2023什么电脑配置适合机器学习和人工智能

机器学习和人工智能应用有多种类型——从传统的回归模型、非神经网络分类器和以 Python SciKitLearn 和 R 语言的功能为代表的统计模型,到使用 PyTorch 和 TensorFlow 等框架的深度学习模型. 在这些不同类型的 ML/AI 模型中,也可能存在显着差异。“最佳”硬件将遵循一些标准模式,但您的特定应用程序可能有独特的最佳要求。
我们的建议将基于典型工作流程的一般性。请注意,这主要针对用于编程模型“训练”而不是“推理”的 ML/DL 工作站硬件。
处理器(中央处理器)
在 ML/AI 领域,GPU 加速在大多数情况下主导性能。但是,处理器和主板定义了支持该平台的平台。还有一个现实是,必须花费大量精力进行数据分析和清理以准备在 GPU 中进行训练,而这通常是在 CPU 上完成的。当板载内存 (VRAM) 可用性等 GPU 限制需要时,CPU 也可以作为主要计算引擎。
什么 CPU 最适合机器学习和人工智能?
推荐的两个 CPU 平台是 Intel Xeon W 和 AMD Threadripper Pro。这是因为它们都提供了出色的可靠性,可以为多个视频卡 (GPU) 提供所需的 PCI-Express 通道,并在 CPU 空间中提供出色的内存性能。我们通常建议使用单路 CPU 工作站来减少跨多 CPU 互连的内存映射问题,这可能会导致将内存映射到 GPU 的问题。
更多的 CPU 内核会使机器学习和 AI 更快吗?
选择的内核数量将取决于非 GPU 任务的预期负载。根据经验,建议每个 GPU 加速器至少有 4 个内核。但是,如果您的工作负载具有重要的 CPU 计算组件,那么 32 甚至 64 个内核可能是理想的选择。在任何情况下,16 核处理器通常被认为是此类工作站的最低要求。
机器学习和 AI 与 Intel 或 AMD CPU 配合使用效果更好吗?
这个领域的品牌选择主要是偏好问题,至少如果您的工作负载以 GPU 加速为主。但是,如果您的工作流程可以从英特尔 oneAPI AI 分析工具包中的某些工具中获益,则英特尔平台会更可取 。
为什么推荐 Xeon 或 Threadripper Pro 而不是更“消费者”级别的 CPU?
对 ML 和 AI 工作负载提出此建议的最重要原因是这些 CPU 支持的 PCI-Express 通道数量,这将决定可以使用多少 GPU。Intel Xeon W-3300 和 AMD Threadripper Pro 3000 系列都支持足够的 PCIe 通道用于三个或四个 GPU(取决于主板布局、机箱空间和功耗)。此类处理器还支持 8 个内存通道,这会对 CPU 密集型工作负载的性能产生重大影响。另一个考虑因素是这些处理器是“企业级”的,并且整个平台在持续的重计算负载下可能很健壮。
显卡 (GPU)
自 2010 年代中期以来,GPU 加速一直是推动机器学习和人工智能研究快速发展的驱动力。2019 年底,Don Kinghorn 博士 撰写了一篇博文 ,讨论了 NVIDIA 在该领域产生的巨大影响。对于深度学习训练,图形处理器提供了比 CPU 更显着的性能提升。
哪种类型的 GPU(显卡)最适合机器学习和人工智能?
NVIDIA 在 GPU 计算加速方面占据主导地位,毫无疑问是标准。他们的 GPU 将是最受支持和最容易使用的。还有其他加速器,例如一些高端 AMD GPU、来自不同制造商的 FPGA,以及其他具有潜力的新兴 ML 加速处理器——但它们目前的可用性和可用性将排除我们推荐它们的可能性。
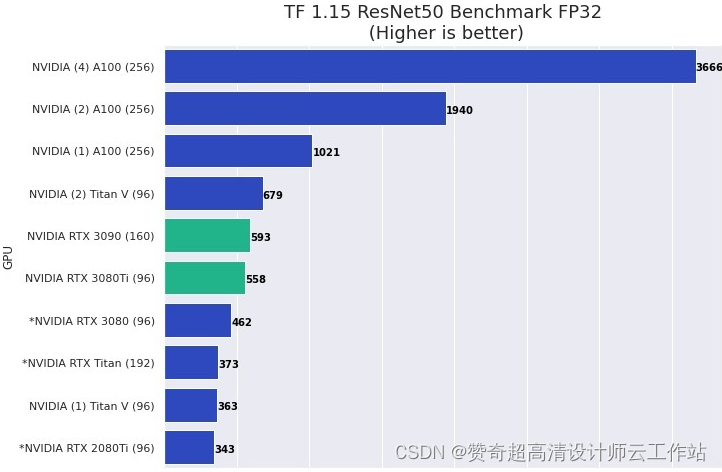
机器学习和 AI 推荐使用哪些显卡?
几乎所有 NVIDIA 显卡都可以工作,更新和更高端的型号通常提供更好的性能。幸运的是,大多数具有 GPU 加速的 ML / AI 应用程序在单精度 (FP32) 下运行良好。在许多情况下,使用具有混合精度的 Tensor 核心 (FP16) 可为深度学习模型训练提供足够的准确性,并提供比“标准”FP32 显着的性能提升。大多数最新的 NVIDIA GPU 都具有此功能,但低端卡除外。
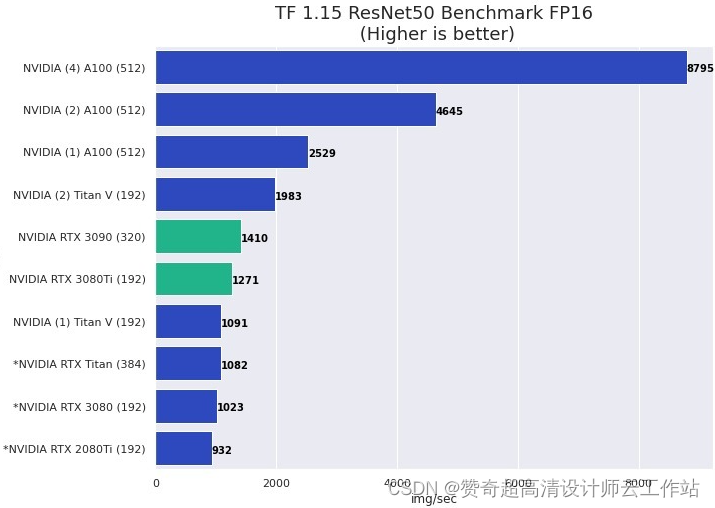
NVIDIA 的 GeForce RTX 4080 和 4090 等消费类显卡可提供非常出色的性能,但由于其散热设计和物理尺寸,可能难以在具有两个以上 GPU 的系统中进行配置。RTX A5000 和 A6000 等“专业”NVIDIA GPU 质量高,往往具有更多板载内存,并且在多 GPU 配置中运行良好。特别是 RTX A6000,其 48GB VRAM,推荐用于处理具有“大特征尺寸”的数据,例如更高分辨率的图像、3D 图像等。
机器学习和 AI 需要多少 VRAM(显存)?
这取决于模型训练的“特征空间”。GPU 上的内存容量有限,ML 模型和框架受到可用 VRAM 的限制。这就是为什么在训练之前进行“数据和特征缩减”是很常见的原因。例如,训练数据的图像通常分辨率较低,因为像素数量成为限制性关键特征维度。然而,尽管存在这些限制,该领域还是取得了巨大的成功!每个 GPU 8GB 的内存被认为是最小的,并且肯定是许多应用程序的限制。12 到 24GB 相当普遍,并且在高端视频卡上很容易获得。对于更大的数据问题,NVIDIA RTX A6000 上可用的 48GB 可能是必需的——但通常不需要。
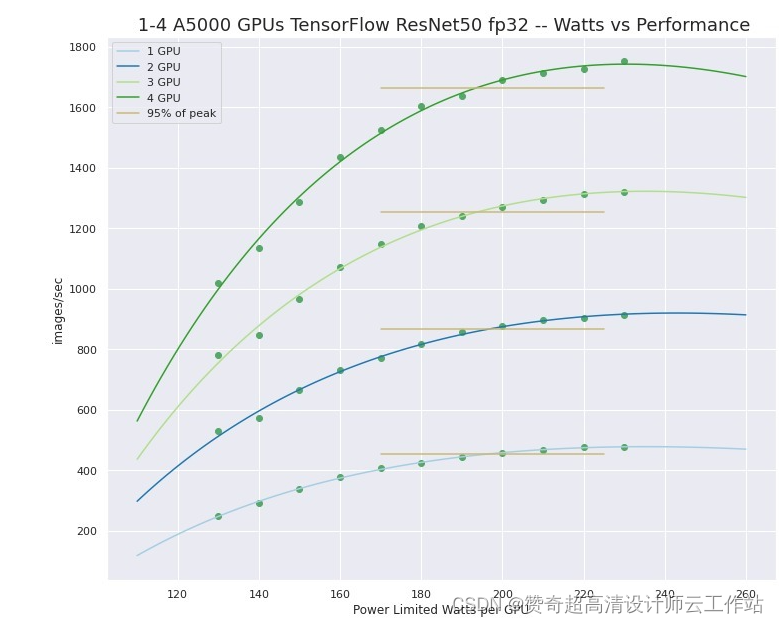
多个GPU会提高机器学习和人工智能的性能吗?
一般是的。在我们推荐的配置中,我们默认使用多个显卡,但此提供的好处可能会受到您正在进行的开发工作的限制。所使用的框架或程序必须支持多 GPU 加速。幸运的是,多 GPU 支持现在在 ML 和 AI 应用程序中很常见——但如果您在没有现代框架的情况下进行开发工作,那么您可能不得不自己实施它。
另请记住,像 NVIDIA RTX 3090 或 A5000 这样的单个 GPU 可以提供显着的性能,并且可能足以满足您的应用程序。在工作站中拥有 2 个、3 个甚至 4 个 GPU 可以提供惊人的计算能力,甚至可能足以解决许多大型问题。还建议在进行开发工作时至少有两个 GPU,以启用多 GPU 功能和缩放的本地测试——即使“生产”作业将被卸载到单独的 GPU 计算集群。
机器学习和 AI 在 NVIDIA 或 AMD 上运行得更好吗?
为了使 AMD GPU 可用于该领域,正在做一些工作,英特尔很快就会进入该领域,但实际上 NVIDIA 占据主导地位,并且在计算 GPU 背后进行了十多年的成功、密集的研究和开发工作。
机器学习和人工智能需要“专业”显卡吗?
不会。NVIDIA GeForce RTX 3080、3080 Ti 和 3090 是适合此类工作负载的出色 GPU。但是,由于散热和尺寸限制,“pro”系列 RTX A5000 和高内存 A6000 最适合具有三个或四个 GPU 的配置。从历史上看,现代 ML/AI 是在 NVIDIA 游戏 GPU 上开发的,它们在开发工作站中仍然很常见。对于要求最严苛的工作负载,出色的 NVIDIA 计算 GPU A100 可用于机架式配置。它们非常昂贵,但性能惊人。
使用多个 GPU 进行机器学习和 AI 时是否需要 NVLink?
NVIDIA 的 NVLink 在一对 GPU 之间提供直接的高性能通信桥梁。这是否有益取决于问题类型。对于训练多种类型的模型,不需要它。但是,对于任何具有“历史”组件的模型,例如 RNN、LSTM、时间序列,尤其是 Transformer 模型,NVLink 可以提供显着的加速,因此推荐使用。请注意,并非所有 NVIDIA GPU 都支持 NVLink,而且它只能桥接两张卡。
内存(随机存取存储器)
ML/AI 系统 CPU 端的内存容量和性能当然取决于正在运行的作业,但可能是一个非常重要的考虑因素,并且有一些最低限度的建议。
机器学习和人工智能需要多少 RAM?
第一条经验法则是 CPU 内存量至少是系统中总 GPU 内存量的两倍。例如,具有 2 个 GeForce RTX 3090 GPU 的系统将具有 48GB 的总 VRAM – 因此系统应配置为 128GB(96GB 是两倍,但 128GB 通常是最接近的可配置数量)。
第二个考虑因素是需要多少数据分析。通常需要(或至少希望)能够将完整的数据集拉入内存以进行处理和统计工作。这可能意味着大内存需求,多达 1TB(或很少甚至更多)的系统内存。这是我们建议使用工作站和服务器级处理器的原因之一:它们比消费类芯片支持更多的系统内存。
存储(硬盘)
存储是“超出您的想象”可能是个好主意的领域之一。此处的最低要求类似于 CPU 内存要求。毕竟,您的数据和项目必须可用!
哪种存储配置最适合机器学习和人工智能?
建议尽可能使用快速 NVMe 存储,因为当数据太大而无法放入系统内存时,数据流速度可能成为瓶颈。从 NVMe 暂存作业运行可以减少作业运行速度减慢。NVMe 驱动器通常提供高达 4TB 的容量。
与用于暂存作业的快速 NVMe 存储一起,更传统的基于 SATA 的 SSD 提供更大的容量,可用于超过典型 NVMe 驱动器容量的数据。8TB 通常可用于 SATA SSD。
盘片驱动器可用于归档存储和非常大的数据集。现已提供 18TB+ 容量。
此外,上述所有驱动器类型都可以配置为 RAID 阵列。这确实增加了系统配置的复杂性,并且可能会用完主板上本来可以支持额外 GPU 的插槽——但可以允许 10 到 100 TB 的存储空间。
总结
机器学习和人工智能的硬件配置要求很高的,可能配置起来可以流畅进行运算和设计的电脑都需要上万元,而且还不能根据你后期的需求来弹性的安排硬件,最终花大价钱搞定的电脑不到2年就要再去更换,如果是企业遇到这种需要大批量采购电脑的情况,用完之后再有业务需求需要弹性扩容的情况,那之前的硬件投入的资金就要浪费掉了,为了避免浪费以及低成本高效率的办公,企业和个人都选择赞奇云工作站,随开随用,按需收费,高效一键上云,企业客户量多从优,优惠多多,帮助企业节省成本,一定要试试。
上赞奇云工作站不需要复杂的安装和部署,就能随时随地享受到行业领先配置的机器,高画质稳定输出作品,减少本地配置时间和成本投入,完全不同担心电脑卡顿、运行不动等问题。