SER | 语音情绪识别中的TIM-NET_SER项目复现

大家好,今天复现的是目前语音情绪识别的SOTA论文,论文中文名称是 时间建模的重要性: 用于语音情感识别的新型时空情感建模方法 。论文中训练的数据集有英文德语等几个语音情绪识别中常见的语音情绪数据集,以对比精度权重等效果~各数据集的情绪数量不同,可参考以下代码
CASIA_CLASS_LABELS = ("angry", "fear", "happy", "neutral", "sad", "surprise")#CASIA
EMODB_CLASS_LABELS = ("angry", "boredom", "disgust", "fear", "happy", "neutral", "sad")#EMODB
SAVEE_CLASS_LABELS = ("angry","disgust", "fear", "happy", "neutral", "sad", "surprise")#SAVEE
RAVDE_CLASS_LABELS = ("angry", "calm", "disgust", "fear", "happy", "neutral","sad","surprise")#rav
IEMOCAP_CLASS_LABELS = ("angry", "happy", "neutral", "sad")#iemocap
EMOVO_CLASS_LABELS = ("angry", "disgust", "fear", "happy","neutral","sad","surprise")#emovo论文地址 | [2211.08233] Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition (arxiv.org)
项目地址 | Jiaxin-Ye/TIM-Net_SER: [ICASSP 2023] Official Tensorflow implementation of "Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition". (github.com)
一般语音训练对计算机的内存有要求,一般情况下建议内存超过12G(要不然很容易出现out of memery).
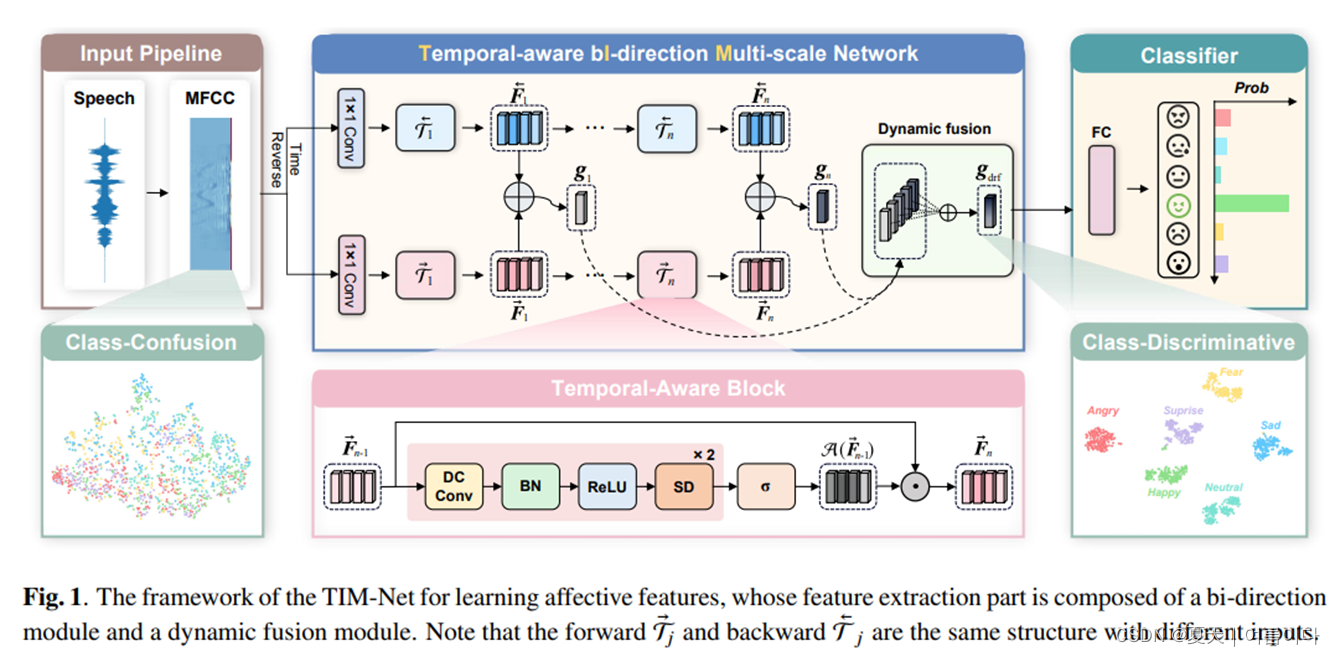
论文构架
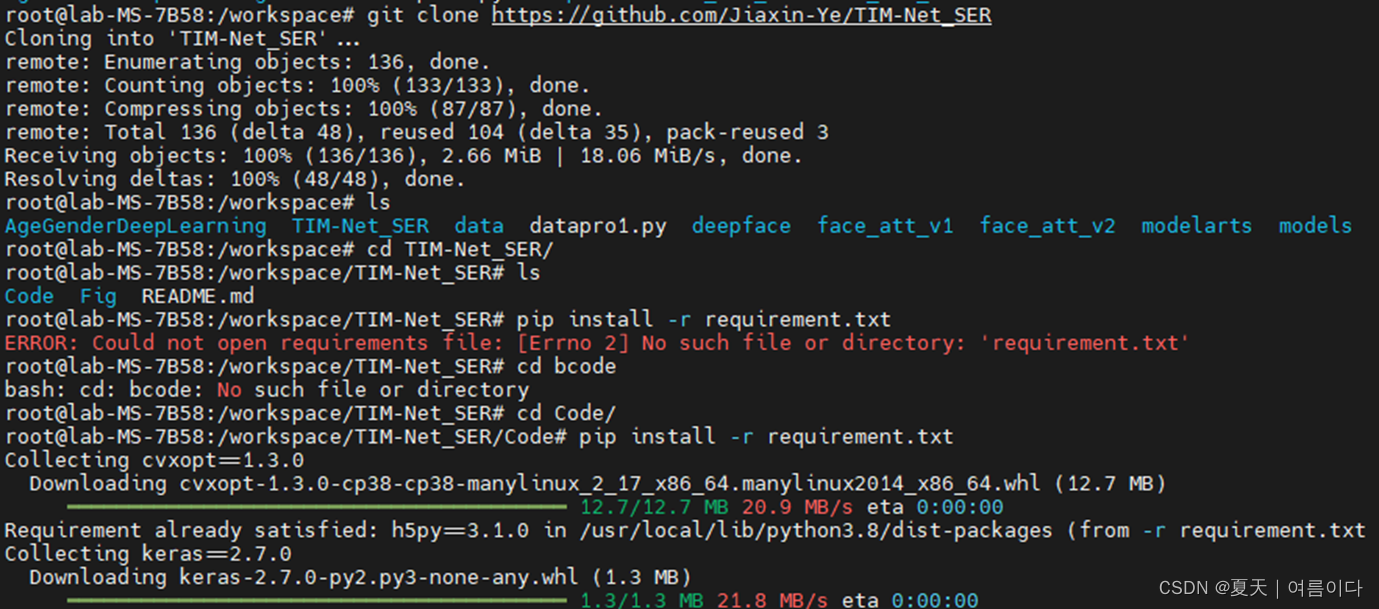
环境设置
Ubuntu(docker 容器),Tensorflow-gpu2.7等
# 克隆项目
git clone https://github.com/Jiaxin-Ye/TIM-Net_SER#打开文件夹
cd TIM-Net_SER#安装所需环境
pip install -r requirement.txt输入命令后如图所示
先下载测试所需要的作者已经提取的数据集 MFCC特征文件和测试模型的权重文件(提供百度和谷歌下载地址),没必要全部下载,例如我下载的就是 IEMOCAP数据集的相关文件。
MFCC特征文件(MFCC features files (*.npy)):
百度网盘下载地址: 百度网盘 请输入提取码 code: MFCC
谷歌云盘下载地址: https://drive.google.com/drive/folders/1nl7hej--Nds2m3MrMDHT63fNL-yRRe3d
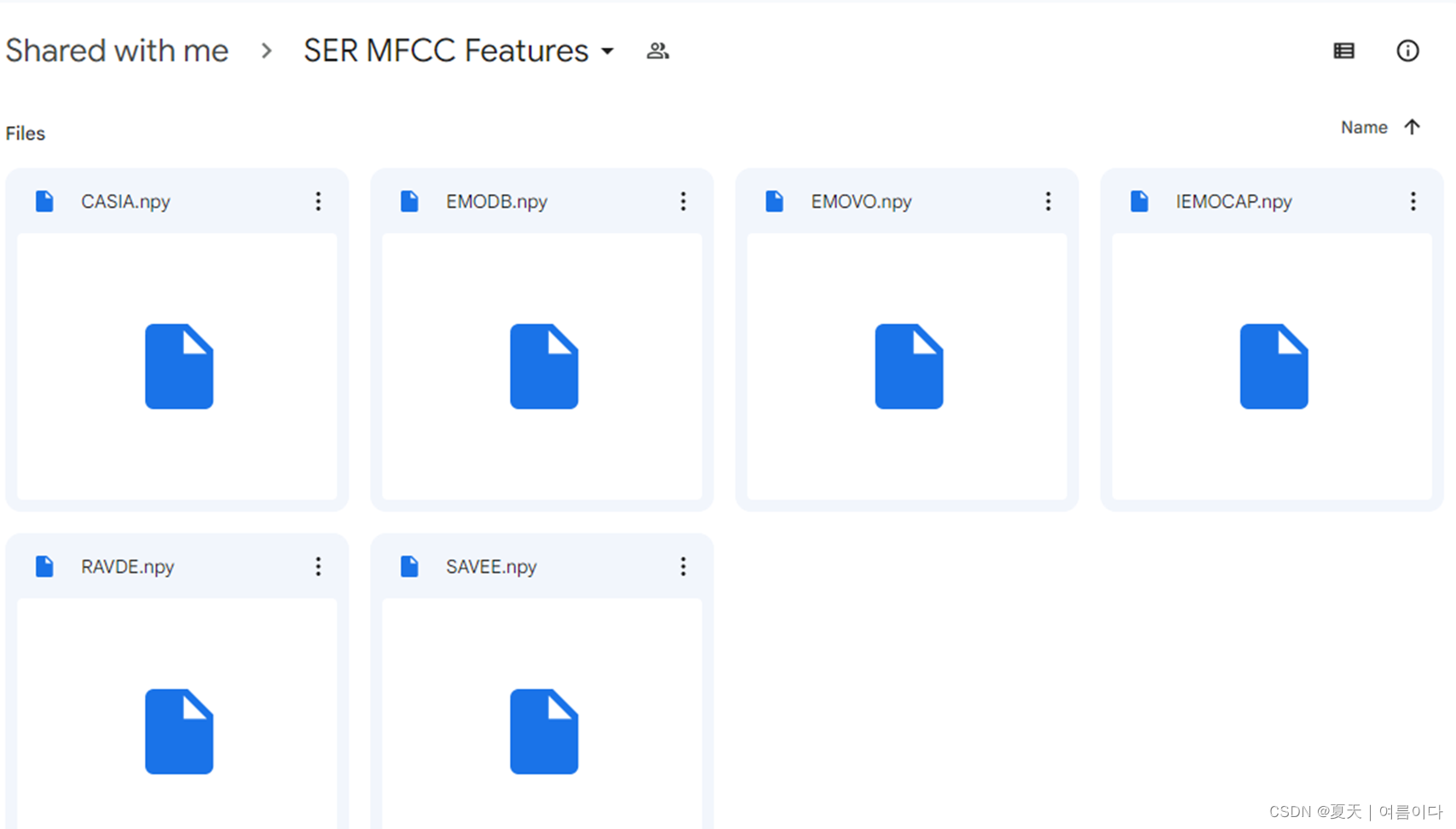
下载文件到这个路径下 TIM-Net_SER/Code/MFCC/
测试模型权重文件( testing model weight files (*.hdf5)):
Baidu links: 百度网盘 请输入提取码 code: HDF5
Google links: https://drive.google.com/drive/folders/1ZjgcT6R0A0C2twXatgpimFh1a3IL81pw
下载文件到这个路径下 TIM-Net_SER/Code/Test_Models/
(我的情况是远程服务器的docker容器中运行的,所以是先右键下载到本地笔记本,再利用MobaXterm上传到服务器,再输入docker复制命令,需要可参考扩展1.)
测试
如果前面俩个文件都下载的话就可以直接测试啦。测试命令
python main.py --mode test --data IEMOCAP --test_path ./Test_Models/IEMOCAP_16 --split_fold 10 --random_seed 10(如果出现out of memory请参考Q&A1.)
测试结果
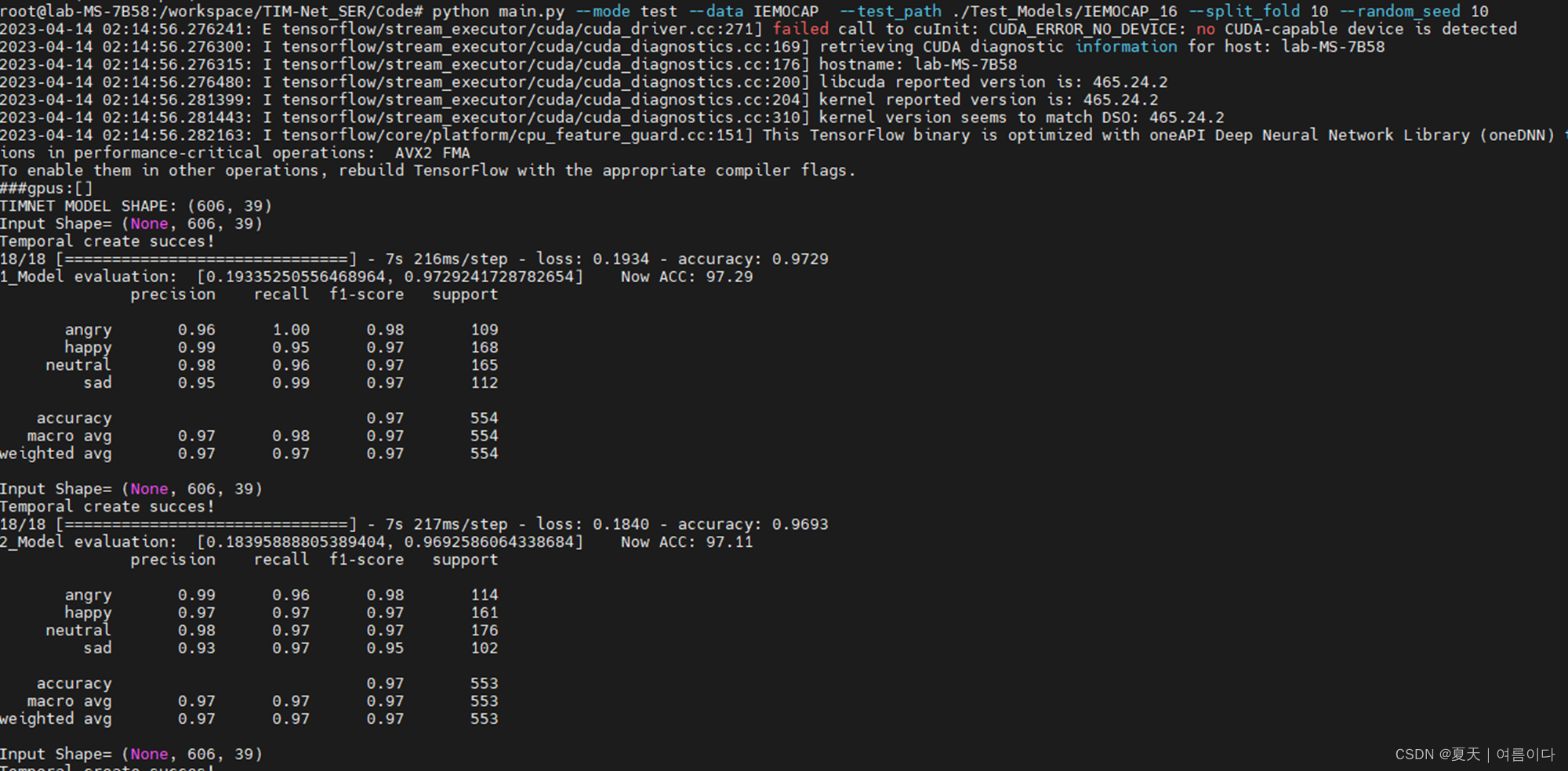
(中间省略)
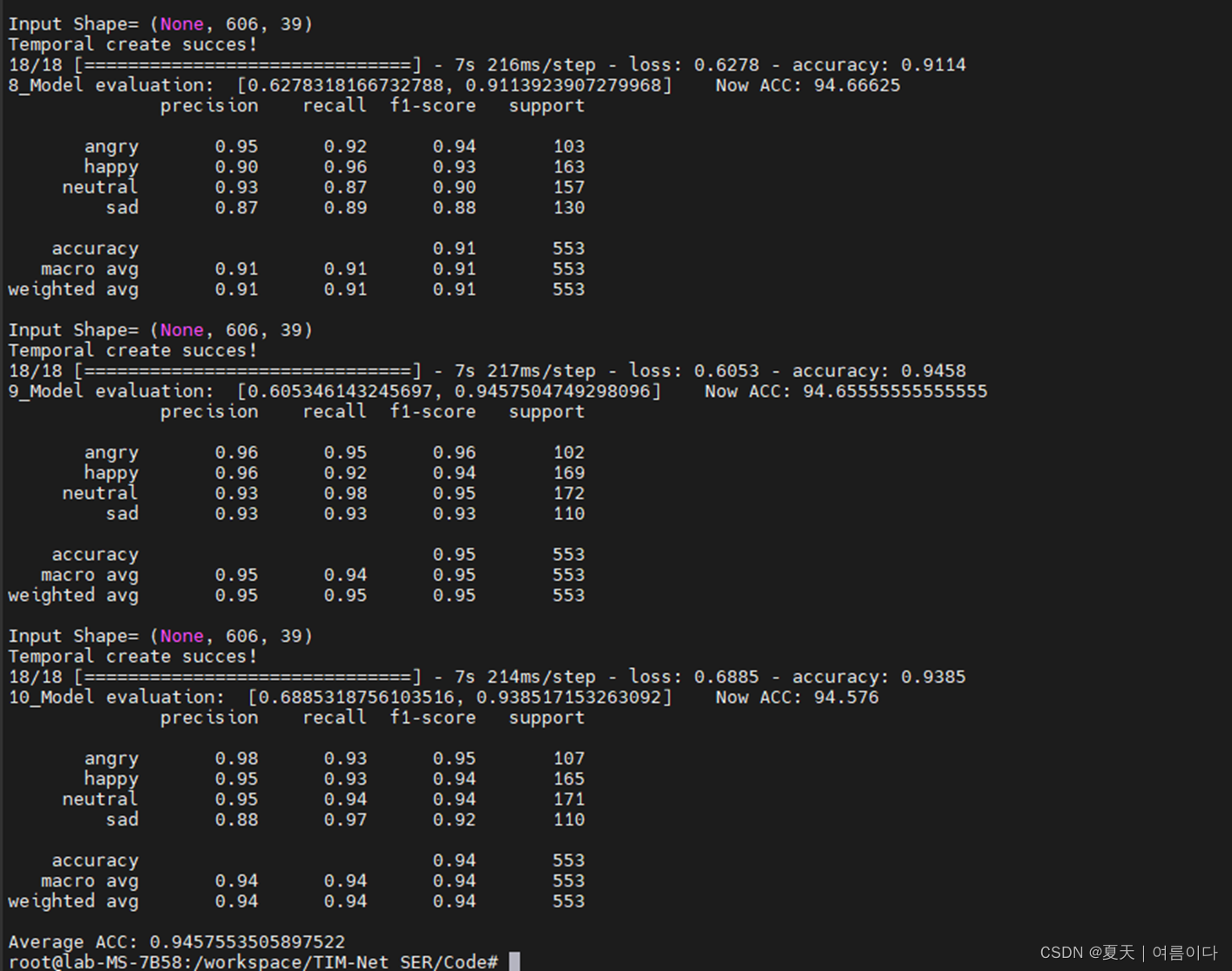
是截止到目前,我看到的所有论文中,语音情绪中精度最高的~
Q&A
1.测试时出现 out of memory的情况下
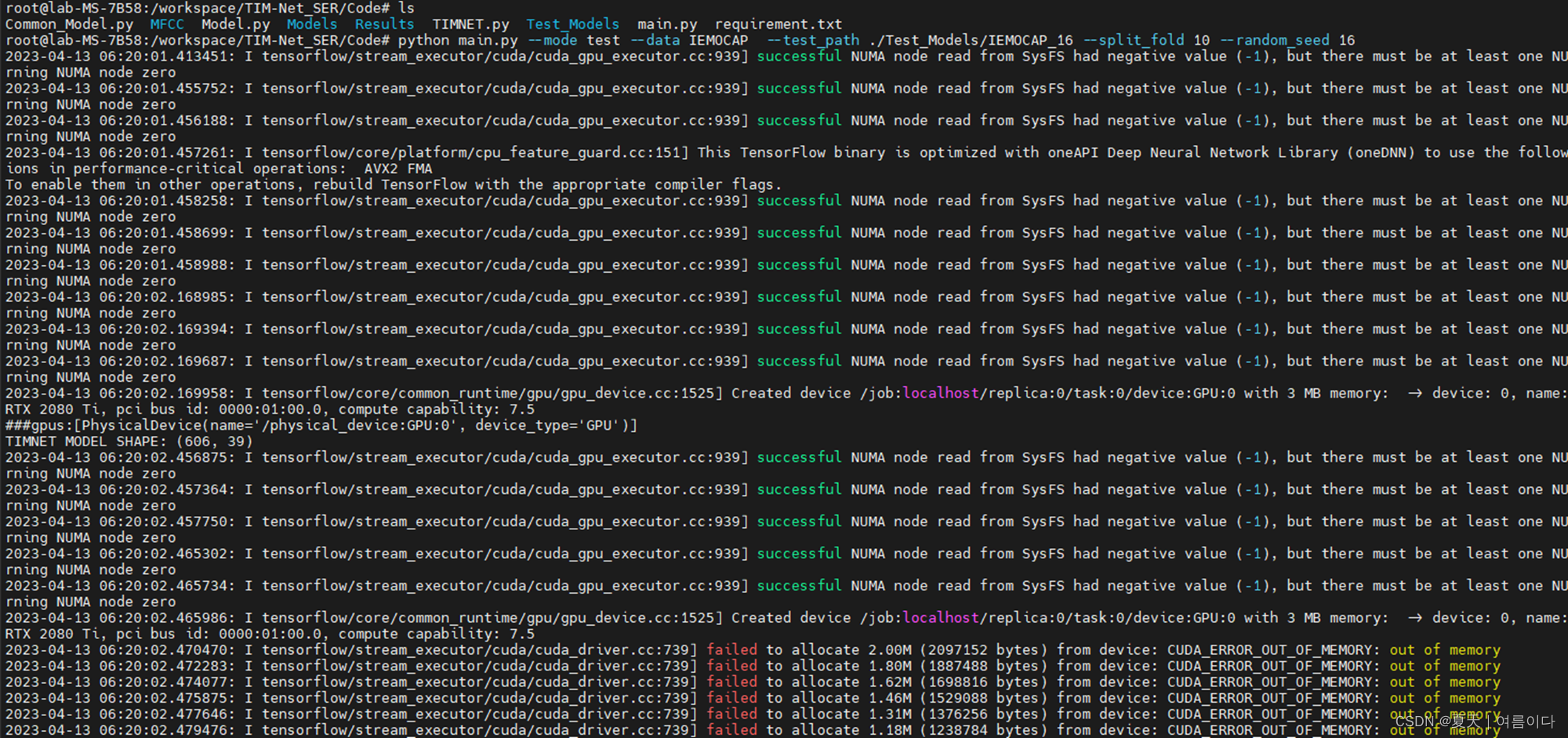
可以改小main.py中的 --batch_size,或者把-- gpu的值改为空。修改后如下
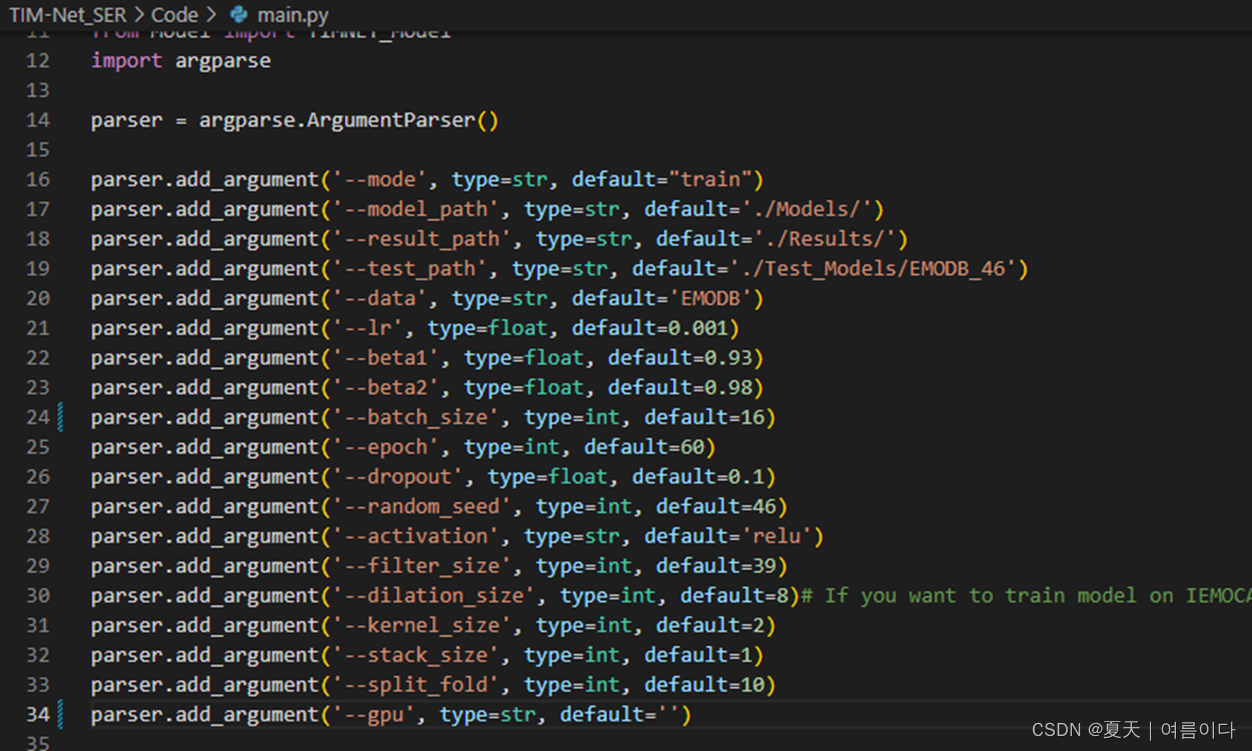
改完就就可以正常测试啦!以后有机会的话,可以训练自己的数据集,然后在此基础上进行优化~
扩展1
docker cp "/home/elena/IEMOCAP.npy" tf:/workspace/TIM-Net_SER/Code/MFCC/docker cp "/home/elena/IEMOCAP_16.zip" tf:/workspace/TIM-Net_SER/Code/Test_Models/