Redis高可用高性能缓存的应用系列1 - 数据类型以及底层结构和原理

概述
介绍redis缓存原理与设计执行流程,单线程的处理方式是高效的原因,以及redis数据类型以及底层结构和原理进行说明,这对我们使用Redis有很大帮助。
底层运行实现模型
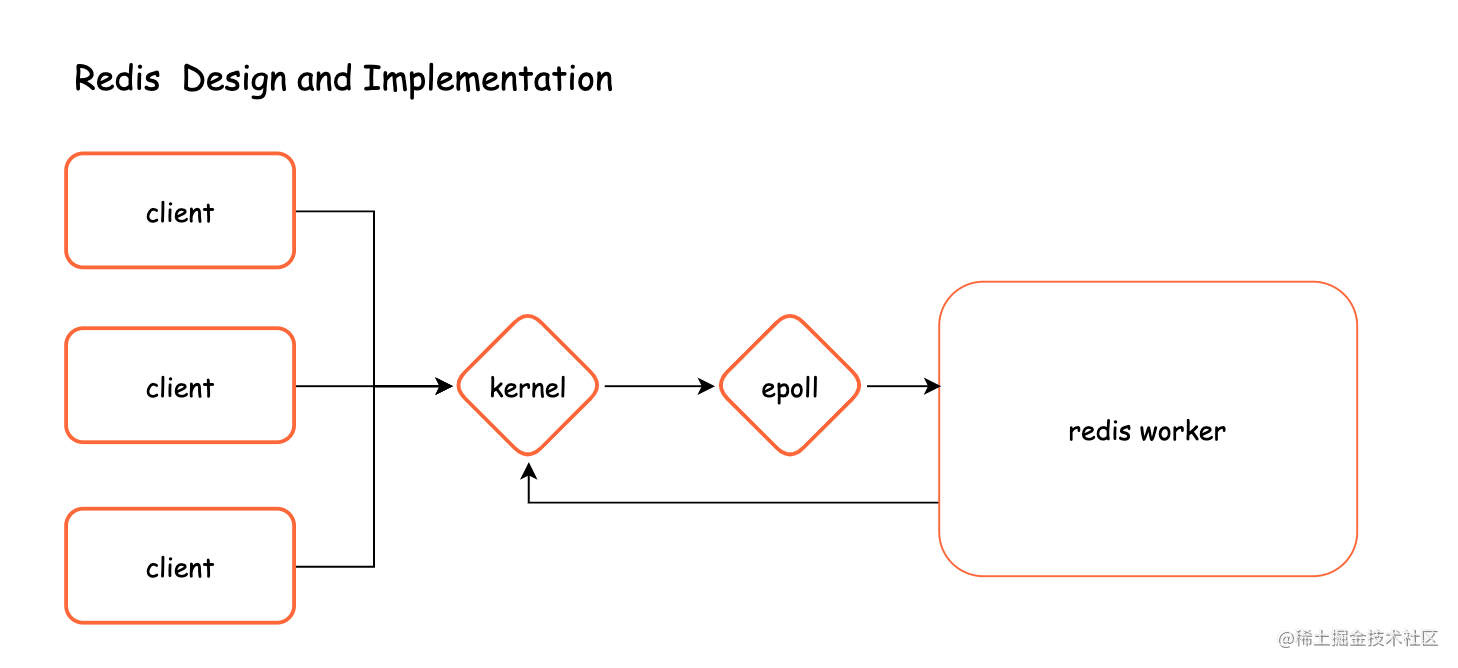
客户端的请求先进行linux运行内核,而redis和内核之间用了epoll非阻塞I/O多路复用的方式来处理,请求是I/O操作会有序的存入在epoll的待处理队列中,Redis的是内存操作,内存运行的速度要远远高于I/O操作的,Redis是单线程的处理方式是高效的,Redis会顺序的一笔一笔的处理在epoll的待处理队列中的请求。
所谓Redis单线程是用于计算的worker线程,redis还会有其他的线程,比如持久化,异步删除等等。
Redis基本结构
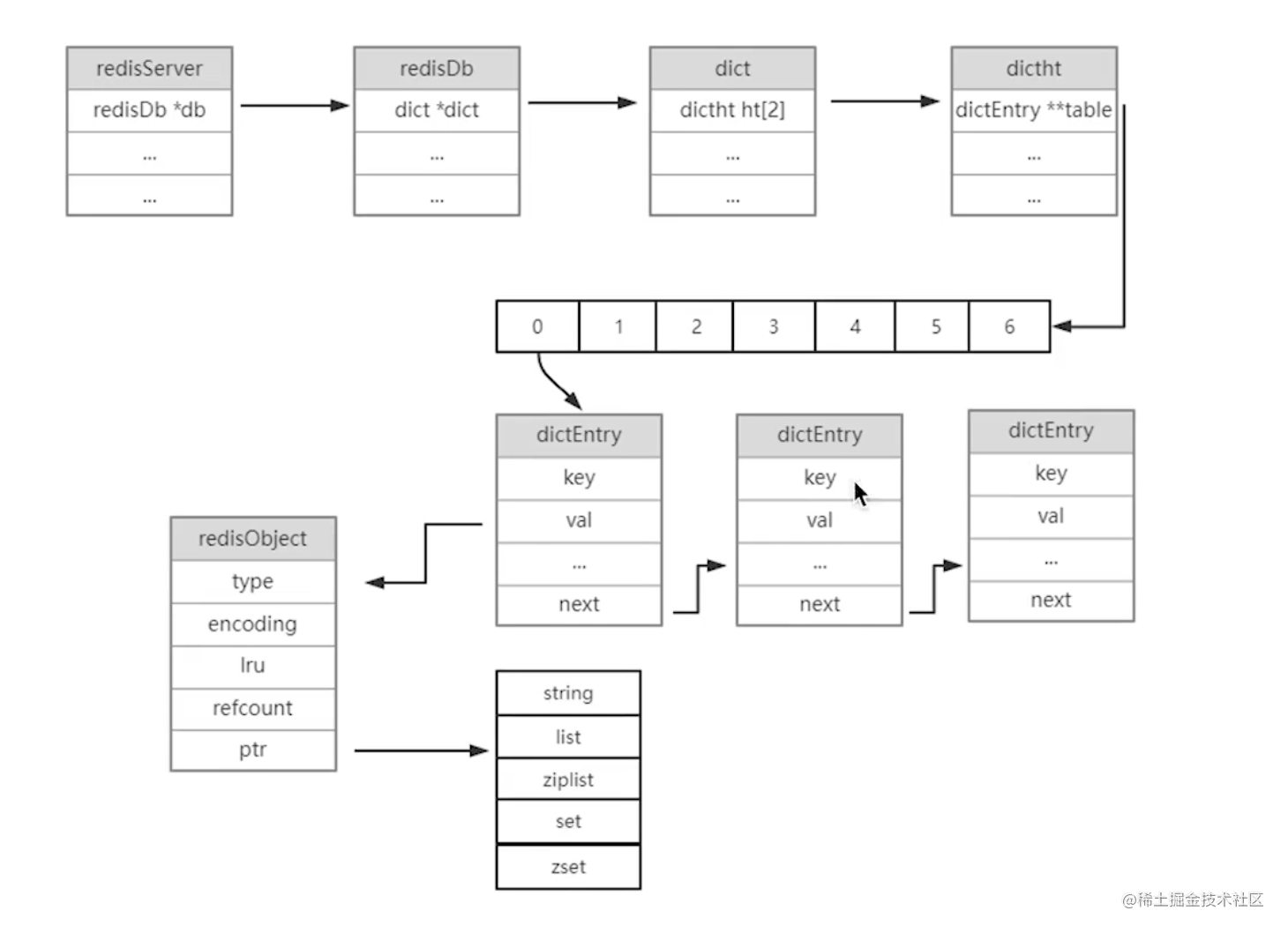
Redis核心结构只要有redisServer和redisObject组成,在Redis初始化的时候,先初始化RedisServer结构,通过dict映射dictEntry,把具体的类型和值存入redisObject进行统一管理,如果有不理解的地方,可以看redis设计与实现一书。
redisServer
1.下面是redisServer的结构体初始化,在文件server.h中。
struct redisServer {/* General */pid_t pid; /* Main process pid. */pthread_t main_thread_id; /* Main thread id */char *configfile; /* Absolute config file path, or NULL *///...redisDb *db;dict *commands; /* Command table */dict *orig_commands; /* Command table before command renaming. */aeEventLoop *el;// ...
}
redisDb *db :保存了数据库的信息,初始化默认16个数据库,通过参数``可以修改, dict是redisDb中最核心的结构体,dict中保存了所有的键值对,称为键空间。
对dict的理解很重要,Redis的对象相当于大的dict结构体对象,所有的类型结构实现的都是以dict做前提的。
typedef struct redisDb {dict *dict; dict *expires; dict *blocking_keys; dict *blocking_keys_unblock_on_nokey; dict *ready_keys; dict *watched_keys; // ...
} redisDb;
下面在看dict结构,它做了2个字典做渐进式Hash,数据组保存的是具体的dictEntry。
struct dict {dictType *type;dictEntry ht_table[2];unsigned long ht_used[2];long rehashidx; int16_t pauserehash; signed char ht_size_exp[2];void *metadata[];
};struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next; void *metadata[];
};
dictEntry *next ,当Hash的值一样时就形成一个链表,指向下一个dictEntry,再dictEntry结构体中,key保存实际的key值,val指向的是redisObject结构。
redisObject
下面详细介绍一下redisObject类型和结构体中主要的功能:
- type: 对外的数据类型,string、hash、list、set 、zset,通过type命令看到的类型。
- encoding:内部实际保存的数据类型,具体选择时通过配置文件对应参数实现的,例如list 按照存入的值分为ziplist和quicklist。
- lru:管理缓存淘汰机制
- refcount:引用计数,主要用于内存回收使用
- ptr:存储真实数据的物理指针地址
struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS; int refcount;void *ptr;
};
Redis数据结构
String
Redis的底层实现没有实现C语言的字符串,而是自己简单封装了一层动态字符串Sds,Sds内部又可以转为int、embstr、raw。
127.0.0.1:6379> set number 100
OK
127.0.0.1:6379> object encoding number
"int"127.0.0.1:6379> set name stark张宇
OK
127.0.0.1:6379> object encoding name
"embstr"127.0.0.1:6379> set logstr “stark张宇关于Redisraw类型编码的演示,他需要超过44字节”
OK
127.0.0.1:6379> object encoding logstr
"raw"
Sds内部的装换取决于存储值的字节大小,值为int的直接存储成int,小于等于44字节的存储成embstr类型,大于44字节的存储成raw类型。
embstr与raw存储上的区别:embstr存储在一块连续上的内存,读取一次就可以,raw存储的是不连续的内存,需要读取2次内存。
Redis为什么这么设计Sds结构体存储字符串?
1.效率:变量中经常会用到字符串长度len,如果使用C语言的字符长度时,需要对整个字符串进行遍历,它的时间复杂度O(n),在Sds中的len,时间复杂度O(1),在高并发场景下,频繁遍历字符串,会造成性能瓶颈。
2.防止数据溢出:C语言的字符串因为没有 记录自身长度,另外Sds再保存二进制是安全的,方便value值修改时修改存储空间。
3.内存空间的预分配:当修改字符串内存空间时,不仅会修改字符串存储空间,还会额外预留空间,下次修改的时候就会先检查未使用的内存空间。
4.惰性空间释放:当当修改字符串内存空间变小时,不会立即回收内存空间,防止再次修改。
分配内存空间规则:当值小于1M时,就会分配相同的空间,当大于1M时就会分配1M的空间。
Hash
Redis的Hash的底层是一个dict,当数据量比较小或者数据值比较小时会采用ziplist,数据大的时候采用hashtable的结构来存储数据。
127.0.0.1:6379> hgetall user1
1) "name"
2) "stark"
3) "age"
4) "33"
5) "sex"
6) "1"
127.0.0.1:6379> object encoding user1
"ziplist"127.0.0.1:6379> hset user1 mark "stark张宇关于HashTable类型编码的演示,值很大他就变成了HashTable"
(integer) 1
127.0.0.1:6379> object encoding user1
"hashtable"
ziplist
ziplist结构的组成部分详解:
- zlbytes: 32位无符号整型,表示整个ziplist所占的空间大小,包含了zlbytes所占的4个字节。这个字段可以在重置整个ziplist大小时不需要遍历整个list来确定大小,空间换时间。
- zltail:32位无符号整型,表示整个list中最后一项所在的偏移量,方便再尾部做pop操作。
- zllen:16位,表示ziplist中所存储的entry数量。
- entry:不定长,可能有多个。
- zlend:8位,ziplist的末尾表示,其固定值是255。
entry由3部分组成,前一个entry的大小,当前编码类型和长度,真实的字符串和数字。
ziplist优缺点:
优点:因为是连续内存空间,所以利用率高,访问效率高。
缺点:更新效率低,当插入和删除一个元素时,会频繁的进行内存的扩展和缩小,数据的搬移效率低。
list
Redis的list的有序数据结构,底层分为ziplist和quicklist。
ziplist在Hash类型里已经说了,在这里不做多余的叙述了。
quicklist结构的优缺点:
优点:因为是双向链表,更新效率比较高,在插入和删除操作时非常方便,复杂度O(n),前后元素的复杂度是O(1)。
缺点:增加了内存的开销。
Set
Redis里面的Set是无序的,自动去重的数据类型,它的底层是一个dict,当数据用整型并且数据元素小于配置文件中set-max-intest-entries,否则用dict。
127.0.0.1:6379> sadd gather 100 200 300
(integer) 3
127.0.0.1:6379> object encoding gather
"intset"
127.0.0.1:6379> sadd gather stark
(integer) 1
127.0.0.1:6379> object encoding gather
"hashtable"
Zset
Redis的Zset是有序的,自动去重的数据类型,底层是由字典Dict和跳表Skiplist实现的,数据较少时使用Ziplist结构来存储。
Ziplist可以在配置文件中通过zset-max-ziplist-entries和zset-max-ziplist-value来配置。
常见问题:Redis的Zset为什么不使用红黑树和二叉树,而要选择跳表呢?
1)红黑树和二叉树的范围查找不是很好,有序集合很大的场景是进行范围查找的,范围查找在跳表上是非常方便的,因为它是一个链表,红黑树和二叉树的范围查找相对来说就复杂的多。2)跳表的实现要比红黑树简单很多了。