【微服务 | 学成在线】项目易错重难点分析(内容管理模块篇)

文章目录
项目的模块架构理解
在我们做项目之前首先要对项目的模块结构有一个基本的了解,放一张我做的结构图:
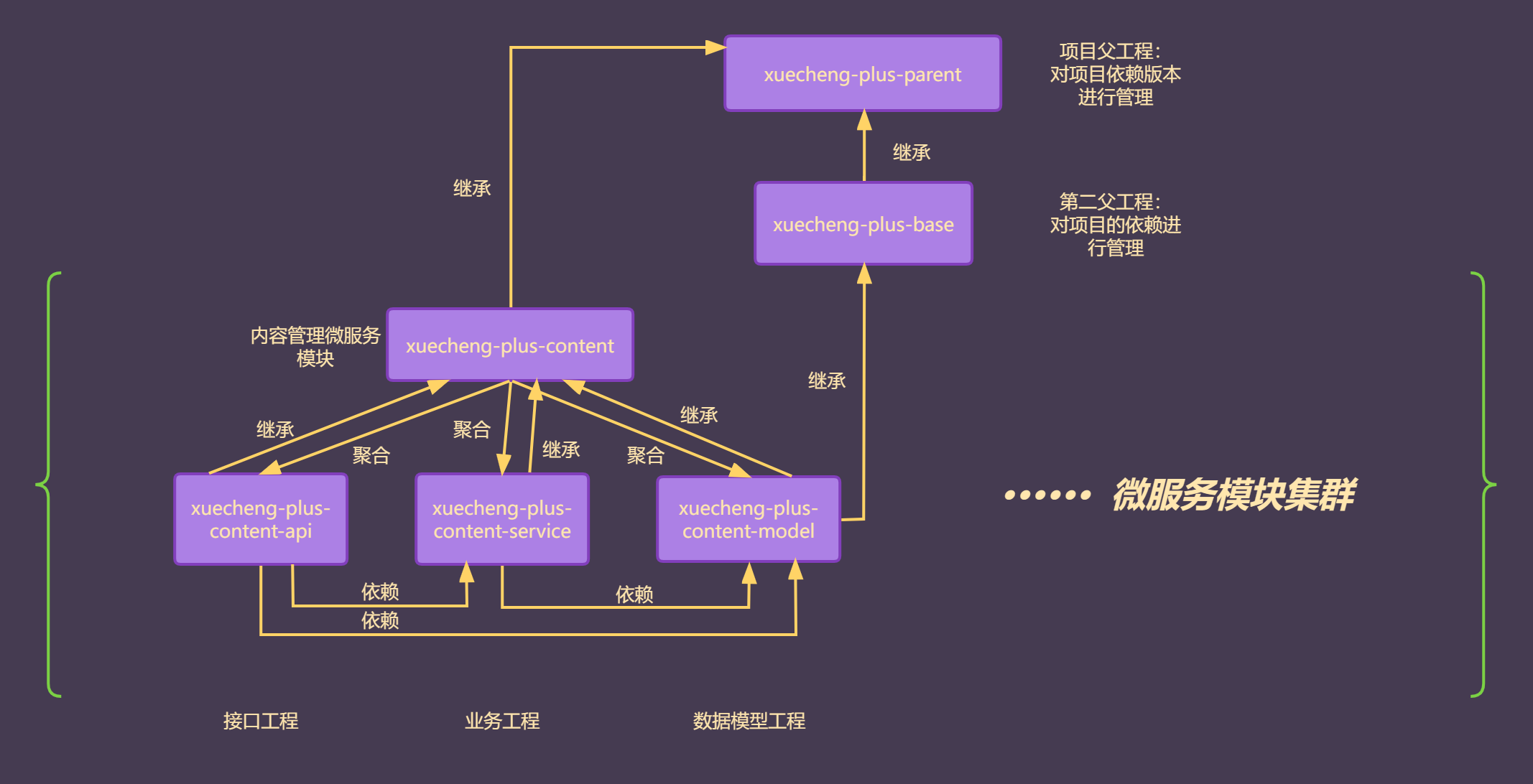
注意点:
- 我们将
依赖版本管理和依赖管理分为两个工程,而不是放在一个工程中,这样的话可以子模块可以选择性的继承,而不会太重- parent工程:对整个项目的依赖包版本进行管理
- base工程:提供基础类库、工具类库等(继承parent工程,从而也纳入版本管理)
- content工程是一个聚合工程,不需要依赖,所以我们让它继承于parent工程拿到依赖版本即可
- 在content微服务工程中,我们可以发现api工程和service工程都依赖于model工程,那么我们就不需要让api、service、model工程都去继承base工程,而是让model工程去继承base工程即可实现同样的效果。
- 有人可能会问:通过model工程,service和api工程都继承了base工程间接继承了parent工程,为什么还要再去分别继承content工程?
- 这说明对项目结构还不是非常的清楚。parent工程是对
整个项目的依赖版本进行管理,base工程中只是管理了基础依赖、工具依赖。而api、service、model工程中他们除了使用base中管理的基础依赖之外,肯定还有自己独有的依赖,这些独有的依赖如果想要纳入项目的依赖版本管理,只能是通过继承content,从而间接的继承parent工程。
- 这说明对项目结构还不是非常的清楚。parent工程是对
模型类的作用
我们得项目中会涉及到以下几种模型类:
- DTO数据传输对象:用于接口层向业务层之间传输数据
- PO持久化对象:用于业务层与持久层之间传输数据
- VO:前端与接口层之间传输数据
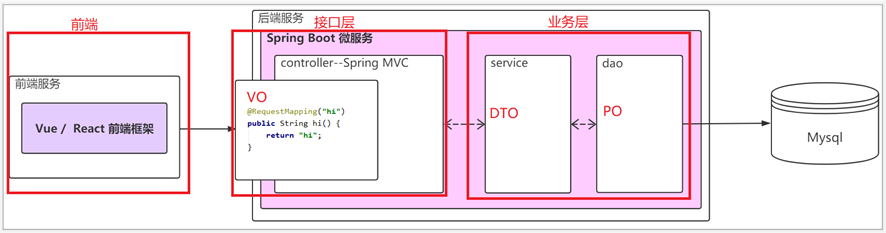
当前端有多个平台且接口存在差异时就需要设置VO对象用于前端和接口层传输数据。
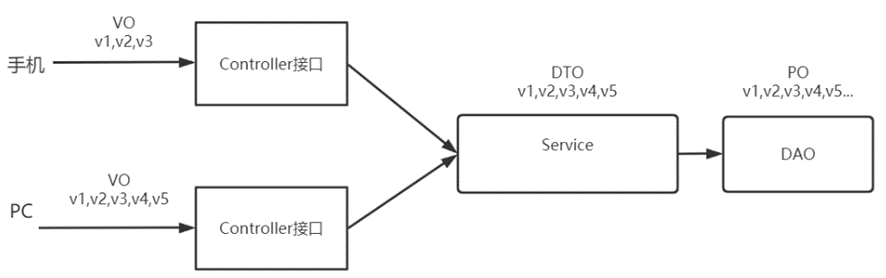
比如:课程列表查询接口,根据需求用户在手机端也要查询课程信息,此时课程查询接口是否需要编写手机端和PC端两个接口呢?如果用户要求通过手机和PC的查询条件或查询结果不一样,此时就需要定义两个Controller课程查询接口,每个接口定义VO对象与前端传输数据。
- 手机查询:根据课程状态查询,查询结果只有课程名称和课程状态。
- PC查询:可以根据课程名称、课程状态、课程审核状态等条件查询,查询结果也比手机查询结果内容多。
此时,Service业务层尽量提供一个业务接口,即使两个前端接口需要的数据不一样,Service可以提供一个最全查询结果,由Controller进行数据整合。
如下图:
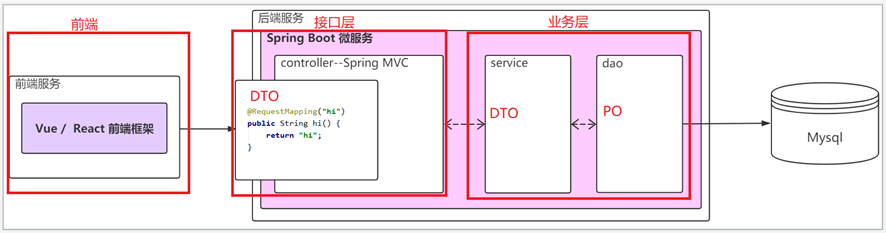
如果前端的接口没有多样性且比较固定,此时可以取消VO,只用DTO即可。
如下图:
生成接口文档
在前后端分离开发中通常由后端程序员设计接口,完成后需要编写接口文档,最后将文档交给前端工程师,前端工程师参考文档进行开发。
可以通过一些工具快速生成接口文档 ,本项目通过Swagger生成接口在线文档 。
什么是Swagger?
- OpenAPI规范(OpenAPI Specification 简称OAS)是Linux基金会的一个项目,试图通过定义一种用来描述API格式或API定义的语言,来规范RESTful服务开发过程,目前版本是V3.0,并且已经发布并开源在github上。(https://github.com/OAI/OpenAPI-Specification)
- Swagger是全球最大的OpenAPI规范(OAS)API开发工具框架,Swagger是一个在线接口文档的生成工具,前后端开发人员依据接口文档进行开发。 (https://swagger.io/)
- Spring Boot 可以集成Swagger,Swaager根据Controller类中的注解生成接口文档 ,只要添加Swagger的依赖和配置信息即可使用它。
-
在API工程添加swagger-spring-boot-starter依赖
<!-- Spring Boot 集成 swagger --><dependency><groupId>com.spring4all</groupId><artifactId>swagger-spring-boot-starter</artifactId></dependency> -
在 bootstrap.yml中配置swagger的扫描包路径及其它信息,base-package为扫描的包路径,扫描Controller类。
swagger:title: "学成在线内容管理系统"description: "内容系统管理系统对课程相关信息进行管理"base-package: com.xuecheng.contentenabled: trueversion: 1.0.0 -
在启动类中添加@EnableSwagger2Doc注解再次启动服务,工程启动起来,访问
http://localhost:63040/content/swagger-ui.html查看接口信息
下图为swagger接口文档的界面:
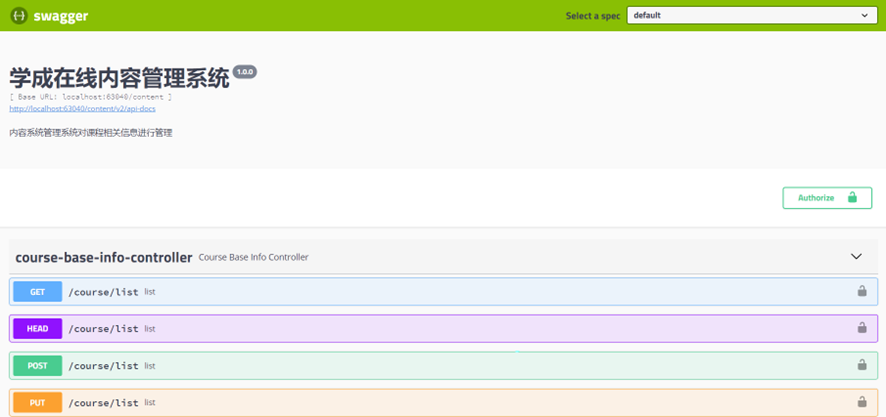
这个文档存在两个问题:
- 接口名称显示course-base-info-controller名称不直观
- 课程查询是post方式只显示post /course/list即可。
下边进行修改,添加一些接口说明的注解,并且将RequestMapping改为PostMapping,如下:
@Api(value = "课程信息编辑接口",tags = "课程信息编辑接口")
@RestController
public class CourseBaseInfoController {@ApiOperation("课程查询接口")@PostMapping("/course/list")public PageResult<CourseBase> list(PageParams pageParams, @RequestBody(required=false) QueryCourseParamsDto queryCourseParams){//....}}再次启动服务,工程启动起来,访问http://localhost:63040/content/swagger-ui.html查看接口信息:

接口文档中会有关于接口参数的说明,在模型类上也可以添加注解对模型类中的属性进行说明,方便对接口文档的阅读。
比如:下边标红的属性名称,可以通过swaager注解标注一个中文名称,方便阅读接口文档
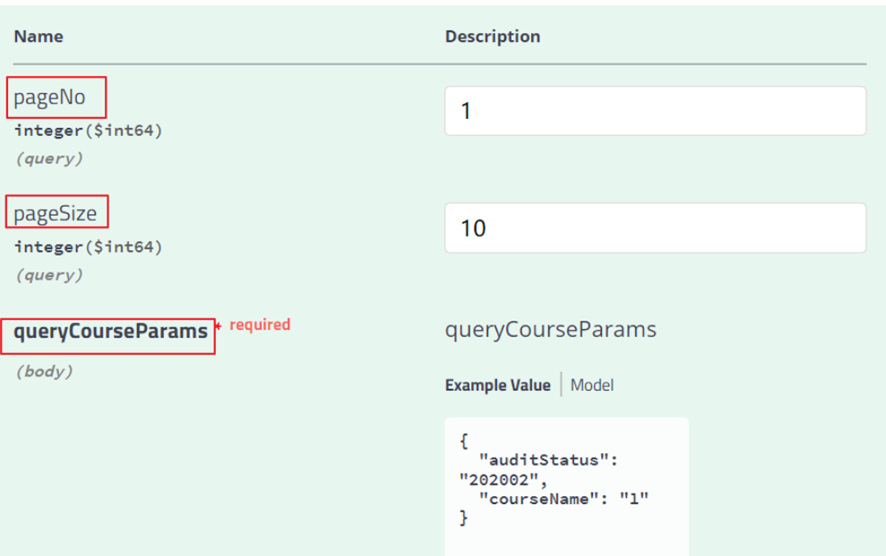
标注的方法非常简单:
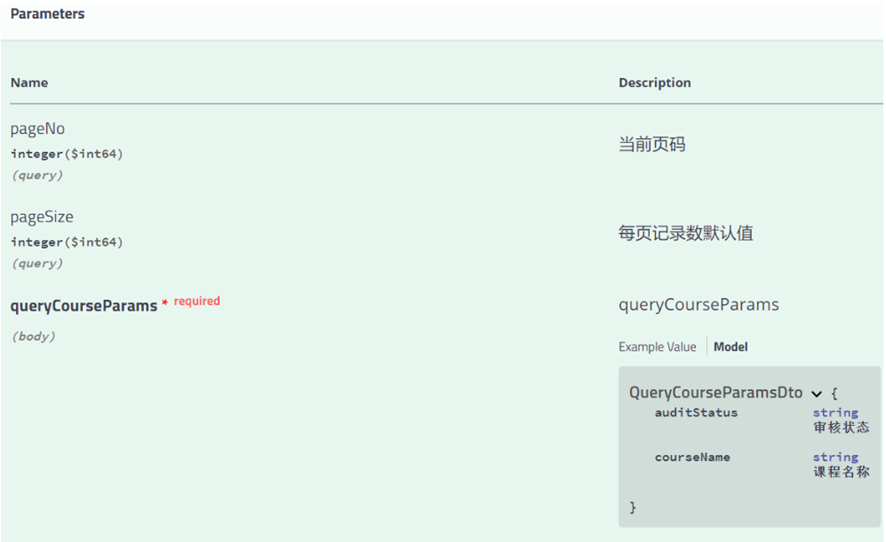
找到模型类,在属性上添加注解
public class PageParams {...
@ApiModelProperty("当前页码")
private Long pageNo = 1L;@ApiModelProperty("每页记录数默认值")
private Long pageSize = 30L;
...public class QueryCourseParamsDto {//审核状态@ApiModelProperty("审核状态")private String auditStatus;//课程名称@ApiModelProperty("课程名称")private String courseName;}重启服务,再次进入接口文档,如下图:
在Java类中添加Swagger的注解即可生成Swagger接口,常用Swagger注解如下:
- @Api:修饰整个类,描述Controller的作用
- @ApiOperation:描述一个类的一个方法,或者说一个接口
- @ApiParam:单个参数描述
- @ApiModel:用对象来接收参数
- @ApiModelProperty:用对象接收参数时,描述对象的一个字段
- @ApiResponse:HTTP响应其中1个描述
- @ApiResponses:HTTP响应整体描述
- @ApiIgnore:使用该注解忽略这个API
- @ApiError :发生错误返回的信息
- @ApiImplicitParam:一个请求参数
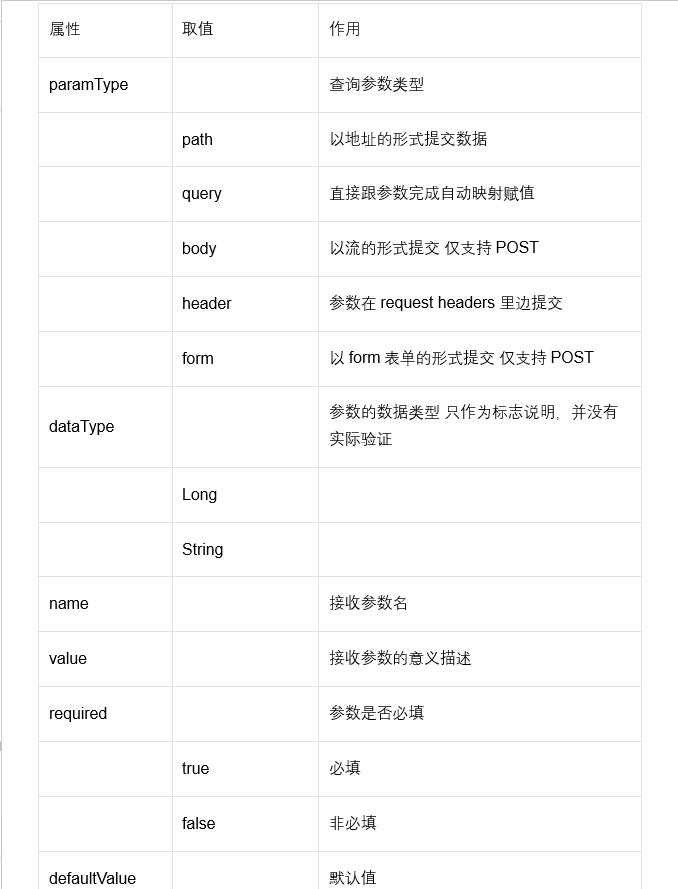
- @ApiImplicitParams:多个请求参数
@ApiImplicitParam属性如下:
MyBatis之ResultMap的使用
官方文档地址:
结果映射(resultMap)
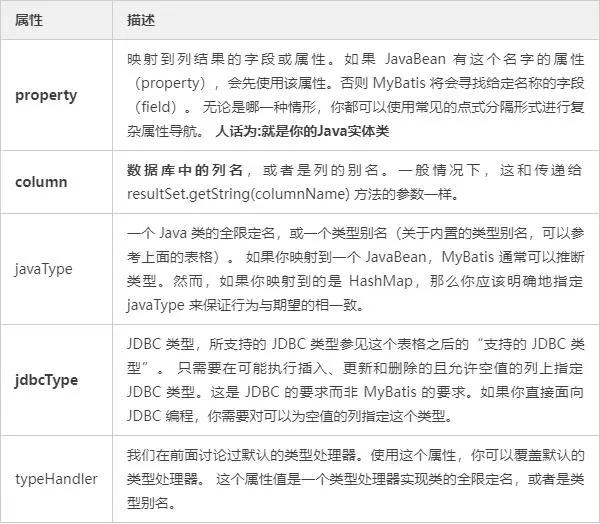
ResultMap 的属性列表:

ResultMap标签:

id & result标签参数详解:
association标签参数详解以及使用

@Data
//书籍
public class Book {private String id;private String name;private String author;private Double price;private Integer del;private Date publishdate;private String info;//把出版社对象当作属性private Publisher pub;//------重点在这里一本书对应一个出版社,这是一个出版社对象
}@Data
//出版社
public class Publisher {private String id;private String name;private String phone;private String address;
}
<resultMap id="rMap_book" type="com.wang.test.demo.entity.Book"><!-- 主键 property为实体类属性 column为数据库字段 jdbcType为实体类对应的jdbc类型--><id property="id" column="b_id" jdbcType="VARCHAR"></id><!-- 普通属性 property为实体类属性 column为数据库字段 jdbcType为实体类对应的jdbc类型--><result property="name" column="b_name" jdbcType="VARCHAR"></result><result property="author" column="author" jdbcType="VARCHAR"></result><result property="price" column="price" jdbcType="VARCHAR"></result><result property="del" column="del" jdbcType="NUMERIC"></result><result property="publisherid" column="publisher_id" jdbcType="VARCHAR"></result><result property="publishdate" column="publish_date" jdbcType="TIMESTAMP"></result><!--一对一映射association property 为实体类book中的属性名字 javaType为实体类属性的类型 --><association property="pub" javaType="com.wang.test.demo.entity.Publisher"><id property="id" column="p_id" jdbcType="VARCHAR"></id><result property="name" column="name" jdbcType="VARCHAR"></result><result property="phone" column="phone" jdbcType="VARCHAR"></result><result property="address" column="address" jdbcType="VARCHAR"></result></association>
</resultMap>
collection标签常用参数详解以及使用

@Data
//班级类
public class Class {private String id;private String name;private List<Student> students;//----重点在这里,一个班级对应多个学生}@Data
public class Student {private int id;private String name;private int age;
}
<resultMap id="rMap_class" type="com.wang.test.demo.entity.Class"><id property="id" column="id" jdbcType="VARCHAR"></id><result property="name" column="name" jdbcType="VARCHAR"></result><!--一对多映射用这个 ofTyp是一对多的集合的所存放的实体类 javaType实体类的属性类型--><collection property="students" ofType="com.wang.test.demo.entity.Student" javaType="list"><id property="id" column="id" jdbcType="INTEGER"></id><result property="name" column="name" jdbcType="VARCHAR"></result><result property="age" column="age" jdbcType="INTEGER"></result></collection>
</resultMap>
内容管理部分
树形结构查询
两种方法:
- 在树的层级固定的情况下:使用表的自连接
- 在树的层级不固定的情况下:使用mysql的递归查询
我们查询出来的结果是树各个节点组成的列表,所以我们在service层中要对查询结果进行处理,返回前端需要的结果:
[{"childrenTreeNodes" : [{"childrenTreeNodes" : null,"id" : "1-1-1","isLeaf" : null,"isShow" : null,"label" : "HTML/CSS","name" : "HTML/CSS","orderby" : 1,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-2","isLeaf" : null,"isShow" : null,"label" : "JavaScript","name" : "JavaScript","orderby" : 2,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-3","isLeaf" : null,"isShow" : null,"label" : "jQuery","name" : "jQuery","orderby" : 3,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-4","isLeaf" : null,"isShow" : null,"label" : "ExtJS","name" : "ExtJS","orderby" : 4,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-5","isLeaf" : null,"isShow" : null,"label" : "AngularJS","name" : "AngularJS","orderby" : 5,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-6","isLeaf" : null,"isShow" : null,"label" : "ReactJS","name" : "ReactJS","orderby" : 6,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-7","isLeaf" : null,"isShow" : null,"label" : "Bootstrap","name" : "Bootstrap","orderby" : 7,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-8","isLeaf" : null,"isShow" : null,"label" : "Node.js","name" : "Node.js","orderby" : 8,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-9","isLeaf" : null,"isShow" : null,"label" : "Vue","name" : "Vue","orderby" : 9,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-10","isLeaf" : null,"isShow" : null,"label" : "其它","name" : "其它","orderby" : 10,"parentid" : "1-1"}],"id" : "1-1","isLeaf" : null,"isShow" : null,"label" : "前端开发","name" : "前端开发","orderby" : 1,"parentid" : "1"},·······
我们的思路是:
- 将一级节点收集成一个map,并且将一级节点的ChildrenTreeNodes属性由null变为一个空列表,防止后面会出现空指针异常
- 遍历树的节点列表将二级节点放入到一级节点的childrenTreeNodes属性中
- 将map的values收集成一个列表返回
处理的过程中我们使用了JDK8中的stream流技术,代码如下:
public class CourseCategoryServiceImpl implements CourseCategoryService {@Resourceprivate CourseCategoryMapper courseCategoryMapper;/* 课程分类树形结构查询* @param id* @return*/@Overridepublic List<CourseCategoryTreeDto> queryTreeNodes(String id) {//首先通过mapper递归查询得到树的节点List<CourseCategoryTreeDto> courseCategoryTreeDtos = courseCategoryMapper.selectTreeNodes(id);//第一步将一级节点收集成一个map,并且将ChildrenTreeNodes属性由null变为一个空列表Map<String, CourseCategoryTreeDto> firstNodeMap = courseCategoryTreeDtos.stream().filter(item -> item.getParentid().equals("1")).map(item -> {item.setChildrenTreeNodes(new ArrayList<>());return item;}).collect(Collectors.toMap(//规定key的映射CourseCategory::getId,//规定value的映射item -> item,//规定合并的规则(item1, item2) -> item2));//遍历树的节点将二级节点放入到一级节点的childrenTreeNodes属性中for (CourseCategoryTreeDto courseCategoryTreeDto : courseCategoryTreeDtos) {//首先拿到父节点的idString parentid = courseCategoryTreeDto.getParentid();if (!firstNodeMap.containsKey(parentid)) continue;//添加CourseCategoryTreeDto firstNode = firstNodeMap.get(parentid);firstNode.getChildrenTreeNodes().add(courseCategoryTreeDto);}return new ArrayList<>(firstNodeMap.values());}
}
全局异常处理
在service方法中有很多的参数合法性校验,当参数不合法则抛出异常,下边我们测试下异常处理。
请求创建课程基本信息,故意将必填项设置为空。
测试发现报500异常,如下:
http://localhost:63040/content/courseHTTP/1.1 500
Content-Type: application/json
Transfer-Encoding: chunked
Date: Wed, 07 Sep 2022 11:40:29 GMT
Connection: close{"timestamp": "2022-09-07T11:40:29.677+00:00","status": 500,"error": "Internal Server Error","message": "","path": "/content/course"
}
-
问题:并没有输出我们抛出异常时指定的异常信息
-
我们要求当非正常流程时要获取异常信息进行记录,并提示给用户。异常处理除了输出在日志中,还需要提示给用户,前端和后端需要作一些约定:
- 错误提示信息统一以json格式返回给前端。
- 以HTTP状态码决定当前是否出错,非200为操作异常。
这里我们前端能显示后端抛出的异常信息就是因为前后端统一了异常对象:
前端: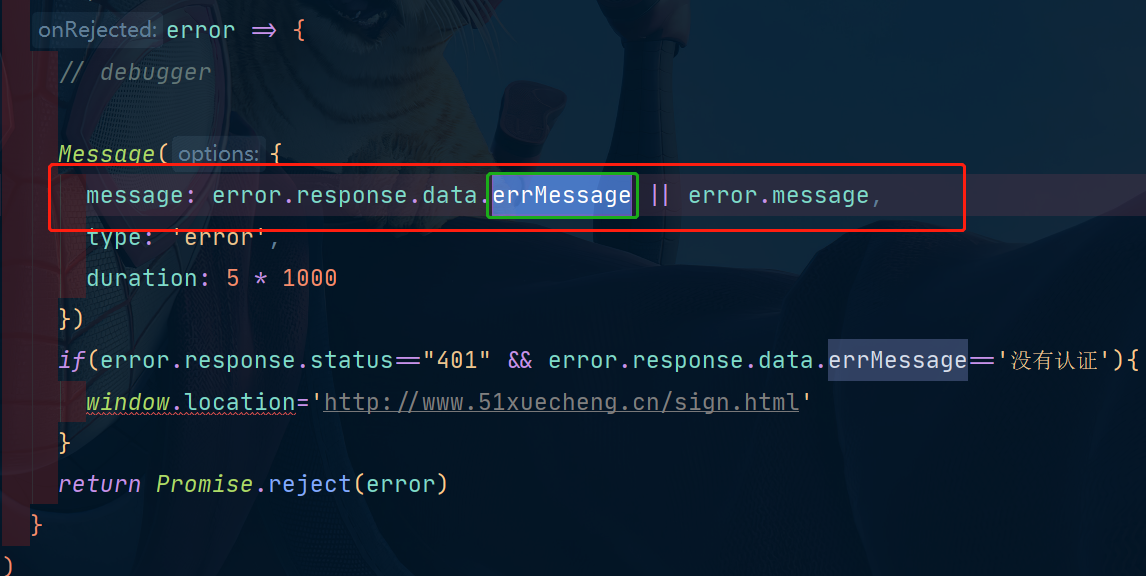
后端: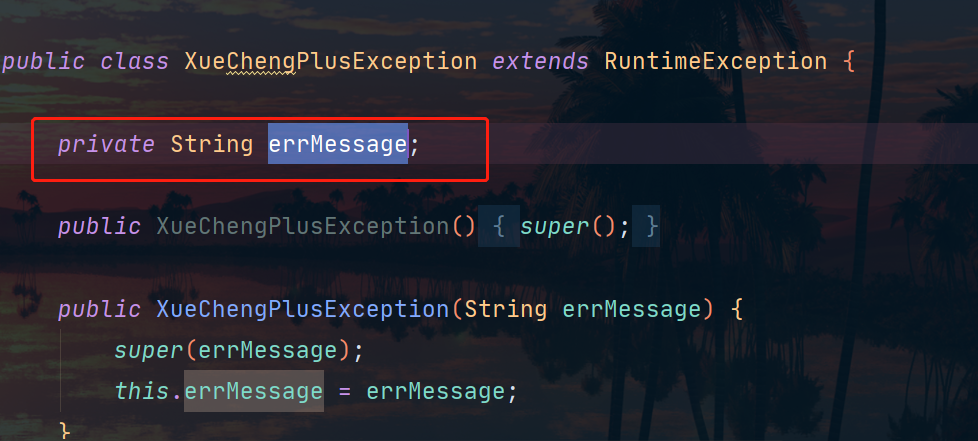
- 如何规范异常信息?
-
代码中统一抛出项目的自定义异常类型,这样可以统一去捕获这一类或几类的异常。规范了异常类型就可以去获取异常信息。如果捕获了非项目自定义的异常类型统一向用户提示“执行过程异常,请重试”的错误信息。
-
-
如何捕获异常?
- 代码统一用try/catch方式去捕获代码比较臃肿,可以通过SpringMVC提供的控制器增强类统一由一个类去完成异常的捕获。
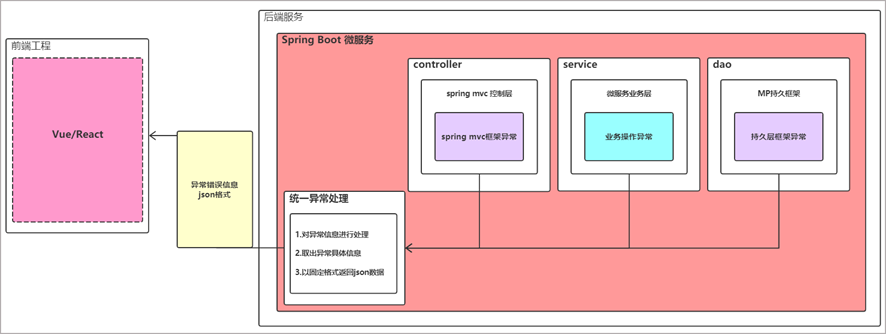
- 代码统一用try/catch方式去捕获代码比较臃肿,可以通过SpringMVC提供的控制器增强类统一由一个类去完成异常的捕获。
JSR303校验
前端请求后端接口传输参数,是在controller中校验还是在Service中校验?
答案是都需要校验,只是分工不同:
- Contoller中校验请求参数的合法性,包括:必填项校验,数据格式校验,比如:是否是符合一定的日期格式,等。
- Service中要校验的是业务规则相关的内容,比如:课程已经审核通过所以提交失败。
Service中根据业务规则去校验不方便写成通用代码,Controller中则可以将校验的代码写成通用代码。
早在JavaEE6规范中就定义了参数校验的规范,它就是JSR-303,它定义了Bean Validation,即对bean属性进行校验。SpringBoot提供了JSR-303的支持,它就是spring-boot-starter-validation,它的底层使用Hibernate Validator,Hibernate Validator是Bean Validation 的参考实现。
所以,我们准备在Controller层使用spring-boot-starter-validation完成对请求参数的基本合法性进行校验。
引入的相关依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId>
</dependency>
校验注解以及规则如下:
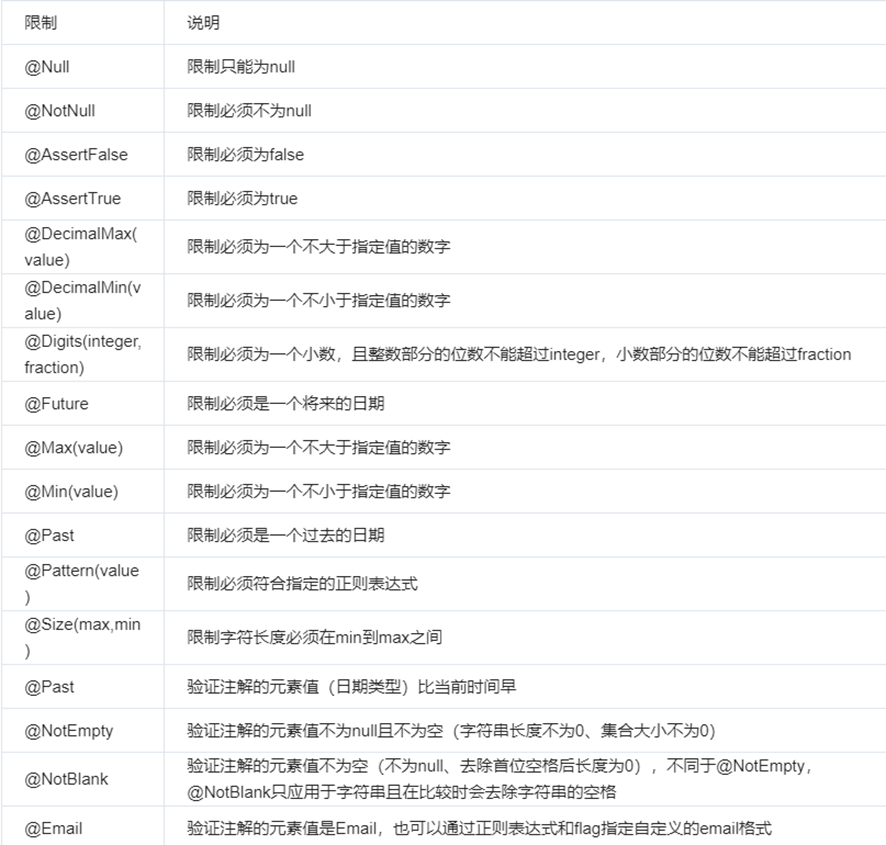
使用步骤:
- 引入依赖
- 在模型类的属性上添加校验注解
- 在Controller的模型类之前使用@Validated注解,开启校验
- 校验出错Spring会抛出MethodArgumentNotValidException异常,我们需要在统一异常处理器中捕获异常,解析出异常信息
@ResponseBody
@ExceptionHandler(MethodArgumentNotValidException.class)
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
public RestErrorResponse methodArgumentNotValidException(MethodArgumentNotValidException e) {BindingResult bindingResult = e.getBindingResult();List<String> msgList = new ArrayList<>();//将错误信息放在msgListbindingResult.getFieldErrors().stream().forEach(item->msgList.add(item.getDefaultMessage()));//拼接错误信息String msg = StringUtils.join(msgList, ",");log.error("【系统异常】{}",msg);return new RestErrorResponse(msg);
}
分组校验
有时候在同一个属性上设置一个校验规则不能满足要求,比如:订单编号由系统生成,在添加订单时要求订单编号为空,在更新 订单时要求订单编写不能为空。此时就用到了分组校验,同一个属性定义多个校验规则属于不同的分组,比如:添加订单定义@NULL规则属于insert分组,更新订单定义@NotEmpty规则属于update分组,insert和update是分组的名称,是可以修改的。
下边举例说明
我们用class类型来表示不同的分组,所以我们定义不同的接口类型(空接口)表示不同的分组,由于校验分组是公用的,所以定义在 base工程中。如下:
package com.xuecheng.base.execption;/* @description 校验分组* @author Mr.M* @date 2022/9/8 15:05* @version 1.0*/
public class ValidationGroups {public interface Inster{};public interface Update{};public interface Delete{};}
下边在定义校验规则时指定分组:
@NotEmpty(groups = {ValidationGroups.Inster.class},message = "添加课程名称不能为空")@NotEmpty(groups = {ValidationGroups.Update.class},message = "修改课程名称不能为空")
// @NotEmpty(message = "课程名称不能为空")@ApiModelProperty(value = "课程名称", required = true)private String name;
在Controller方法中启动校验规则指定要使用的分组名:
@ApiOperation("新增课程基础信息")
@PostMapping("/course")
public CourseBaseInfoDto createCourseBase(@RequestBody @Validated({ValidationGroups.Inster.class}) AddCourseDto addCourseDto){//机构id,由于认证系统没有上线暂时硬编码Long companyId = 1L;return courseBaseInfoService.createCourseBase(companyId,addCourseDto);
}
再次测试,由于这里指定了Insert分组,所以抛出 异常信息:添加课程名称不能为空。
如果修改分组为ValidationGroups.Update.class,异常信息为:修改课程名称不能为空。
查询课程计划
我们这里也是一个树形结构的查询,前面我们查询出来之后是在业务层使用stream流进行处理之后再返回给前端。这里我们使用另外一种处理查询出来的数据,也就是mybatis自带的ResultMap。
我们想要如下的结构:

我们将查询出来的结果经过ResultMap的映射之后就可以得到我们想要的形式:
你可以简单地理解为ResultMap就是把查询到的每一条数据,按照你配置的规则映射到你给定的模型类中去。
<!-- 课程分类树型结构查询映射结果 --><resultMap id="treeNodeResultMap" type="com.xuecheng.content.model.dto.TeachplanDto"><!-- 一级数据映射 --><id column="one_id" property="id" /><result column="one_pname" property="pname" /><result column="one_parentid" property="parentid" /><result column="one_grade" property="grade" /><result column="one_mediaType" property="mediaType" /><result column="one_stratTime" property="stratTime" /><result column="one_endTime" property="endTime" /><result column="one_orderby" property="orderby" /><result column="one_courseId" property="courseId" /><result column="one_coursePubId" property="coursePubId" /><!-- 一级中包含多个二级数据 --><collection property="teachPlanTreeNodes" ofType="com.xuecheng.content.model.dto.TeachplanDto"><!-- 二级数据映射 --><id column="two_id" property="id" /><result column="two_pname" property="pname" /><result column="two_parentid" property="parentid" /><result column="two_grade" property="grade" /><result column="two_mediaType" property="mediaType" /><result column="two_stratTime" property="stratTime" /><result column="two_endTime" property="endTime" /><result column="two_orderby" property="orderby" /><result column="two_courseId" property="courseId" /><result column="two_coursePubId" property="coursePubId" /><association property="teachplanMedia" javaType="com.xuecheng.content.model.po.TeachplanMedia"><result column="teachplanMeidaId" property="id" /><result column="mediaFilename" property="mediaFilename" /><result column="mediaId" property="mediaId" /><result column="two_id" property="teachplanId" /><result column="two_courseId" property="courseId" /><result column="two_coursePubId" property="coursePubId" /></association></collection></resultMap><!--课程计划树型结构查询--><select id="selectTreeNodes" resultMap="treeNodeResultMap" parameterType="long" >selectone.id one_id,one.pname one_pname,one.parentid one_parentid,one.grade one_grade,one.media_type one_mediaType,one.start_time one_stratTime,one.end_time one_endTime,one.orderby one_orderby,one.course_id one_courseId,one.course_pub_id one_coursePubId,two.id two_id,two.pname two_pname,two.parentid two_parentid,two.grade two_grade,two.media_type two_mediaType,two.start_time two_stratTime,two.end_time two_endTime,two.orderby two_orderby,two.course_id two_courseId,two.course_pub_id two_coursePubId,m1.media_fileName mediaFilename,m1.id teachplanMeidaId,m1.media_id mediaIdfrom teachplan oneLEFT JOIN teachplan two on one.id = two.parentidLEFT JOIN teachplan_media m1 on m1.teachplan_id = two.idwhere one.parentid = 0 and one.course_id=#{value}order by one.orderby,two.orderby</select>
注意这里的自连接要使用left join 如果使用inner join的话,我们在新增章节时候是查询不出来的(也就是不会显示)。
项目实战部分
这一部分文档里面没有给出代码,所以这里给出我的代码供大家参考。
删除课程计划
注意点如下:
- 删除第一级别的大章节时要求大章节下边没有小章节时方可删除。
- 删除第二级别的小章节的同时需要将teachplan_media表关联的信息也删除。
接口:
Request URL: /content/teachplan/246
Request Method: DELETE如果失败返回:
{"errCode":"120409","errMessage":"课程计划信息还有子级信息,无法操作"}如果成功:状态码200,不返回信息
业务层代码:
@Resourceprivate TeachplanMediaMapper teachplanMediaMapper;/* 删除课程计划* @param teachplanId*/@Override@Transactionalpublic void deleteTeachplan(Long teachplanId) {//首先判断该课程计划是大章节还是小章节Teachplan teachplan = teachplanMapper.selectById(teachplanId);//如果不存在则直接返回错误if (teachplan == null) {throw new XueChengPlusException("该课程信息不存在");}if (teachplan.getGrade().equals(1)) {//说明是大章节//判断此大章节下是否有小章节LambdaQueryWrapper<Teachplan> teachplanLambdaQueryWrapper = new LambdaQueryWrapper<>();teachplanLambdaQueryWrapper.eq(Teachplan::getParentid,teachplan.getId());Integer count = teachplanMapper.selectCount(teachplanLambdaQueryWrapper);if (count > 0) {//说明大章节下有小章节,返回错误throw new XueChengPlusException("课程计划信息还有子级信息,无法操作");}//执行删除操作teachplanMapper.deleteById(teachplanId);return;}//说明是小章节//首先删除小章节int i = teachplanMapper.deleteById(teachplanId);if (i > 0) {//删除小章节成功再删除媒资信息LambdaQueryWrapper<TeachplanMedia> teachplanMediaLambdaQueryWrapper = new LambdaQueryWrapper<>();teachplanMediaLambdaQueryWrapper.eq(TeachplanMedia::getTeachplanId,teachplanId);teachplanMediaMapper.delete(teachplanMediaLambdaQueryWrapper);}}课程计划排序
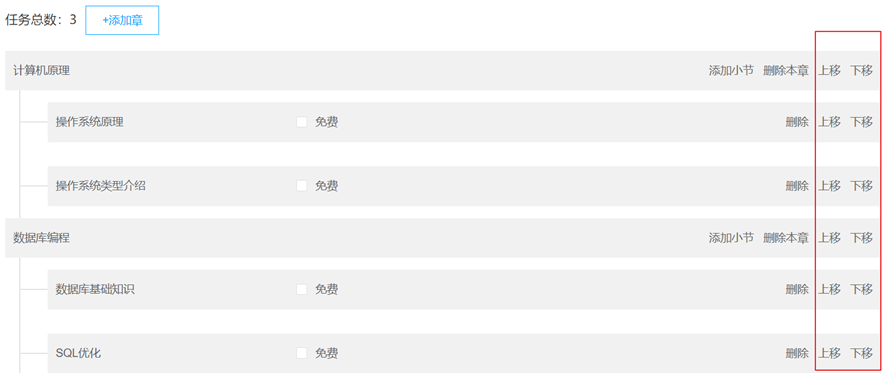
注意点;
- 向上移动后和上边同级的课程计划交换位置,可以将两个课程计划的排序字段值进行交换
- 向下移动后和下边同级的课程计划交换位置,可以将两个课程计划的排序字段值进行交换
- 边缘位置的判断
- 第一名的上移
- 最后一名的下移
接口定义:
向下移动:
Request URL: http://localhost:8601/api/content/teachplan/movedown/43
Request Method: POST
- 参数1:movedown 为 移动类型,表示向下移动
- 参数2:43为课程计划id
向上移动:
Request URL: http://localhost:8601/api/content/teachplan/moveup/43
Request Method: POST
- 参数1:moveup 为 移动类型,表示向上移动
- 参数2:43为课程计划id
每次移动传递两个参数:
- 移动类型: movedown和moveup
- 课程计划id
业务代码如下:
/* 控制课程计划的上下移动* @param type* @param id*/@Override@Transactionalpublic void moveTeachplan(String type, Long id) {//首先判断该课程计划是否存在Teachplan teachplan = teachplanMapper.selectById(id);if (teachplan == null) {throw new XueChengPlusException("该课程计划不存在");}//获取当前课程计划的同级课程计划个数,为后面的业务做准备LambdaQueryWrapper<Teachplan> teachplanLambdaQueryWrapper = new LambdaQueryWrapper<>();teachplanLambdaQueryWrapper.eq(Teachplan::getCourseId,teachplan.getCourseId()).eq(Teachplan::getGrade,teachplan.getGrade()).eq(Teachplan::getParentid,teachplan.getParentid());Integer count = teachplanMapper.selectCount(teachplanLambdaQueryWrapper);//查询当前课程计划的排序序号Integer orderby = teachplan.getOrderby();//处理向上移动的情况if ("moveup".equals(type)) {//如果是第一位则不做任何处理if (orderby.equals(1)) {return;}//获得前面的planTeachplan teachplanSwap = teachplanMapper.selectOne(teachplanLambdaQueryWrapper.eq(Teachplan::getOrderby, orderby - 1));//将当前plan排序-1LambdaUpdateWrapper<Teachplan> teachplanLambdaUpdateWrapper = new LambdaUpdateWrapper<>();teachplanLambdaUpdateWrapper.set(Teachplan::getOrderby,orderby - 1).eq(Teachplan::getId,teachplan.getId());teachplanMapper.update(null,teachplanLambdaUpdateWrapper);//将前面plan的排序 + 1teachplanMapper.update(null,new LambdaUpdateWrapper<Teachplan>().set(Teachplan::getOrderby, teachplanSwap.getOrderby() + 1).eq(Teachplan::getId, teachplanSwap.getId()));return;}//处理向下移动的情况//如果是最后一位则不做任何处理if (orderby.equals(count)) {return;}//获得后面的planTeachplan teachplanSwap = teachplanMapper.selectOne(teachplanLambdaQueryWrapper.eq(Teachplan::getOrderby, orderby + 1));//将当前plan排序+1LambdaUpdateWrapper<Teachplan> teachplanLambdaUpdateWrapper = new LambdaUpdateWrapper<>();teachplanLambdaUpdateWrapper.set(Teachplan::getOrderby,orderby + 1).eq(Teachplan::getId,teachplan.getId());;teachplanMapper.update(null,teachplanLambdaUpdateWrapper);//将后面plan的排序 - 1teachplanMapper.update(null,new LambdaUpdateWrapper<Teachplan>().set(Teachplan::getOrderby,teachplanSwap.getOrderby() - 1).eq(Teachplan::getId, teachplanSwap.getId()));}两个注意点:
- 判定同一级别的条件
- 同一个courseid
- 同一个grade
- 同一个parentid
- 我们在获取排在前面或者后面的元素的时候,一定是在当前元素更新之前,如果在更新之后去获取,会得到两个结果(更新之后当前元素的order发生了变化)而报错。
师资管理
查询教师接口:
get /courseTeacher/list/75
75为课程id,请求参数为课程id响应结果
[{"id":23,"courseId":75,"teacherName":"张老师","position":"讲师","introduction":"张老师教师简介张老师教师简介张老师教师简介张老师教师简介","photograph":null,"createDate":null}]
添加教师接口:
post /courseTeacher请求参数:
{"courseId": 75,"teacherName": "王老师","position": "教师职位","introduction": "教师简介"
}
响应结果:
{"id":24,"courseId":75,"teacherName":"王老师","position":"教师职位","introduction":"教师简介","photograph":null,"createDate":null}
修改教师接口:
post /courseTeacher
请求参数:
{"id": 24,"courseId": 75,"teacherName": "王老师","position": "教师职位","introduction": "教师简介","photograph": null,"createDate": null
}
响应:
{"id":24,"courseId":75,"teacherName":"王老师","position":"教师职位","introduction":"教师简介","photograph":null,"createDate":null}
删除教师接口:
delete /ourseTeacher/course/75/2675:课程id
26:教师id,即course_teacher表的主键
请求参数:课程id、教师id响应:状态码200,不返回信息
注意:
- 只允许向机构自己的课程中添加老师、删除老师
业务代码:
/* @author 十八岁讨厌编程* @date 2023/4/8 12:23* @PROJECT_NAME xuecheng_plus* @description*/@Service
public class CourseTeacherServiceImpl implements CourseTeacherService {@Resourceprivate CourseTeacherMapper courseTeacherMapper;/* 教师列表查询* @param id* @return*/@Overridepublic List<CourseTeacher> courseTeacherList(Long id) {LambdaQueryWrapper<CourseTeacher> courseTeacherLambdaQueryWrapper = new LambdaQueryWrapper<>();courseTeacherLambdaQueryWrapper.eq(CourseTeacher::getCourseId,id);return courseTeacherMapper.selectList(courseTeacherLambdaQueryWrapper);}/* 添加&修改教师* @param dto* @return*/@Overridepublic CourseTeacher courseTeacherAddOrUpdate(CourseTeacher dto) {//如果没有id说明为添加if (dto.getId() == null) {CourseTeacher courseTeacher = new CourseTeacher();BeanUtils.copyProperties(dto,courseTeacher);courseTeacherMapper.insert(courseTeacher);return courseTeacherMapper.selectOne(new LambdaQueryWrapper<CourseTeacher>().eq(CourseTeacher::getCourseId,dto.getCourseId()).eq(CourseTeacher::getTeacherName,dto.getTeacherName()));}//有id说明为修改courseTeacherMapper.updateById(dto);return courseTeacherMapper.selectById(dto.getId());}/* 删除教师* @param courseId* @param teacherId*/@Overridepublic void courseTeacherDelete(Long courseId, Long teacherId) {courseTeacherMapper.delete(new LambdaQueryWrapper<CourseTeacher>().eq(CourseTeacher::getCourseId,courseId).eq(CourseTeacher::getId,teacherId));}}
删除课程
删除课程接口;
delete /course/87
87为课程id
请求参数:课程id
响应:状态码200,不返回信息
注意:
- 课程的审核状态为未提交时方可删除(也就是auditStatus为202002)
- 删除课程需要删除课程相关的基本信息、营销信息、课程计划、课程教师信息
/* 删除课程信息* @param courseId*/@Override@Transactionalpublic void deleteCourseBase(Long courseId) {//判断审核状态CourseBase courseBase = courseBaseMapper.selectById(courseId);if (!courseBase.getAuditStatus().equals("202002")) return;//审核状态为未提交时方可删除//删除基本信息courseBaseMapper.deleteById(courseId);//删除营销信息courseMarketMapper.deleteById(courseId);//删除课程计划teachplanMapper.delete(new LambdaQueryWrapper<Teachplan>().eq(Teachplan::getCourseId,courseId));//删除课程计划的媒资信息teachplanMediaMapper.delete(new LambdaQueryWrapper<TeachplanMedia>().eq(TeachplanMedia::getCourseId,courseId));//删除课程教师信息courseTeacherMapper.delete(new LambdaQueryWrapper<CourseTeacher>().eq(CourseTeacher::getCourseId,courseId));}