激活函数(Activation Function)

目录
1 激活函数的概念和作用
1.1 激活函数的概念
1.2 激活函数的作用
1.3 通俗地理解一下激活函数(图文结合)
1.3.1 无激活函数的神经网络
1.3.2 带激活函数的神经网络
2 神经网络梯度消失与梯度爆炸
2.1 简介梯度消失与梯度爆炸
2.2 梯度不稳定问题
2.3 产生梯度消失的根本原因
2.4 产生梯度爆炸的根本原因
2.5 当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生
2.6 如何解决梯度消失和梯度爆炸
3 激活函数的比较
1 激活函数的概念和作用
1.1 激活函数的概念
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。

在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式。
首先我们来了解一下人工神经元的工作原理,大致如下:
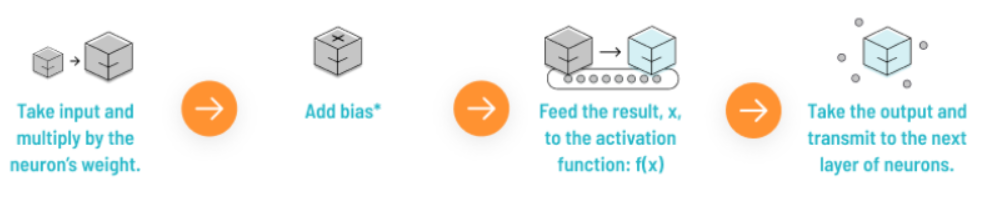 上述过程的数学可视化过程如下图所示:
上述过程的数学可视化过程如下图所示:
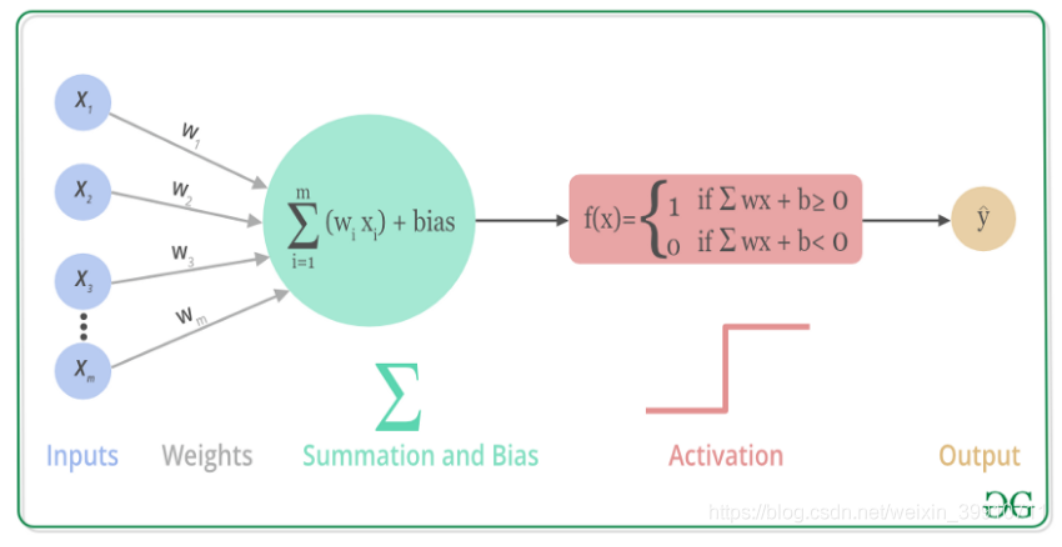
1.2 激活函数的作用
关于神经网络中的激活函数的作用,通常都是这样解释:不使用激活函数的话,神经网络的每层都只是做线性变换,多层输入叠加后也还是线性变换。因为线性模型的表达能力通常不够,所以这时候就体现了激活函数的作用了,激活函数可以引入非线性因素。疑问就来了,激活函数是如何引入非线性因素呢?
1.3 通俗地理解一下激活函数(图文结合)
为了解释激活函数如何引入非线性因素,接下来让我们以神经网络分割平面空间作为例子。
1.3.1 无激活函数的神经网络
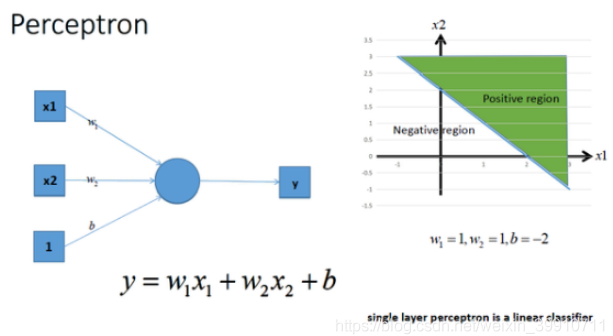
神经网络最简单的结构就是单输出的单层感知机,单层感知机只有输入层和输出层,分别代表了神经感受器和神经中枢。下图是一个只有两个输入单元和一个输出单元的简单单层感知机。图中x1,x2代表神经网络的输入神经元受到的刺激,w1,w2代表输入神经元和输出神经元间链接的紧密程度,b代表输出神经元的兴奋阈值,y为输出神经元的输出。我们使用该单层感知机划出一条线将平面分隔开,如图所示:
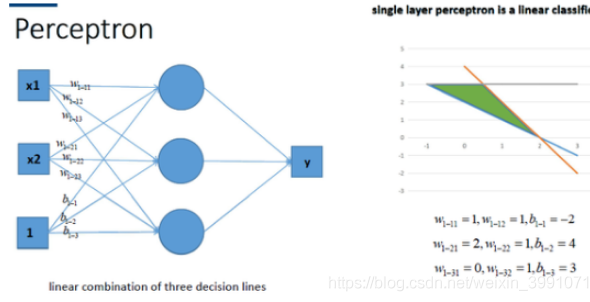
同理,我们也可以将多个感知机(注意,不是多层感知机)进行组合获得更强的平面分类能力,如图所示:
再看一看包含一个隐层的多层感知机的情况,如图所示:
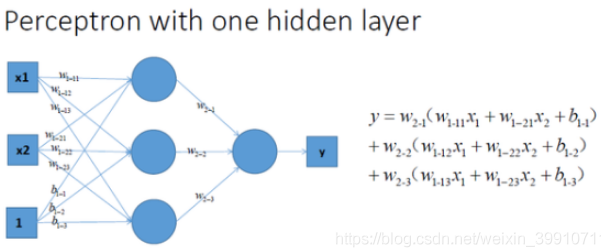
通过对比可以发现,上面三种没有激励函数的神经网络的输出都是线性方程,其都是在用复杂的线性组合来试图逼近曲线。
1.3.2 带激活函数的神经网络
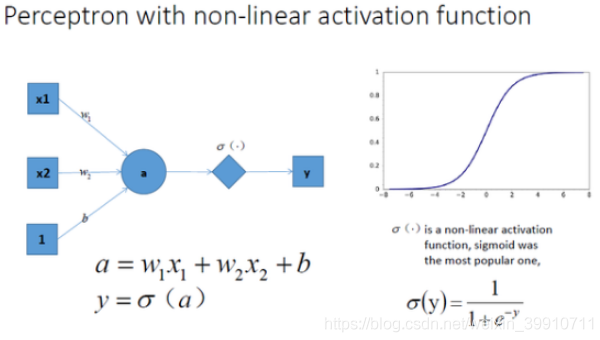
让我们在神经网络每一层神经元做完线性变换以后,加上一个非线性激活函数对线性变换的结果进行转换,结果显而易见,输出立马变成一个不折不扣的非线性函数了。
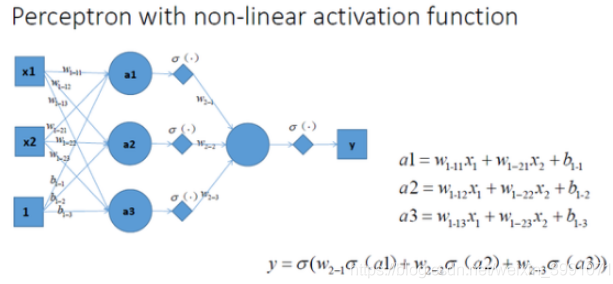
拓展到多层神经网络的情况,和刚刚一样的结构,加非线性激活函数之后,输出就变成了一个复杂的非线性函数了,如图所示:
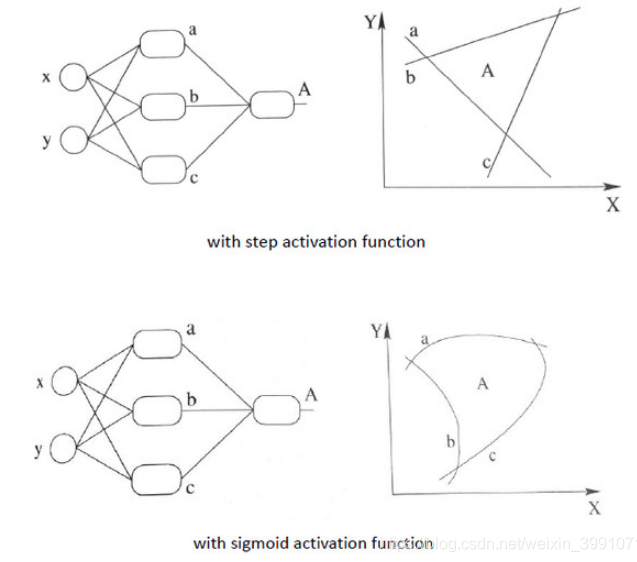
总结:加入非线性激活函数后,神经网络就有可能学习到平滑的曲线来分割平面,而不是用复杂的线性组合逼近平滑曲线来分割平面,使神经网络的表示能力更强了,能够更好的拟合目标函数。这就是为什么我们要有非线性的激活函数的原因。。如下图所示说明加入非线性激活函数后的差异,上图为用线性组合逼近平滑曲线来分割平面,下图为平滑的曲线来分割平面:
2 神经网络梯度消失与梯度爆炸
2.1 简介梯度消失与梯度爆炸
层数较多的神经网络模型在训练的时候会出现梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
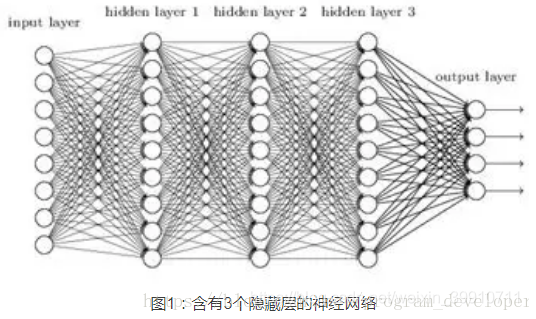
例如,对于下图所示的含有三个隐藏层的神经网络:
→梯度消失问题发生时,靠近输出层的hidden layer3的权值更新相对正常,但是靠近输入层的hidden layer1的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,仍接近于初始化的权值。这就导致hidden layer1相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。
→梯度爆炸的情况是:当初始的权值过大,靠近输入层的hidden layer1的权值变化比靠近输出层的hidden layer3的权值变化更快,就会引起梯度爆炸的问题。
2.2 梯度不稳定问题
在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
梯度不稳定的原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
2.3 产生梯度消失的根本原因
我们以图2的反向传播为例,假设每一层只有一个神经元且对于每一层都可以用公式1表示,其中为sigmoid函数,C表示的是代价函数,前一层的输出和后一层的输入关系如公式1所示。我们可以推导出公式2。

而sigmoid函数的导数如下图右图所示。
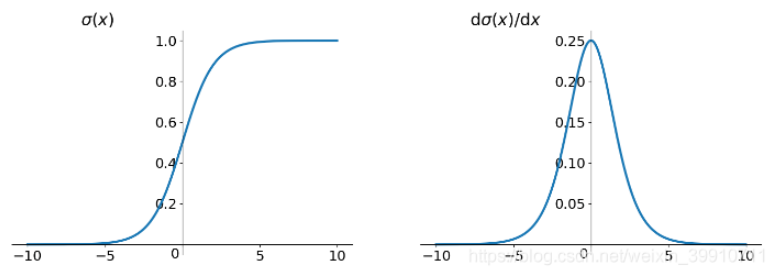
可见, 的最大值为1/4,而我们一般会使用标准方法来初始化网络权重,即使用一个均值为0标准差为1的高斯分布。因此,初始化的网络权值通常都小于1,从而有
。对于2式的链式求导,层数越多,求导结果越小,最终导致梯度消失的情况出现。
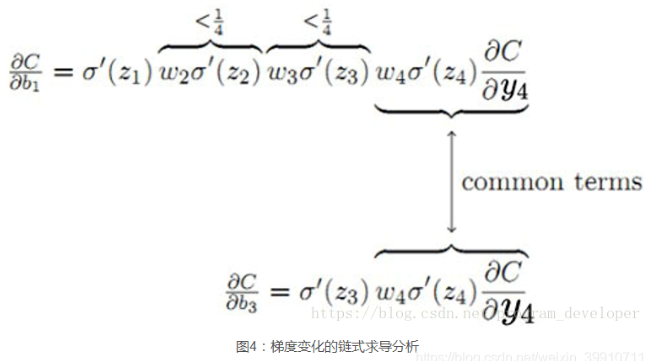
对于上图,和
有共同的求导项。可以看出,前面的网络层比后面的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。
2.4 产生梯度爆炸的根本原因
当,也就是W比较大的情况。则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。
2.5 当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生
结论:梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生。
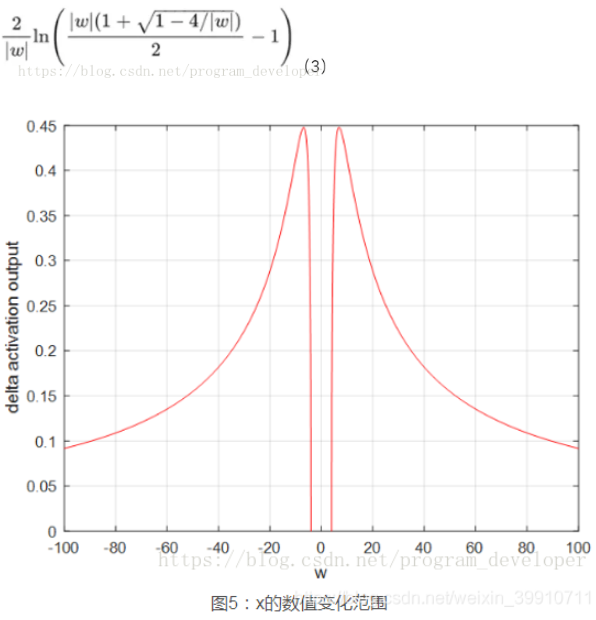
量化分析梯度爆炸时x的取值范围:因导数最大为0.25,故 > 4,才可能出现
;按照
可计算出x的数值变化范围很窄,仅在公式3范围内,才会出现梯度爆炸。画图如5所示,可见x的数值变化范围很小;最大数值范围也仅仅0.45,当
= 6.9时出现。因此仅仅在此很窄的范围内会出现梯度爆炸的问题。
2.6 如何解决梯度消失和梯度爆炸
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑以下三种方案解决:
1、用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmod函数。
2、用Batch Normalization。
3、LSTM的结构设计也可以改善RNN中的梯度消失问题。
3 激活函数的比较
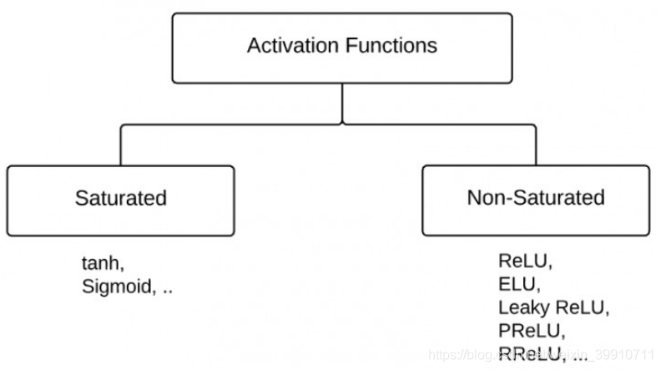

反之,不满足以上条件的函数则称为非饱和激活函数。
sigmoid和tanh是“饱和激活函数”,而ReLU及其变体则是“非饱和激活函数”。使用“非饱和激活函数”的优势在于两点:(1)“非饱和激活函数”能解决所谓的“梯度消失”问题。(2)它能加快收敛速度。
→Sigmoid函数将一个实值输入压缩至[0,1]的范围---------σ(x) = 1 / (1 + exp(−x))
→tanh函数将一个实值输入压缩至 [-1, 1]的范围---------tanh(x) = 2σ(2x) − 1
由于使用sigmoid激活函数会造成神经网络的梯度消失和梯度爆炸的问题,所以许多人提出了一些改进的激活函数,如:tanh、ReLU、LeakyReLU、PReLU、RReLU、ELU、Maxout。
本文参考:https://blog.csdn.net/weixin_39910711/article/details/114849349?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-114849349.nonecase&spm=1018.2226.3001.4187