DeepFM论文翻译

1.摘要
为了最大化推荐系统的CTR,学习用户行为的复杂交叉特征很关键。 尽管有很大进步,现有的方法无论对低阶还是高阶的交叉特征,似乎还是有很强的bias, 或者需要专门的特征工程。 本文,我们证明了得出一个能强化高阶和低阶交叉特征的端到端模型是可能的。 本文提出的DeepFM模型,结合了推荐系统的FM和深度神经网络中的特征学习能力,相比于Google的Wide&Deep模型,DeepFM共享wide和deep部分的输入,而且只需要原始特征,不需要特征工程。实验部分展示了DeepFM的效果和性能。
2.引言
在推荐系统中点击率(CTR)的预测至关重要,其任务是预估用户点击推荐物品的概率。在许多推荐系统中,目标是最大化点击次数,因此给用户返回的是通过预估CTR排序的物品;而在其他的推荐场景中(例如在线广告), 提高收入也很重要, 因此对候选集合的排序策略为:CTR∗bidCTR*bidCTR∗bid ,其中 bidbidbid 为物品被用户点击时系统获得的收益。无论哪种情形, 关键在于正确预估CTR。
学习用户行为背后的隐含交叉特征很重要。 在主流的app市场上,我们发现,用户喜欢在用餐时间下载送餐app, 说明 222 阶交叉特征“app类别-时间戳” 可以作为CTR预估的重要特征。 另一个发现, 男青年喜欢射击游戏和RPG游戏,因此,333 阶交叉特征“app类别-用户性别-用户年龄”也可以作为CTR预估的一个特征。 一般来说,用户行为背后的特征交叉可能很复杂, 低阶和高阶特征交互都应该发挥重要作用。 并且Google的Wide&Deep模型也说明, 低阶和高阶的交叉特征结合在一起,比单独使用低阶*或者高阶的交叉特征有额外的提升。
关键挑战在于有效地对特征交叉进行建模。 专家可以设计一些简单易于理解的特征交叉。然而,大多数其他特征交互都隐藏在数据中,难以先验识别(例如,经典的关联规则“尿布和啤酒”是从数据中挖掘出来的,而不是由专家发现的),只能通过机器学习自动捕获 。在数据量大的情况下,即使对于简单且易于理解的特征交叉,专家也不能详尽列出所有。
线性模型例如FTRL,虽然性能很好,但是无法学习这种交叉特征, 为了学习特征交叉通常的做法是 手动添加pair-wise的交叉特征。这种方法很难推广到对高阶特征交互或那些从未或很少出现在训练数据中的交互进行建模。 FM模型通过特征之间隐向量的内积进行特征交叉,虽然理论上 FM 可以对高阶特征交互进行建模,但实际上由于复杂度高,通常只考虑 222 阶特征交互。
深度神经网络具有学习复杂特征交互的潜力。基于 CNN 的模型偏向于相邻特征之间的交互,而基于 RNN 的模型更适合具有顺序依赖的点击数据。 FNN模型在应用DNN之前,预训练了FM,因此最终的交叉特征受限于FM的能力。 PNN在embedding layer和全连接层之间加入了product layer。 Cheng等人(在Wide&Deep文章中)后来提到,PNN和FNN以及其他一些deep模型,几乎捕捉不到低阶交叉特征,但是这些特征对CTR预估很重要。因此,他们提出了Wide&Deep模型,其中wide部分还是依赖特征工程来学习低阶交叉特征。
可以看出,现有模型偏向于低阶或高阶特征交互,或者依赖于特征工程。 本文提出了一种端到端的学习方法,可以学习所有阶的交叉特征,而且只需要原始特征。
-
DeepFM集成了 FM 和深度神经网络(DNN)的架构。 像FM一样学习低阶交叉特征,像DNN一
样学习高阶交叉特征。但不同于Wide & Deep模型,可以端到端的学习,而且不需要特征工程。
-
DeepFM可以高效的训练,因为wide部分和deep部分共享了输入和embedding向量。
3. 方法
假设训练数据包含 nnn 个样本 (χ,y)(χ,y)(χ,y) ,其中 χχχ 是 mmm 个特征的数据,通常包含用户和 itemitemitem 的pairpairpair。 y∈0,1y∈ {0, 1}y∈0,1 是对应的 label, χχχ 可以包含类别特征(例如:性别、地域)和连续特征(例如:年龄),类别特征用one-hot来表示, 连续特征用自身的值, 或者是离散化之后的one-hot编码。 这样,每个训练样本转化为 (x,y)(x, y)(x,y),其中 x=[xfield1,xfield2,...,xfieldj,...,xfieldm]x=[x_{field1},x_{field2},...,x_{fieldj},...,x_{fieldm}]x=[xfield1,xfield2,...,xfieldj,...,xfieldm] ,是一个 ddd 维向量,其中 xfieldjx_{fieldj}xfieldj 表示 χχχ 的第 jjj 个特征。通常,xxx 是高维并且极稀疏的。
任务:对于给定的上下文特征建模进行CTR预估。
3.1 DeepFM
为了学习低阶和高阶特征交互,提出了DeepFM模型(基于神经网络的FM模型)
DeepFM包含两个组件: FM组件和deep组件,他们共享相同的输入。
对于特征 iii , wiw_iwi 是它的一阶权重, latent向量 ViV_iVi 描述与其他特征的关系, ViV_iVi 会喂给FM模型来作为二阶交叉特征, 同时喂给DNN 模型来为高阶交叉特征。所有的参数,包括 wiw_iwi 、 ViV_iVi 以及下文的网络参数 W(l),b(l)W(l),b(l)W(l),b(l) 会在下面的预测模型中联合训练:
y^=sigmoid(yFM+yDNN)(1)\\hat y = sigmoid(y_{FM} + y_{DNN}) \\qquad (1) y^=sigmoid(yFM+yDNN)(1)
其中,y^∈(0,1)\\hat y∈(0,1)y^∈(0,1) 是预测的CTR, yFMy_{FM}yFM 是FM组件的输出, yDNNy_{DNN}yDNN 是deep组件的输出。
3.1.1 FM组件
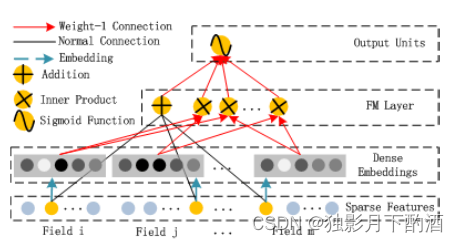
FM组件其实就是Rendle提出的FM模型,在数据稀疏的情况下, FM模型能更有效的对二阶交叉特征进行学习 FM模型通过latent向量 ViV_iVi 和 VjV_jVj 的inner product来描述 iii 和 jjj 的二阶交叉特征,这样的好处是,不需要特征 iii 和 jjj 同时出现在训练样本中。(注:类似协同过滤的思想)。 如图所示,FM组件的输出是Addition单元和若干个内积单元的和:
yFM=<w,x>+∑i=1d∑j=i+1d<Vi,Vj>xi⋅xj(2)y_{FM} = <w,x> + \\sum_{i=1}^d\\sum_{j=i+1}^d<V_i,V_j>x_i·x_j \\qquad (2) yFM=<w,x>+i=1∑dj=i+1∑d<Vi,Vj>xi⋅xj(2)
其中, w∈Rd,Vi∈Rkw∈R^d,V_i∈R^kw∈Rd,Vi∈Rk (kkk 已知,另外为了简洁,这里忽略了偏置项), ⟨w,x⟩⟨w,x⟩⟨w,x⟩ 就是一阶特征,内积就是二阶交叉特征。
3.1.2 Deep组件
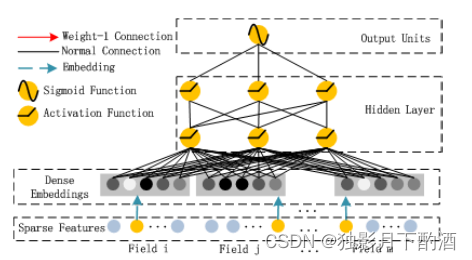
深层组件是一个前馈神经网络,用于学习高阶特征交互。如图所示,一条数据记录(一个向量)被输入到神经网络中。 不同于图像和语音数据,CTR预估的原始特征一般有极稀疏的、维度很高、类目特征和连续特征混在一起、可以分组等特点。因此,在接入DNN之前,要经过embedding层来转换成低维稠密的向量。
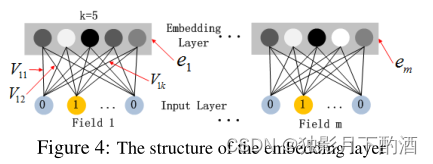
上图显示了从输入层到嵌入层的子网络结构。需要注意的有两点:
- 输入的特征数据有可能长度不一样,但是embedding之后的长度都是相同的(kkk)
- FM组件中的latent向量 VVV 在这里被用来计算embedding向量。
- 在FNN模型中,向量 VVV 是要通过FM模型预学习出来的,但是DeepFM模型中,不需要预训练,是要把FM组件和deep组件来联合训练的。
将embedding层的输出记为:
a(0)=[e1,e2,...,em](3)a^{(0)} = [e_1,e_2, ...,e_m] \\qquad (3) a(0)=[e1,e2,...,em](3)
其中, eie_iei 是第 iii 个特征的embedding向量, m 是特征的个数。然后 a(0)a^{(0)}a(0) 喂给DNN,前向过程为:
a(l+1)=σ(Wlal+bl)(4)a^{(l+1)}=\\sigma (W^{l}a^{l}+b^{l}) \\qquad (4) a(l+1)=σ(Wlal+bl)(4)
其中, lll 是DNN的深度, σσσ 是激活函数, a(l),W(l),b(l) 分别是第 lll 层的输出、模型权重、偏置项。 之后,便生成了一个低维稠密的向量,最终喂给一个sigmoid函数来计算CTR预估值:
yDNN=W∣H∣+1⋅a∣H∣+b∣H∣+1y_{DNN}=W^{|H|+1}·a^{|H|}+b^{|H|+1} yDNN=W∣H∣+1⋅a∣H∣+b∣H∣+1
其中 ∣H∣|H|∣H∣ 是隐藏层的个数。
值得注意的是,FM组件和deep组件共享特征embedding好处有两点:
1、它可以从原始特征中学到高阶、低阶的交叉特征。
2、不需要像wide&deep那样专门的特征工程。
3.2 与其他deep模型的关系
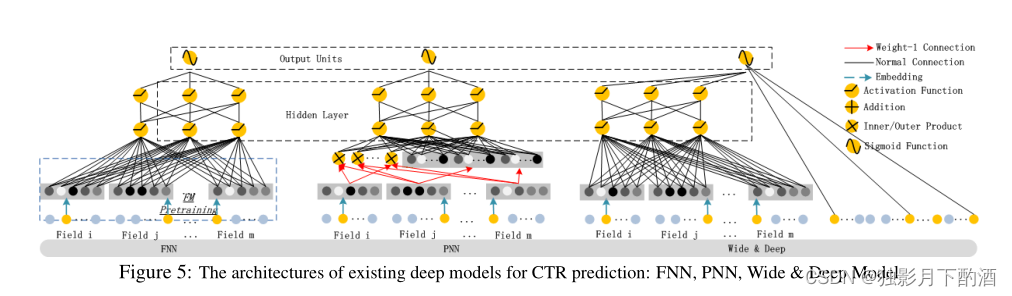
FNN: 如图5左所示, FNN需要预训练一个FM模型,有两个不足:1、embedding参数受FM影响严重。2、引入的预训练阶段,严重影响了效率。 另外,FNN只能学到高阶交叉特征,相反,DeepFM不仅不需要预训练,而且能同时学习高阶、低阶交叉特征。
PNN: 为了学习高阶交叉特征,PNN在embedding层和第一个隐藏层之间引入了product层,根据不同的product操作,又分为IPNN、OPNN和PNN*。IPNN基于inner product, OPNN基于outer product, PNN*基于两者。跟FNN一样,PNN也忽略了低阶交叉特征。
为了提高计算效率,作者提出了内积和外积的近似计算:1)通过消除一些神经元来近似计算内积;2)通过将 mmm 个 kkk 维特征向量压缩为一个k维向量来近似计算外积。然而,我们发现外积不如内积可靠,因为外积的近似计算丢失了很多信息,导致结果不稳定。内积虽然更可靠,但仍然存在计算复杂度高的问题,因为乘积层的输出与第一个隐藏层是全连接。与 PNN 不同的是,DeepFM 中乘积层的输出只连接到最终输出层(一个神经元)。与 FNN 一样,所有 PNN 都忽略低阶特征交互。
Wide&Deep: Wide & Deep由 Google 提出,用于同时对低阶和高阶特征交互进行建模。wide部分需要人工特征工程。DeepFM只需要原始特征。 如果把wide部分的LR换成FM,就跟DeepFM非常像了,但是DeepFM的FM组件和deep组件是共享embedding特征的,这样就能更精准的对高阶和低阶交叉特征建模。
总结: 总而言之,DeepFM 与其他深度模型在四个方面的关系如表 所示。可以看出,DeepFM 是唯一不需要预训练和特征工程的模型,同时捕获了低阶和高阶特征交互。
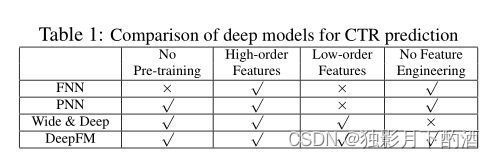
4.实验
在本节中,我们根据经验比较了我们提出的 DeepFM 和其他最先进的模型。 评估结果表明,我们提出的 DeepFM 比任何其他最先进的模型更有效,并且 DeepFM 的效率可与其他最佳模型相媲美。
4.1 实验设计
数据集
我们在以下两个数据集上评估 DeepFM 的有效性和效率。
Criteo Dataset 包含 450045004500 万用户的点击记录,131313 个连续特征,262626 个类目特征。将数据集分为两组:90%90\\%90% 训练,10%10\\%10%测试。
Company Dataset 从公司的game center收集了连续7天的用户点击数据做训练,之后一天的数据做测试。总共约有 101010 亿条数据。其中包括app特征(ID、类目等)、用户特征(用户下载app等)、上下文特征(操作时间等)
Evaluation Metrics:
- AUC、LoglossAUC、LoglossAUC、Logloss
Model Comparison
- 总共对比了9个模型:LR、FM、FNN、PNN(三个变种)、Wide&Deep(两个变种)、DeepFM。
其中Wide&Deep的两个变种就是把wide部分的LR换成FM。这里我们分别叫做 LR & DNN 和 FM & DNN
Parameter Settings
在Criteo数据集上,我们参照了FNN和PNN的参数设置:
- Dropout: 0.50.50.5
- 网络结构: 400−400−400400-400-400400−400−400
- 优化器: Adam
- 激活函数: IPNN用tanh、其他模型用relu
- 为了公平期间,DeepFM也用这些参数。LR和FM的优化器分别为FTRL和Adam。FM的latent维度为 101010。
4.2 性能对比
效率对比
公式如下
∣trainingtimeofdeepCTRmodel∣∣trainingtimeofLR∣\\frac{|training\\ time\\ of\\ deep\\ CTR\\ model|}{|training\\ time\\ of \\ LR |} ∣training time of LR∣∣training time of deep CTR model∣
包括CPU和GPU的评测:
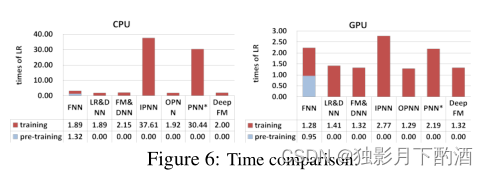
- FNN的pre-traing影响了效率。
- 虽然IPNN和PNN*在GPU上的加速明显,但是低效的inner product操作还是影响效率
- DeepFM在两组实验中,效率基本都是最优的。
效果对比
结果如下:
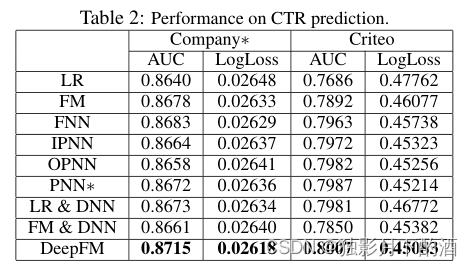
各个模型在两个数据集上的效果如表2所示:
-
学习交叉特征对CTR有提升。通过LR(不考虑交叉特征)比其他模型差可以看出。作为最好的模型,DeepFm在AUC上比LR提升0.82%0.82\\%0.82%和 2.6%2.6\\%2.6%(Logloss提升 1.1%1.1\\%1.1% 和 4.0%4.0\\%4.0%)。
-
高阶和低阶交叉特征结合学习,可以提升CTR。DeepFM模型优于只考虑低阶交叉特征的FM和只考虑高阶交叉特征的FNN、IPNN、OPNN、PNN*相比可以看出。DeepFM模型与次优模型相比,在 Company∗ 和 Criteo 数据集上的AUC提升 0.34%0.34\\%0.34% 和 0.41%0.41\\%0.41%(Logloss提升 0.34%0.34\\%0.34% 和 $0.76%4)
-
通过共享embedding共同训练高阶、低阶交叉特征可以提升CTR。与两个Wide&Deep模型变种相比。AUC提升 0.48%0.48\\%0.48% 和 0.44%0.44\\%0.44%(Logloss提升 0.58%0.58\\%0.58% 和 $0.80%4)
总体而言,我们提出的 DeepFM 模型在 Company∗ 数据集上的 AUC 和 Logloss 方面分别超过了 0.37%0.37\\%0.37% 和 0.42%0.42\\%0.42%。 事实上,线下 AUC 评估的微小改进很可能导致在线 CTR 的显着增加。正如 [Cheng et al., 2016] 中报道的,与 LR 相比,Wide & Deep 将 AUC 提高了 0.275%0.275\\%0.275%(离线),在线 CTR 提高了 3.9%3.9\\%3.9%。 Company∗ 的 App Store 的日营业额为数百万美元,因此即使点击率提升个百分点,每年也会带来数百万美元的额外收入。
4.3 超参数学习
我们研究了不同深度模型的不同超参数对 Company* 数据集的影响。 顺序是:
- 激活函数;
- dropout比例;
- 每层的神经元数量;
- 隐藏层数;
- 网络形状。
激活函数
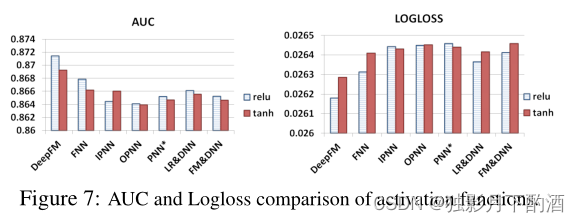
PNN论文里提出,relu和tanh比sigmoid函数更适合Deep模型。图7是relu和tanh的效果对比。除了IPNN,relu比tanh的效果更好。可能的原因是relu引入了稀疏性。
dropout
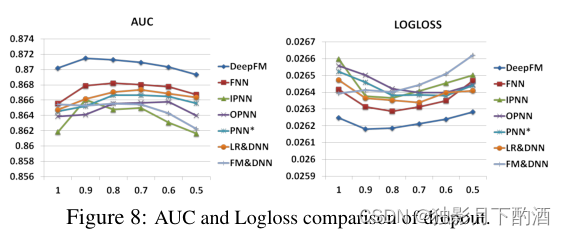
Dropout指的是神经元在网络中保留的概率,是一种正则化的技巧。保证了网络的性能和准确性。我们尝试了把Dropout设为:1.0、0.9、0.8、0.7、0.6、0.51.0、0.9、0.8、0.7、0.6、0.51.0、0.9、0.8、0.7、0.6、0.5。如图8所示,通过设置合适的Dropout,每个模型都能达到它的最优效果。实验结果表明,通过添加适当的随机性,可以增强模型的鲁棒性。
每层神经元个数
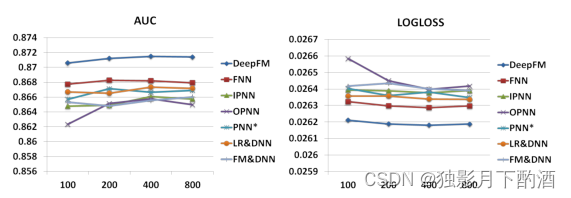
当其他因素保持不变时,增加每层神经元的数量会引入复杂性。从图 9 可以看出,增加神经元的数量并不总能带来好处。 例如,当每层神经元数量从 400400400 增加到 800800800 时,DeepFM 性能稳定; 更糟糕的是,当我们将神经元的数量从 400400400 个增加到 800800800 个时,OPNN 的表现更差。这是因为过于复杂的模型很容易过拟合。 在我们的数据集中,每层 200200200 或 400400400 个神经元是一个不错的选择。
隐藏层数
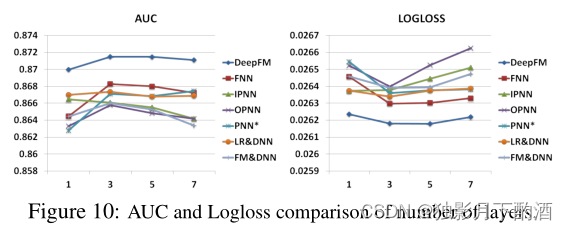
如图 10 所示,增加隐藏层的数量在开始时会提高模型的性能,但是,如果隐藏层的数量不断增加,它们的性能会下降。 这种现象也是因为过拟合。
网络结构
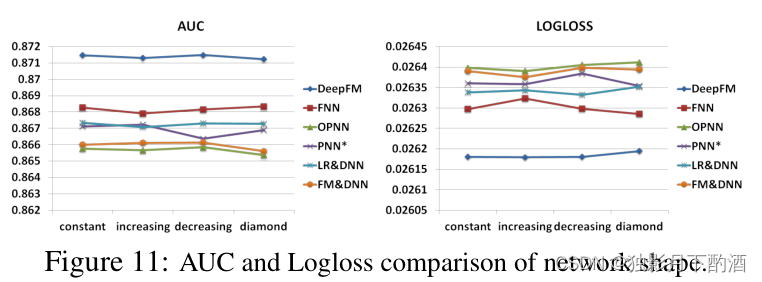
我们测试了4种不同形状的网络结构: 定长、递增、递减、菱形结构。在改变网络形状的时候,我们保持隐藏层数和神经元个数不变。例如,设隐藏层数为 333、神经元总数为 600600600。那么,444 种网络结构分别为: 定长(200−200−200200-200-200200−200−200)、递增(100−200−300100-200-300100−200−300)、递减(300−200−100300-200-100300−200−100)、菱形(150−300−150150-300-150150−300−150)。从图11看出,定长的形状效果明显优于其他形状,这个结论跟之前 Larochelle09年的论文里的结论是一致的。
5.相关工作
在本文中,提出了一种新的深度神经网络用于 CTR 预测。 最相关的领域是推荐系统中的 CTR 预测和深度学习。 在本节中,我们将讨论这两个领域的相关工作。
CTR 预测在推荐系统中起着重要作用 。除了广义线性模型和 FM,还提出了一些其他模型用于 CTR 预测,例如基于树的模型、基于张量的模型、支持向量机 和贝叶斯模型。深度学习在推荐系统方面的工作,在第 1 节和第 2.2 节中,已经提到了几种用于 CTR 预测的深度学习模型,因此我们在此不再讨论。在 CTR 预测之外的推荐任务中提出了几种深度学习模型(例如,[Covington et al., 2016; Salakhutdinov et al., 2007; van den Oord et al., 2013; Wu et al.,2016; Zheng et al. ., 2016; Wu et al., 2017; Zheng et al., 2017])。[Salakhutdinov 等人,2007 年; Sedhain 等人,2015 年;Wang 等人,2015 年] 提出通过深度学习改进协同过滤。[Wang and Wang, 2014;van den Oord et al., 2013] 的作者通过深度学习提取内容特征以提高音乐推荐的性能。[Chen et al., 2016] 设计了一个深度学习网络来考虑图像特征和显示广告的基本特征。[Covington et al., 2016] 开发了一个用于 YouTube 视频推荐的两阶段深度学习框架。
6.结论
在本文中,我们提出了 DeepFM,一种基于神经网络的FM模型进行 CTR 预测,以克服最先进模型的缺点并实现更好的性能。 DeepFM 联合训练一个Deep组件和一个 FM 组件。它从以下优点中获得了性能改进:
- 不需要任何预训练;
- 它同时学习高阶和低阶特征交互;
- 它引入了特征嵌入的共享策略,以避免特征工程。我们对两个真实的数据集(Criteo 数据集和商业 App Store 数据集)进行了广泛的实验,以比较 DeepFM 和最先进模型的有效性和效率。我们的实验结果表明:1)DeepFM 在两个数据集上的 AUC 和 Logloss 均优于最先进的模型;2)DeepFM 的效率可与最先进的最有效的深度模型相媲美。
未来的研究有两个有趣的方向。一是探索一些策略(例如引入池化层)来加强学习最有用的高阶特征交互的能力。另一种是在 GPU 集群上针对大规模问题训练 DeepFM。