目标检测之yolo系列模型-yolov4/yolox

文章目录
-
- 一、yolov4较yolov3的优化点
- 二、yolox较yolov4的优化点
-
- 2.1 网络更新--解耦检测头
- 2.2 Anchor-Free机制以及优缺点
-
- 2.2.1 (附录) Anchor-based机制的优缺点
- 2.3 *更先进的正负样本匹配策略(simOTA)*
- 三、focal loss
-
- 3.1 背景
- 3.2 做法
- 3.3 更细节
一、yolov4较yolov3的优化点
https://www.cnblogs.com/cucwwb/p/13166288.html
- 总结:
(1)对主干网络进行了修改,将原先的Darknet53改为CSPDarknet53,其中是将激活函数改为Mish激活函数,并且在网络中加入了CSP结构。
(2)对特征提取过程的加强,添加了SPP,PANet结构。
(3)在数据预处理阶段加入Mosaic方法。
(4)在损失函数中做了改进使用了CIOU作为回归Loss。
Mish()=x×tanh(ln(1+ex))Mish() = x×tanh(ln^{(1+e^x)})Mish()=x×tanh(ln(1+ex))
1.1 网络结构层面
(1) CSPDarknet53(借用CSP结构)
CSP是可以增强CNN学习能力的新型结构,CSPNet将底层的特征映射分为两部分,一部分经过密集块和过渡层,另一部分与传输的特征映射结合到下一阶段。
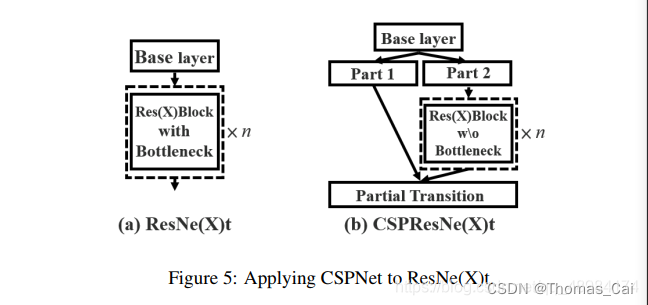
原文表达的作用:
加快网络的推理速度,减少对显存的使用,并且提升网络的学习能力。
- 更强的CNN的学习能力;
- 移除计算瓶颈;
- 减小使用的内存;
原文通过通道分割,但实际上不是,代码中是先用卷积下采样,然后分别输入两个conv结构中。
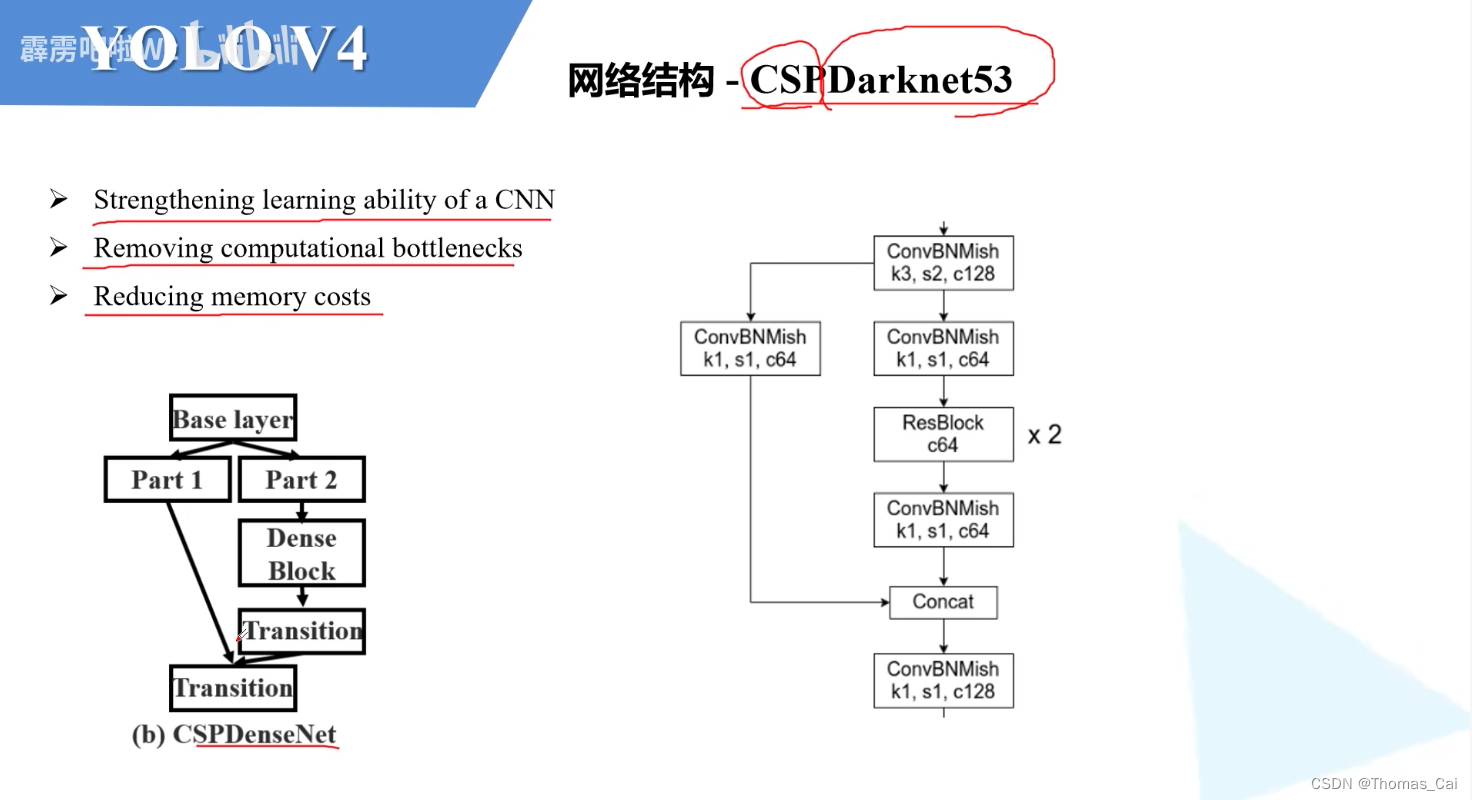
(2) SPP
优点:解决多尺度的问题
分别经过卷积和大小5X5,步距为1,padding为2;卷积和大小9X9,步距为1,padding为4;卷积和大小13X13,步距为1,padding为6;输出都是13X13X2046,和原始的拼接起来,最后的shape为13X13X2046。
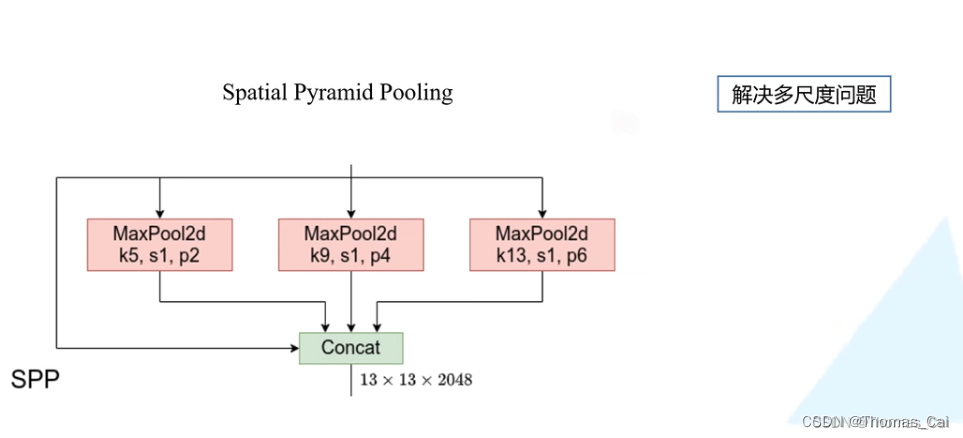
附:卷积和的计算公式
output=input−keral+padding∗2stride+1output = \\frac{input - keral + padding * 2}{stride} + 1output=strideinput−keral+padding∗2+1
(3) PAN(借用PANet)
上采样:FPN
上采样+下采样:PAN
特征融合:CONCAT策略,在深度方向进行拼接
1.2 优化策略
(1) mosaic 4张不同的图片拼接起来
(2) ciou
IOU:一般的iou,两个框的交集除以并集
GIOU:= iou−((AC−U)/AC)iou - ((AC-U)/AC)iou−((AC−U)/AC)
其中, AC为两个框的外接矩形的面积,U为两个框的并集的面积
缺点:
- 当两个框并列时,退化为IOU计算公式;
- 两个框,小框在大框中时,无法衡量两个框的位置关系,基于这一点提出DIOU;
DIOU:= iou−(d2/c2)iou - (d^2 / c^2)iou−(d2/c2)
其中d为两个框中心点的距离,c为两个框外接矩形的对角线的距离
CIOU:= iou−(d2/c2+av)iou - (d^2 / c^2 + av)iou−(d2/c2+av)
考虑到了距离和框的宽高

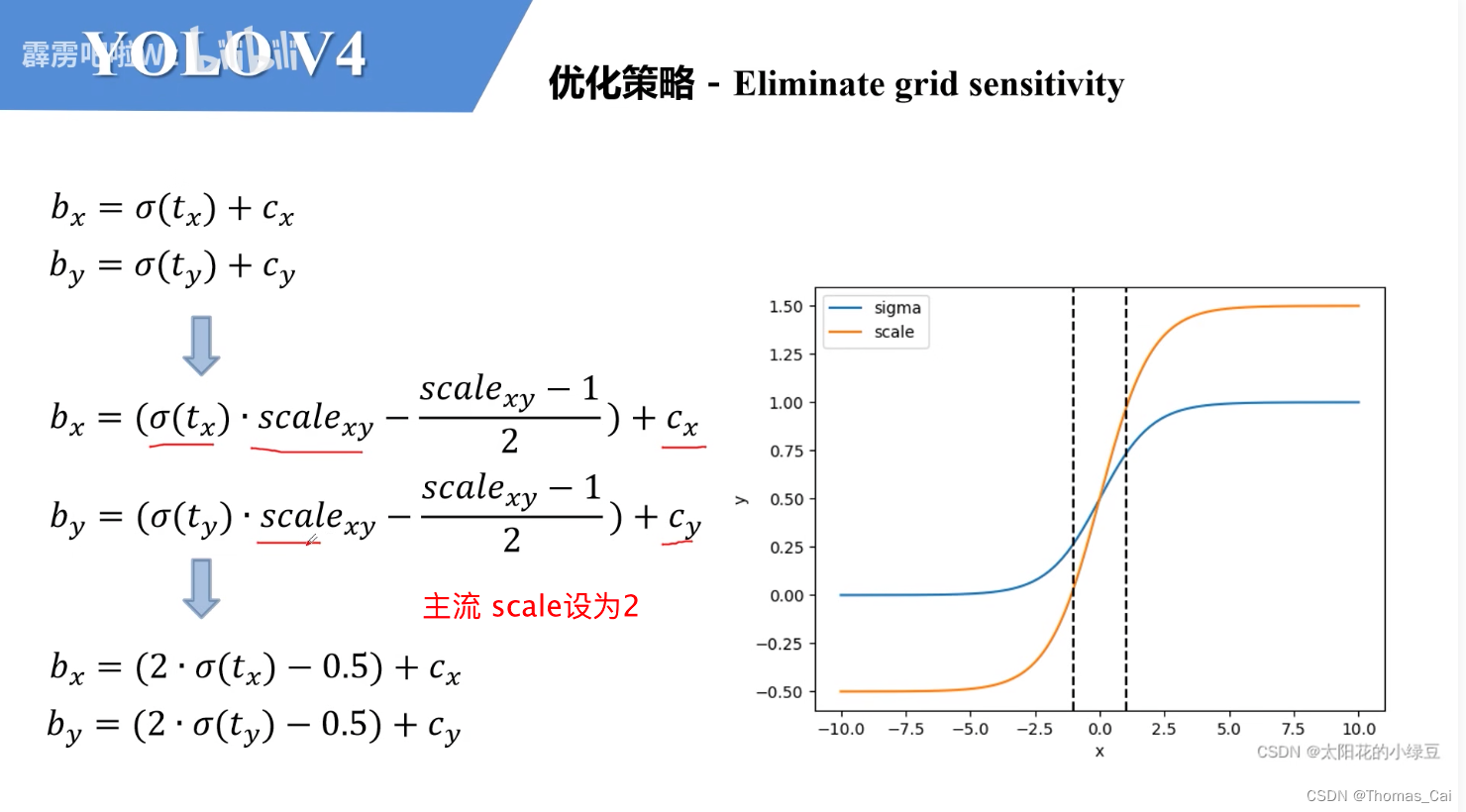
(3) 消除grid网格敏感——预测目标中心点可以取到网格边界/增加正样本的数量 Eliminate grid sensitivity
-
回顾yolov3
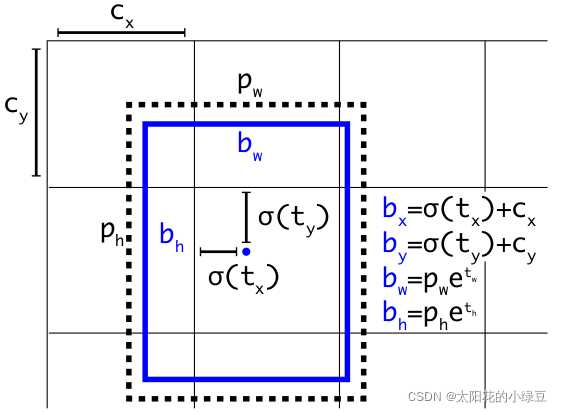
预测目标边界框的时候,通过1X1卷积层滑动grid cell会针对每个anchor预测回归框参数以及每个类别的score分数,回归参数则为tx,ty,tw,tht_x,t_y,t_w,t_htx,ty,tw,th,公式如下:虚线为anchor,蓝色为gt框。
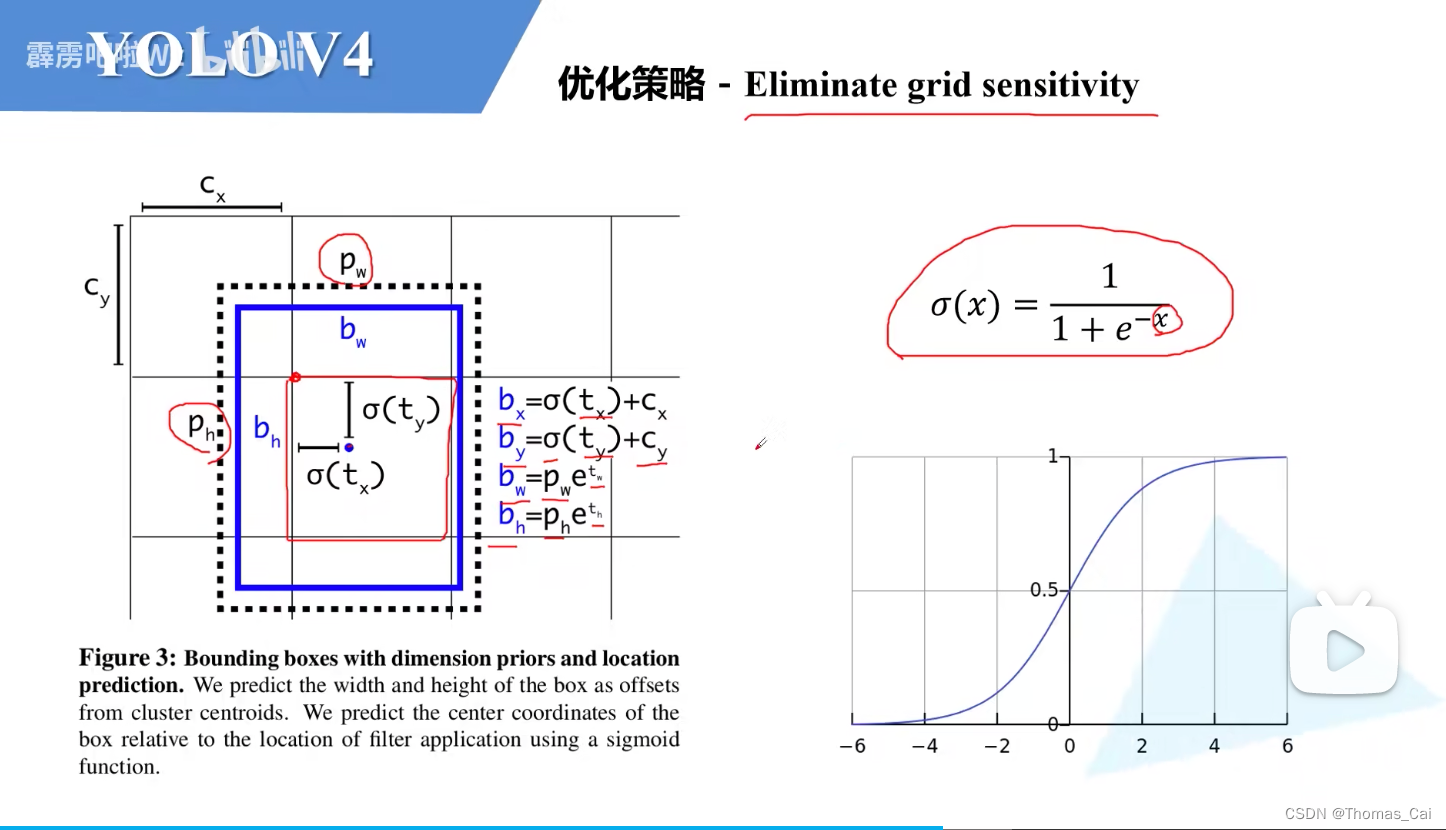
问题在于sigmoid激活函数在0和1范围内取值,因此如果真实目标的中心点刚好落在grid cell边界上,是无法预测正确的。 -
yolov4的改进:修改激活函数
二、yolox较yolov4的优化点
网络结构基于yolov5 v5.0构建的
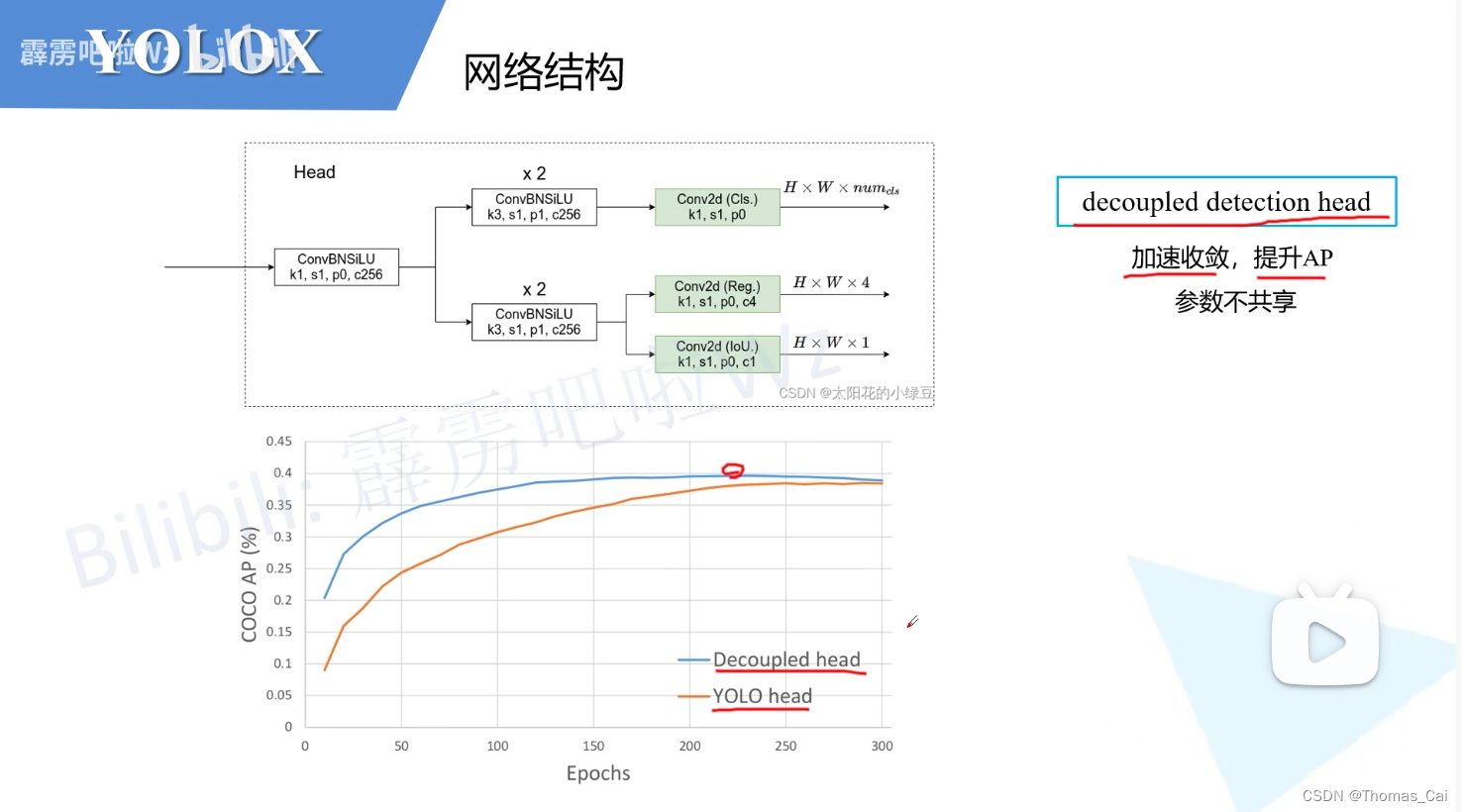
2.1 网络更新–解耦检测头
加速收敛,提升AP,参数不共享;类别一个检测头,位置和objectness共用一个检测头;
需要注意的是,实验效果是跟yolov3进行比较,看结果是能更快的收敛,但网络是从yolov5借鉴的,所以效果就emmm值得商榷,结果如下:
2.2 Anchor-Free机制以及优缺点
-
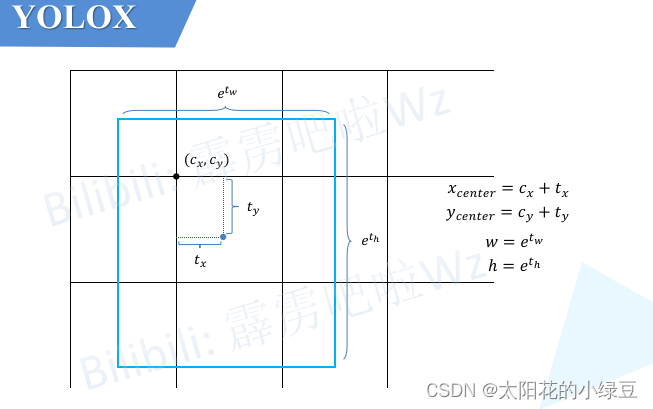
anchor-free机制
在每个grid cell来预测四个参数tx,ty,tw,tht_x, t_y, t_w, t_htx,ty,tw,th,这里是相对特征层的,还原到原图需要乘以步距。可以看到跟anchor没关,是个anchor-free的网络。
-
优点:
- 使用类似分割的思想来解决目标检测问题;
- 不需要调优与anchor相关的超参数;
- 避免大量计算GT boxes和anchor boxes 之间的IoU,使得训练过程占用内存更低。
- 缺点:
https://m.fx361.com/news/2022/0413/10766620.html
1.正负样本极端不平衡;
2.语义模糊性(因为主要靠关键点检测,如果两个目标中心点距离太近,更甚重叠,就会造成语义模糊);
现在这两者大多是采用Focus Loss和FPN来缓解的,但并没有真正解决。
2.2.1 (附录) Anchor-based机制的优缺点
-
优点:
(1)使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归;
(2)密集的anchor box可有效提高网络目标召回能力,对于小目标检测来说提升非常明显。 -
缺点:
(1)anchor机制中,需要设定的超参:尺度(scale)和长宽比( aspect ratio)是比较难设计的。这需要较强的先验知识。
(2)冗余框非常之多,会造成正负样本严重不平衡问题,也是one-stage算法难以赶超two-stage算法的原因之一。
(3)网络实质上是看不见anchor box的,在anchor box的基础上进行边界回归更像是一种在范围比较小时候的强行记忆。
(4)基于anchor box进行目标类别分类时,IOU阈值超参设置也是一个问题。
————————————————
版权声明:本文为CSDN博主「ytusdc」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ytusdc/article/details/107864527
2.3 更先进的正负样本匹配策略(simOTA)
三、focal loss
3.1 背景
针对one-stage的模型,目的是解决正负样本不均衡的问题。(负样本会有1w-10w,权重小,数量多也会过多关注)
3.2 做法
降低易分样本的loss贡献,让网络专注于学习难分的样本,达到平衡样本的目的,因为负样本数量巨多,就会有很多的易分样本。
3.3 更细节
参考:
yolo系列:
https://blog.csdn.net/ThomasCai001/article/details/123593690?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22123593690%22%2C%22source%22%3A%22ThomasCai001%22%7D
yolov3:https://blog.csdn.net/leviopku/article/details/82660381