块名.add来调用函数
第二个参数&add,是将函数add的地址值填过来了,确定绑定的函数。
第三个参数:是函数的说明文档
注意:仅仅只需要少量的代码就能完成C++到Python的绑定工作,所有关于函数参数、返回值的细节,将会被模板元编程自动推导出来!这种整体的方法和语法都借鉴了Boost.Python,但是其底层实现是完全不同的。(也就是光写好这个文件就能完成自动映射,其他的细节我们不用多管)
我们项目中的使用示例
#include <torch/serialize/tensor.h>
#include <torch/extension.h>#include "attention/attention_cuda_kernel.h"
#include "rpe/relative_pos_encoding_cuda_kernel.h"
#include "precompute/precompute_cuda_kernel.h"PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {m.def("attention_step1_forward_cuda", &attention_step1_forward_cuda, "attention_step1_forward_cuda");m.def("attention_step1_backward_cuda", &attention_step1_backward_cuda, "attention_step1_backward_cuda");m.def("attention_step2_forward_cuda", &attention_step2_forward_cuda, "attention_step2_forward_cuda");m.def("attention_step2_backward_cuda", &attention_step2_backward_cuda, "attention_step2_backward_cuda");m.def("precompute_all_cuda", &precompute_all_cuda, "precompute_all_cuda");m.def("dot_prod_with_idx_forward_cuda", &dot_prod_with_idx_forward_cuda, "dot_prod_with_idx_forward_cuda");m.def("dot_prod_with_idx_backward_cuda", &dot_prod_with_idx_backward_cuda, "dot_prod_with_idx_backward_cuda");m.def("attention_step2_with_rel_pos_value_forward_cuda", &attention_step2_with_rel_pos_value_forward_cuda, "attention_step2_with_rel_pos_value_forward_cuda");m.def("attention_step2_with_rel_pos_value_backward_cuda", &attention_step2_with_rel_pos_value_backward_cuda, "attention_step2_with_rel_pos_value_backward_cuda");m.def("dot_prod_with_idx_all_forward_cuda", &dot_prod_with_idx_all_forward_cuda, "dot_prod_with_idx_all_forward_cuda");
}
注意头文件 #include <torch/extension.h>很万能(下面有他的源码),他包含了all.h,python.h,可以将很多头文件给导入进来,当然也包括PYBIND11_MODULE这个函数。#include <torch/serialize/tensor.h>我觉得可以不写。
CMakeLists.txt(这个不用看,只使用setup.py编译,用这个不知道如何导出python模块)
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.10)
project(untitled LANGUAGES CUDA CXX)
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")add_executable(untitled main.cu test1.cu pointops_api.cpp)
set(CMAKE_CUDA_STANDARD 17)set_target_properties(untitled PROPERTIESCUDA_SEPARABLE_COMPILATION ON)include_directories(SYSTEM ${TORCH_INCLUDE_DIRS})
target_link_libraries(untitled CUDA "${TORCH_LIBRARIES}")find_package(PythonInterp REQUIRED)
添加python编译器,否则cmake配置libtorch会报错Failed to compute shorthash for libnvrtc.so
cmake_minimum_required(VERSION 3.10)
要求使用的最低cmake版本,cmake低于这个版本不能编译该项目,可以自己设定
project(untitled LANGUAGES CUDA CXX)
untitled 为项目名,LANGUAGES CUDA CXX这个非常重要,就是我们的代码里的cu代码,和cpp,cc等代码能被正常编译,也就是同时启用CUDA代码和cxx代码的编译,
如果不加上CXX,就会报错
cmake-build-debug Unknown extension ".cc" for file
因为比如cpp文件cuda的编译器nvcc是可以编译的,但.cc文件也就是c++的源代码文件他无法编译,此时需要启用c++编译,也就是加上CXX。
find_package(Torch REQUIRED)
找到pytorch的c++文件,将pytorch导入进来。
这里是会先找pytorch的config文件,叫做 TorchConfig.cmake或torch-config.cmake,这个是pytorch关于cmake的配置文件,比如包含了去哪找pytorch的头文件,以及动态库等等,否则编译时是找不到对应的头文件的。
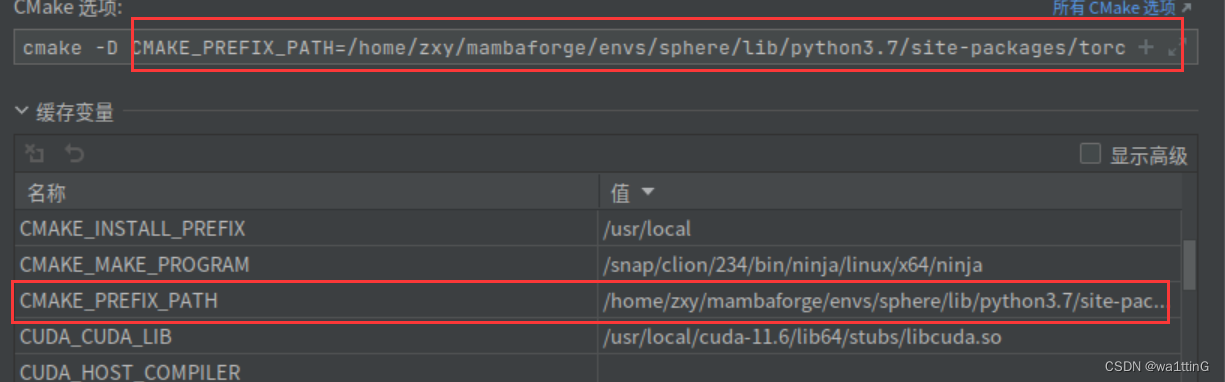
为了找到TorchConfig.cmake,我们需要设置一个缓存变量CMAKE_PREFIX_PATH,让他能够找到pytorch的TorchConfig.cmake的位置。
CMAKE_PREFIX_PATH=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmake该路径可以由torch.utils.cmake_prefix_path查询到
CMAKE_PREFIX_PATH作用:
用于FIND_XXX()搜索的路径,并添加适当的后缀。
指定一个将被FIND_XXX()命令使用的路径。它包含了 "基础 "目录,FIND_XXX()命令将适当的子目录附加到基础目录中。因此,FIND_PROGRAM()在路径中的每个目录中添加/bin,FIND_LIBRARY()在每个目录中添加/lib,FIND_PATH()和FIND_FILE()添加/include。默认情况下,它是空的,它的目的是由项目来设置。参见CMAKE_SYSTEM_PREFIX_PATH, CMAKE_INCLUDE_PATH, CMAKE_LIBRARY_PATH, CMAKE_PROGRAM_PATH。
FIND_PROGRAM中变为torch.utils.cmake_prefix_path/bin
FIND_PATH中变为torch.utils.cmake_prefix_path/include
找torch包变为torch.utils.cmake_prefix_path/torch 这个正是我们需要的,此时就能正确找到torch了
cmake最终写为如下,用于添加缓存变量
cmake -D CMAKE_PREFIX_PATH=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmake注意:如果下载了libpytorch(也就是单独的c++ pytorch库,不要将他的cmake文件夹导入进来,否则会报
Libtorch C++ build ‘Could NOT find Torch (missing: TORCH_LIBRARY)’
)
add_executable(untitled main.cu test1.cu pointops_api.cpp)
所有要进行编译的代码都在这声明。
include_directories(SYSTEM ${TORCH_INCLUDE_DIRS})
target_link_libraries(untitled CUDA "${TORCH_LIBRARIES}")
将pytorch头文件加入到头文件查找路径,将pytorch库文件添加到链接查找路径
cmake缓存变量
cmake缓存变量(Cache Variabl),相当于一个全局变量。在同一个CMake工程中任何地方都可以使用。
如何指定缓存变量?
- 法1 在调用cmake的时候加-D,后面的就是缓存变量
cmake -DCMAKE_PREFIX_PATH=/your/path
cmake -D CMAKE_PREFIX_PATH=/your/path这两种都可以
- 法2 在clion中修改,这两个位置是同步的,修改其中的一个框就行,其实和法1是同一种方式
- 法3 使用set 命令
set(<variable> <value>... CACHE <type> <docstring> [FORCE]) |
- variable:变量名称
- value:变量值列表
- CACHE:cache变量的标志
- type:变量类型,取决于变量的值。类型分为:BOOL、FILEPATH、PATH、STRING、INTERNAL
- docstring:必须是字符串,作为变量概要说明
- FORCE:强制选项,强制修改变量值
-
代码结构
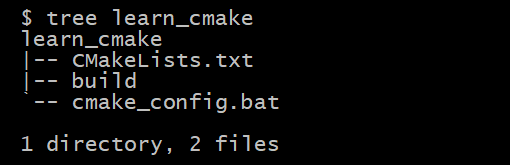
- learn_cmake:为根目录
- build:为CMake配置输出目录(在此例中即生成sln解决方案的地方)
- cmake_config.bat:执行CMake配置过程的脚本(双击直接运行)
- CMakeLists.txt:CMake脚本
-
示例代码(CMakeLists.txt文件内容)
cmake_minimum_required(VERSION 3.18)# 设置工程名称set(PROJECT_NAME KAIZEN)# 设置工程版本号set(PROJECT_VERSION "1.0.0.10" CACHE STRING "默认版本号")# 工程定义project(${PROJECT_NAME}LANGUAGES CXX CVERSION ${PROJECT_VERSION})# 打印开始日志message(STATUS "\\n# BEGIN_TEST_CACHE_VARIABLE") 定义缓存变量# 定义一个STRIING类型缓存变量(不加FORCE选项)set(MY_GLOBAL_VAR_STRING_NOFORCE "abcdef" CACHE STRING "定义一个STRING缓存变量")message("MY_GLOBAL_VAR_STRING_NOFORCE: ${MY_GLOBAL_VAR_STRING_NOFORCE}")# 定义一个STRIING类型缓存变量(加FORCE选项)set(MY_GLOBAL_VAR_STRING "abc" CACHE STRING "定义一个STRING缓存变量" FORCE)message("MY_GLOBAL_VAR_STRING: ${MY_GLOBAL_VAR_STRING}")- 法4 在CMakeCache.txt中进行修改,注意这种的优先级比较低,就是使用命令行定义的变量会覆盖CMakeCache.txt的同名变量,可以说是命令行定义会覆盖CMakeCache.txt的值,每次运行cmake,比如命令行传入了CMAKE_PREFIX_PATH为aaa,那么会先修改CMakeCache.txt的CMAKE_PREFIX_PATH为aaa,再读入CMakeCache.txt的总体缓存数据。覆盖说明我在CMakeCache.txt定义的值,如果在命令行定义过了比如aaa,无论再怎么在CMakeCache.txt里修改都没有用,修改成bbb,ccc,运行一次cmake直接被改写成aaa。
当 CMake 首次在一个空的构建树中运行时,它会创建一个 CMakeCache.txt文件并使用项目的可自定义设置填充它。此选项可用于指定优先于项目默认值的设置。可以根据需要为尽可能多的CACHE条目重复该选项。

CMakeCache.txt文件示例
//Path to a program.
CMAKE_OBJCOPY:FILEPATH=/usr/bin/objcopy//Path to a program.
CMAKE_OBJDUMP:FILEPATH=/usr/bin/objdump//No help, variable specified on the command line.
CMAKE_PREFIX_PATH:UNINITIALIZED=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmake//Value Computed by CMake
CMAKE_PROJECT_DESCRIPTION:STATIC=//Value Computed by CMake
CMAKE_PROJECT_HOMEPAGE_URL:STATIC=可以通过一下的形式查看变量,就写在txt文件中
message("================${CMAKE_CXX_FLAGS}===============")附录:头文件
all.h
#pragma once#if !defined(_MSC_VER) && __cplusplus < 201402L
#error C++14 or later compatible compiler is required to use PyTorch.
#endif#include <torch/cuda.h>
#include <torch/data.h>
#include <torch/enum.h>
#include <torch/fft.h>
#include <torch/jit.h>
#include <torch/linalg.h>
#include <torch/nn.h>
#include <torch/optim.h>
#include <torch/serialize.h>
#include <torch/types.h>
#include <torch/utils.h>
#include <torch/autograd.h>
#include <torch/version.h>extension.h,万能头文件,一个文件包含了所有要用的东西。
#pragma once// All pure C++ headers for the C++ frontend.
#include <torch/all.h>
// Python bindings for the C++ frontend (includes Python.h).
#include <torch/python.h>
python.h
#pragma once#include <torch/detail/static.h>
#include <torch/nn/module.h>
#include <torch/ordered_dict.h>
#include <torch/types.h>#include <torch/csrc/Device.h>
#include <torch/csrc/Dtype.h>
#include <torch/csrc/DynamicTypes.h>
#include <torch/csrc/python_headers.h>
#include <torch/csrc/utils/pybind.h>#include <iterator>
#include <string>
#include <unordered_map>
#include <utility>
#include <vector>namespace torch {
namespace python {
namespace detail {
inline Device py_object_to_device(py::object object) {PyObject* obj = object.ptr();if (THPDevice_Check(obj)) {return reinterpret_cast<THPDevice*>(obj)->device;}throw TypeError("Expected device");
}inline Dtype py_object_to_dtype(py::object object) {PyObject* obj = object.ptr();if (THPDtype_Check(obj)) {return reinterpret_cast<THPDtype*>(obj)->scalar_type;}throw TypeError("Expected dtype");
}template <typename ModuleType>
using PyModuleClass =py::class_<ModuleType, torch::nn::Module, std::shared_ptr<ModuleType>>;/// Dynamically creates a subclass of `torch.nn.cpp.ModuleWrapper` that is also
/// a subclass of `torch.nn.Module`, and passes it the user-provided C++ module
/// to which it delegates all calls.
template <typename ModuleType>
void bind_cpp_module_wrapper(py::module module,PyModuleClass<ModuleType> cpp_class,const char* name) {// Grab the `torch.nn.cpp.ModuleWrapper` class, which we'll subclass// with a dynamically created class below.py::object cpp_module =py::module::import("torch.nn.cpp").attr("ModuleWrapper");// Grab the `type` class which we'll use as a metaclass to create a new class// dynamically.py::object type_metaclass =py::reinterpret_borrow<py::object>((PyObject*)&PyType_Type);// The `ModuleWrapper` constructor copies all functions to its own `__dict__`// in its constructor, but we do need to give our dynamic class a constructor.// Inside, we construct an instance of the original C++ module we're binding// (the `torch::nn::Module` subclass), and then forward it to the// `ModuleWrapper` constructor.py::dict attributes;// `type()` always needs a `str`, but pybind11's `str()` method always creates// a `unicode` object.py::object name_str = py::str(name);// Dynamically create the subclass of `ModuleWrapper`, which is a subclass of// `torch.nn.Module`, and will delegate all calls to the C++ module we're// binding.py::object wrapper_class =type_metaclass(name_str, py::make_tuple(cpp_module), attributes);// The constructor of the dynamic class calls `ModuleWrapper.__init__()`,// which replaces its methods with those of the C++ module.wrapper_class.attr("__init__") = py::cpp_function([cpp_module, cpp_class](py::object self, py::args args, py::kwargs kwargs) {cpp_module.attr("__init__")(self, cpp_class(*args, kwargs));},py::is_method(wrapper_class));// Calling `my_module.my_class` now means that `my_class` is a subclass of// `ModuleWrapper`, and whose methods call into the C++ module we're binding.module.attr(name) = wrapper_class;
}
} // namespace detail/// Adds method bindings for a pybind11 `class_` that binds an `nn::Module`
/// subclass.
///
/// Say you have a pybind11 class object created with `py::class_<Net>(m,
/// "Net")`. This function will add all the necessary `.def()` calls to bind the
/// `nn::Module` base class' methods, such as `train()`, `eval()` etc. into
/// Python.
///
/// Users should prefer to use `bind_module` if possible.
template <typename ModuleType, typename... Extra>
py::class_<ModuleType, Extra...> add_module_bindings(py::class_<ModuleType, Extra...> module) {// clang-format offreturn module.def("train",[](ModuleType& module, bool mode) { module.train(mode); },py::arg("mode") = true).def("eval", [](ModuleType& module) { module.eval(); }).def("clone", [](ModuleType& module) { return module.clone(); }).def_property_readonly("training", [](ModuleType& module) { return module.is_training(); }).def("zero_grad", [](ModuleType& module) { module.zero_grad(); }).def_property_readonly( "_parameters", [](ModuleType& module) {return module.named_parameters(/*recurse=*/false);}).def("parameters", [](ModuleType& module, bool recurse) {return module.parameters(recurse);},py::arg("recurse") = true).def("named_parameters", [](ModuleType& module, bool recurse) {return module.named_parameters(recurse);},py::arg("recurse") = true).def_property_readonly("_buffers", [](ModuleType& module) {return module.named_buffers(/*recurse=*/false);}).def("buffers", [](ModuleType& module, bool recurse) {return module.buffers(recurse); },py::arg("recurse") = true).def("named_buffers", [](ModuleType& module, bool recurse) {return module.named_buffers(recurse);},py::arg("recurse") = true).def_property_readonly("_modules", [](ModuleType& module) { return module.named_children(); }).def("modules", [](ModuleType& module) { return module.modules(); }).def("named_modules",[](ModuleType& module, py::object /* unused */, std::string prefix) {return module.named_modules(std::move(prefix));},py::arg("memo") = py::none(),py::arg("prefix") = std::string()).def("children", [](ModuleType& module) { return module.children(); }).def("named_children",[](ModuleType& module) { return module.named_children(); }).def("to", [](ModuleType& module, py::object object, bool non_blocking) {if (THPDevice_Check(object.ptr())) {module.to(reinterpret_cast<THPDevice*>(object.ptr())->device,non_blocking);} else {module.to(detail::py_object_to_dtype(object), non_blocking);}},py::arg("dtype_or_device"),py::arg("non_blocking") = false).def("to",[](ModuleType& module,py::object device,py::object dtype,bool non_blocking) {if (device.is_none()) {module.to(detail::py_object_to_dtype(dtype), non_blocking);} else if (dtype.is_none()) {module.to(detail::py_object_to_device(device), non_blocking);} else {module.to(detail::py_object_to_device(device),detail::py_object_to_dtype(dtype),non_blocking);}},py::arg("device"),py::arg("dtype"),py::arg("non_blocking") = false).def("cuda", [](ModuleType& module) { module.to(kCUDA); }).def("cpu", [](ModuleType& module) { module.to(kCPU); }).def("float", [](ModuleType& module) { module.to(kFloat32); }).def("double", [](ModuleType& module) { module.to(kFloat64); }).def("half", [](ModuleType& module) { module.to(kFloat16); }).def("__str__", [](ModuleType& module) { return module.name(); }).def("__repr__", [](ModuleType& module) { return module.name(); });// clang-format on
}/// Creates a pybind11 class object for an `nn::Module` subclass type and adds
/// default bindings.
///
/// After adding the default bindings, the class object is returned, such that
/// you can add more bindings.
///
/// Example usage:
/// \\rst
/// .. code-block:: cpp
///
/// struct Net : torch::nn::Module {
/// Net(int in, int out) { }
/// torch::Tensor forward(torch::Tensor x) { return x; }
/// };
///
/// PYBIND11_MODULE(my_module, m) {
/// torch::python::bind_module<Net>(m, "Net")
/// .def(py::init<int, int>())
/// .def("forward", &Net::forward);
/// }
/// \\endrst
template <typename ModuleType, bool force_enable = false>
torch::disable_if_t<torch::detail::has_forward<ModuleType>::value && !force_enable,detail::PyModuleClass<ModuleType>>
bind_module(py::module module, const char* name) {py::module cpp = module.def_submodule("cpp");auto cpp_class =add_module_bindings(detail::PyModuleClass<ModuleType>(cpp, name));detail::bind_cpp_module_wrapper(module, cpp_class, name);return cpp_class;
}/// Creates a pybind11 class object for an `nn::Module` subclass type and adds
/// default bindings.
///
/// After adding the default bindings, the class object is returned, such that
/// you can add more bindings.
///
/// If the class has a `forward()` method, it is automatically exposed as
/// `forward()` and `__call__` in Python.
///
/// Example usage:
/// \\rst
/// .. code-block:: cpp
///
/// struct Net : torch::nn::Module {
/// Net(int in, int out) { }
/// torch::Tensor forward(torch::Tensor x) { return x; }
/// };
///
/// PYBIND11_MODULE(my_module, m) {
/// torch::python::bind_module<Net>(m, "Net")
/// .def(py::init<int, int>())
/// .def("forward", &Net::forward);
/// }
/// \\endrst
template <typename ModuleType,typename =torch::enable_if_t<torch::detail::has_forward<ModuleType>::value>>
detail::PyModuleClass<ModuleType> bind_module(py::module module,const char* name) {return bind_module<ModuleType, /*force_enable=*/true>(module, name).def("forward", &ModuleType::forward).def("__call__", &ModuleType::forward);
}
} // namespace python
} // namespace torch