《MongoDB入门教程》第27篇 创建索引

本文将会介绍 MongoDB 中的索引概念,以及如何利用 createIndex() 方法创建索引。
索引简介
假设存在一本包含介绍各种电影的图书。

如果想要查找一部名为“Pirates of Silicon Valley”的电影,我们需要翻阅每一页,直到发现该电影的介绍为止。

显然,这种查找方法效率低下。如果这本书包含一个内容索引,记录了电影的标题及对应的页码,我们就可以通过索引快速找到相应的电影介绍:
Pimpernel' Smith 1
...
Pirates of Silicon Valley 201
...
Twas the Night 300
在上面的索引信息中,电影“Pirates of Silicon Valley”位于这本书的 201 页。因此,我们可以直接打开 201 页查看相应的介绍:

从这个示例可以看出,索引可以更快地查找数据。
MongoDB 索引的工作方式和上面的示例类似,我们可以基于文档集合中的指定字段创建索引。MongoDB 使用 B-树 结构存储索引。
另一方面,当我们插入、更新或者删除文档时, MongoDB 需要维护相应的索引。也就是说,索引提高了文件的检索性能,但是需要以额外的写入和存储空间为代价。因此,应该建立合适的索引,而不是尽可能多的索引。
查看索引
我们首先创建一个新的 movies 集合,然后通过 MongoDB Compass 导入初始化数据(movies.json):
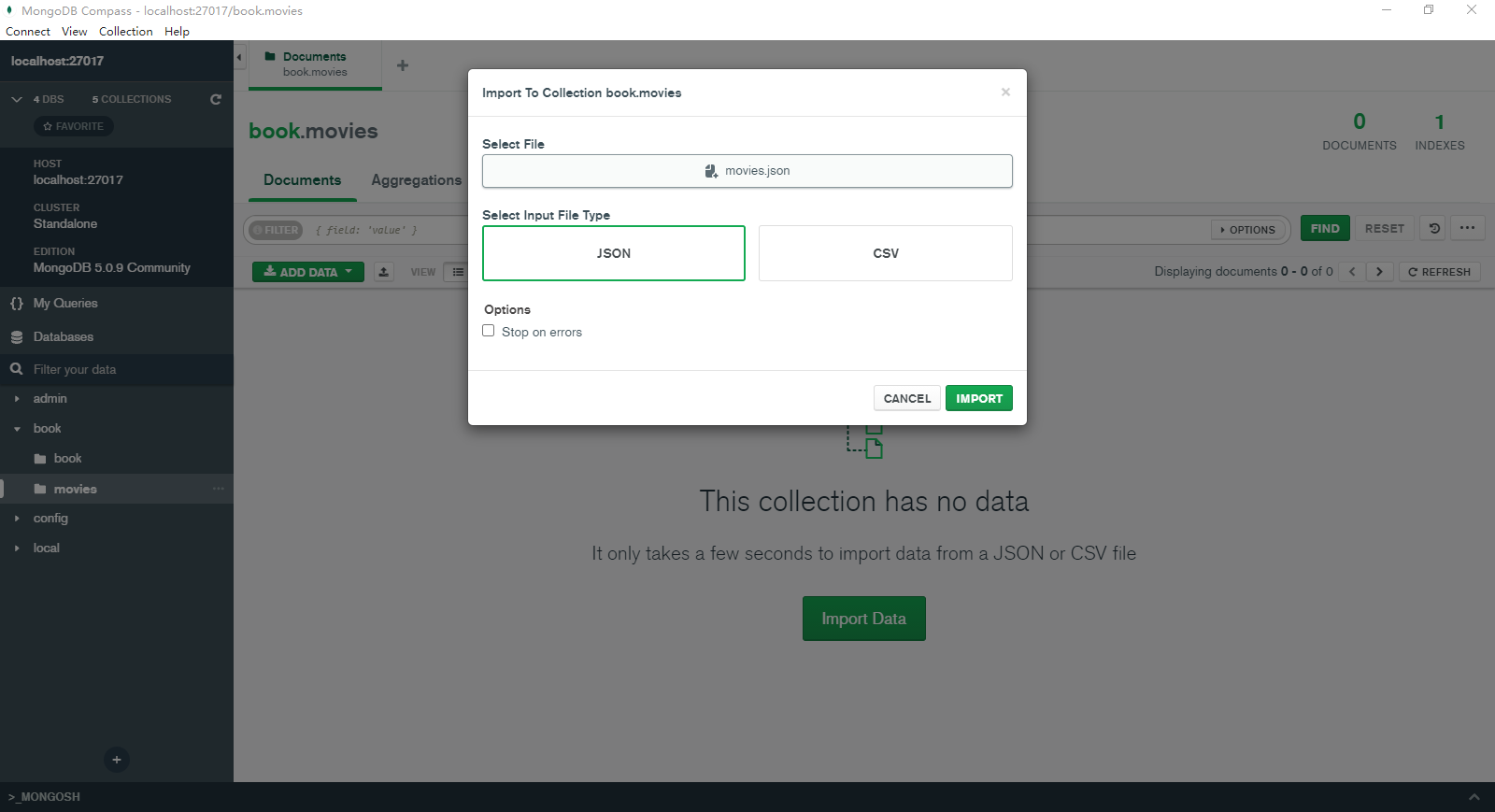
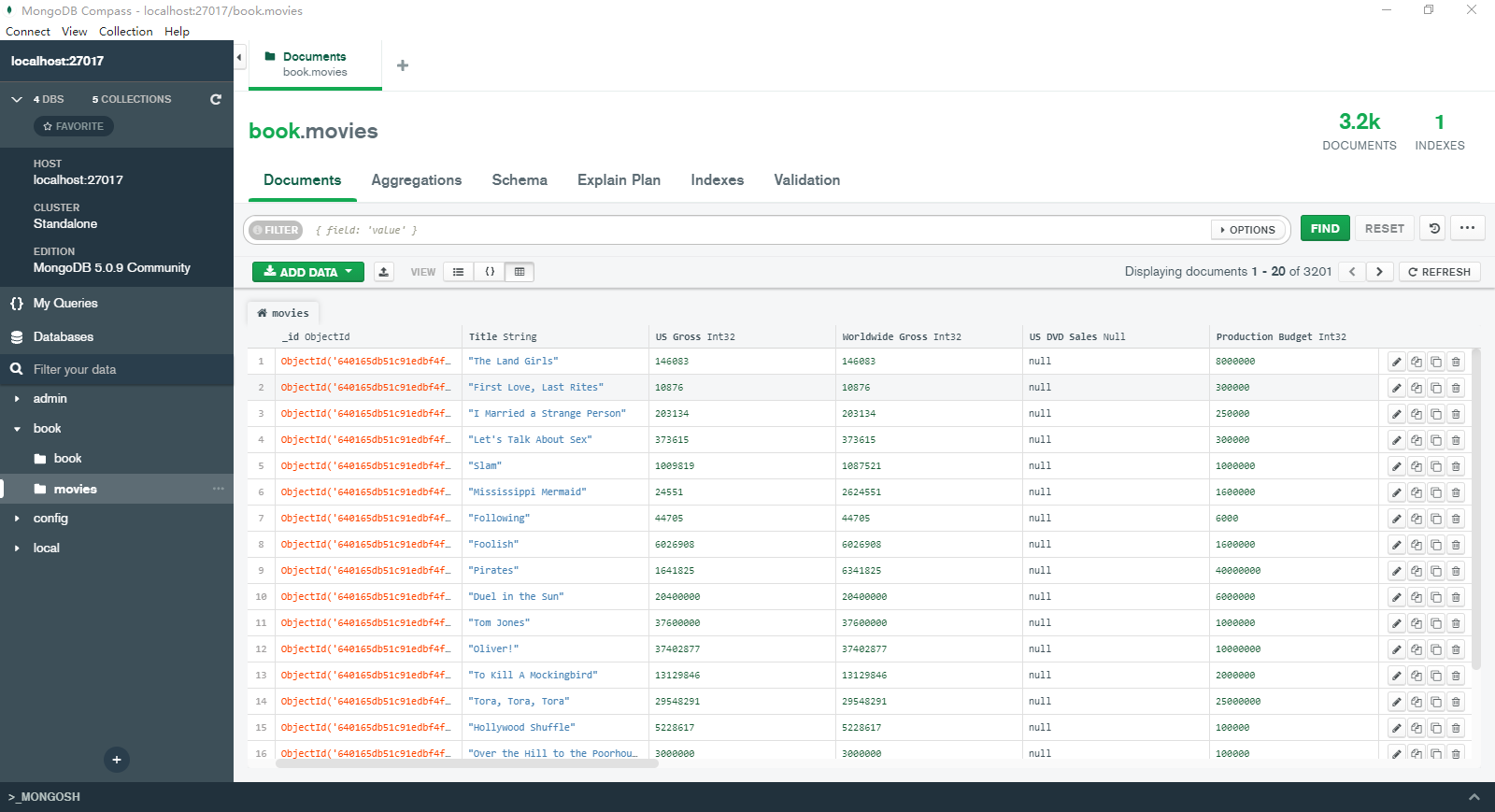
默认情况下,所有的集合都拥有一个 _id 字段索引。getIndexes() 方法可以用于查看集合中的索引,语法如下:
db.collection.getIndexes()
以下命令可以查看集合 movies 中的索引:
db.movies.getIndexes()[ { v: 2, key: { _id: 1 }, name: '_id_' } ]
输出结果中的索引名称为“_id_”,索引字段为 _id。{ _id : 1 } 中的数字 1 代表了升序索引。
执行计划
以下查询用于查找电影“The Lake House”:
db.movies.find({Title: 'The Lake House'
}){ _id: ObjectId("640165db51c91edbf4fa413f"),Title: 'The Lake House','US Gross': 52330111,'Worldwide Gross': 114830111,'US DVD Sales': 39758509,'Production Budget': 40000000,'Release Date': 'Jun 16 2006','MPAA Rating': 'PG','Running Time min': null,Distributor: 'Warner Bros.',Source: 'Remake','Major Genre': 'Drama','Creative Type': 'Fantasy',Director: null,'Rotten Tomatoes Rating': 36,'IMDB Rating': 6.8,'IMDB Votes': 36613 }
为了查找该电影,MongoDB 需要扫描 movies 集合。在执行查询之前,MongoDB 查询计划器会选择最有效的执行计划。explain() 方法可以用于获取执行计划的相关信息。例如:
db.movies.find({Title: 'The Lake House'
}).explain('executionStats'){ explainVersion: '1',queryPlanner: { namespace: 'book.movies',indexFilterSet: false,parsedQuery: { Title: { '$eq': 'The Lake House' } },maxIndexedOrSolutionsReached: false,maxIndexedAndSolutionsReached: false,maxScansToExplodeReached: false,winningPlan: { stage: 'COLLSCAN',filter: { Title: { '$eq': 'The Lake House' } },direction: 'forward' },rejectedPlans: [] },executionStats: { executionSuccess: true,nReturned: 1,executionTimeMillis: 2,totalKeysExamined: 0,totalDocsExamined: 3201,executionStages: { stage: 'COLLSCAN',filter: { Title: { '$eq': 'The Lake House' } },nReturned: 1,executionTimeMillisEstimate: 0,works: 3203,advanced: 1,needTime: 3201,needYield: 0,saveState: 4,restoreState: 4,isEOF: 1,direction: 'forward',docsExamined: 3201 } },command: { find: 'movies',filter: { Title: 'The Lake House' },'$db': 'book' },serverInfo: { host: 'LAPTOP-DGRB6HD9',port: 27017,version: '5.0.9',gitVersion: '6f7dae919422dcd7f4892c10ff20cdc721ad00e6' },serverParameters: { internalQueryFacetBufferSizeBytes: 104857600,internalQueryFacetMaxOutputDocSizeBytes: 104857600,internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,internalDocumentSourceGroupMaxMemoryBytes: 104857600,internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,internalQueryProhibitBlockingMergeOnMongoS: 0,internalQueryMaxAddToSetBytes: 104857600,internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600 },ok: 1 }
explain() 方法返回了大量的信息,我们首先需要关注 winningPlan 部分:
...winningPlan: { stage: 'COLLSCAN',filter: { Title: { '$eq': 'The Lake House' } },direction: 'forward' },
...
winningPlan 返回了查询优化器最终选择的执行计划。示例中的 COLLSCAN 代表了集合扫描。
另外,executionStats 显示查询结果中包含 1 个文档,执行时间为 2 毫秒。
创建索引
createIndex() 方法可以用于创建新的索引。例如,以下命令可以为 movies 集合的 Title 字段创建索引:
db.movies.createIndex({Title:1})'Title_1'
参数 { Title: 1} 包含了字段名和一个数值:
- Title 字段是索引键;
- 数值 1 表示按照字段的值从小到大创建升序索引,-1 表示从大到小创建降序索引。
createIndex() 方法返回了索引的名称。示例中创建的索引 Title_1 由字段名和数值 1(表示升序)组成。
再次查看集合 movies 中的索引:
db.movies.getIndexes()[{ v: 2, key: { _id: 1 }, name: '_id_' },{ v: 2, key: { Title: 1 }, name: 'Title_1' }
]
再次使用 explain() 方法查看上文中查询语句的执行计划和统计信息:
db.movies.find({Title: 'The Lake House'
}).explain('executionStats'){ explainVersion: '1',queryPlanner: { namespace: 'book.movies',indexFilterSet: false,parsedQuery: { Title: { '$eq': 'The Lake House' } },maxIndexedOrSolutionsReached: false,maxIndexedAndSolutionsReached: false,maxScansToExplodeReached: false,winningPlan: { stage: 'FETCH',inputStage: { stage: 'IXSCAN',keyPattern: { Title: 1 },indexName: 'Title_1',isMultiKey: false,multiKeyPaths: { Title: [] },isUnique: false,isSparse: false,isPartial: false,indexVersion: 2,direction: 'forward',indexBounds: { Title: [ '["The Lake House", "The Lake House"]' ] } } },rejectedPlans: [] },executionStats: { executionSuccess: true,nReturned: 1,executionTimeMillis: 0,totalKeysExamined: 1,totalDocsExamined: 1,executionStages: { stage: 'FETCH',nReturned: 1,executionTimeMillisEstimate: 0,works: 2,advanced: 1,needTime: 0,needYield: 0,saveState: 0,restoreState: 0,isEOF: 1,docsExamined: 1,alreadyHasObj: 0,inputStage: { stage: 'IXSCAN',nReturned: 1,executionTimeMillisEstimate: 0,works: 2,advanced: 1,needTime: 0,needYield: 0,saveState: 0,restoreState: 0,isEOF: 1,keyPattern: { Title: 1 },indexName: 'Title_1',isMultiKey: false,multiKeyPaths: { Title: [] },isUnique: false,isSparse: false,isPartial: false,indexVersion: 2,direction: 'forward',indexBounds: { Title: [ '["The Lake House", "The Lake House"]' ] },keysExamined: 1,seeks: 1,dupsTested: 0,dupsDropped: 0 } } },command: { find: 'movies',filter: { Title: 'The Lake House' },'$db': 'book' },serverInfo: { host: 'LAPTOP-DGRB6HD9',port: 27017,version: '5.0.9',gitVersion: '6f7dae919422dcd7f4892c10ff20cdc721ad00e6' },serverParameters: { internalQueryFacetBufferSizeBytes: 104857600,internalQueryFacetMaxOutputDocSizeBytes: 104857600,internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,internalDocumentSourceGroupMaxMemoryBytes: 104857600,internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,internalQueryProhibitBlockingMergeOnMongoS: 0,internalQueryMaxAddToSetBytes: 104857600,internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600 },ok: 1 }
此时,查询优化器选择了索引扫描(IXSCAN),而不是集合扫描(COLLSCAN)。执行时间下降到了 0 毫秒。