python pandas数据处理excel、csv列转行、行转列(具体示例)

一、数据处理需求
对Excel或CSV格式的数据,我们经常都是使用pandas库读取后转为DataFrame进行处理。有的时候我们需要对其中的数据进行行列转换,但是不是简单的行列转换,因为数据中有重复的数据属性。比如我们的数据在Excel中的格式如下:
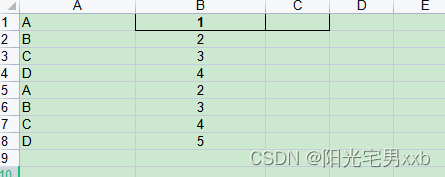
那么,我们如何将上面的数据格式转为将A列的数据作为行,B列的数据转为行数据格式呢。也就要到达以下效果:

二、实现思路
要处理的数据中同一个名称的数据有多个,比如A的值有两个,B的值也有两个等,但是最后列转为行之后,A只能出现一次,其两个值作为两行数据,那么:
1、需要使用groupby对第一列数据进行分组,使得A、B、C、D不重复出现,且每个属性的值都聚集到一起,放在一个数组中
2、然后将行列进行翻转,使得A、B、C、D作为列列索引
3、然后将A、B、C、D分别对应的数据数组拆分出来,通过一些方法分解为多行,从而到达目标
三、代码实现
1、读取文件中的数据,并重命名列的名称,因为文件中没有列名
import pandas as pd df = pd.read_excel('text.xls',header=None,index_col=None,dtype=str)#重命名列名
df.columns =["name","value"]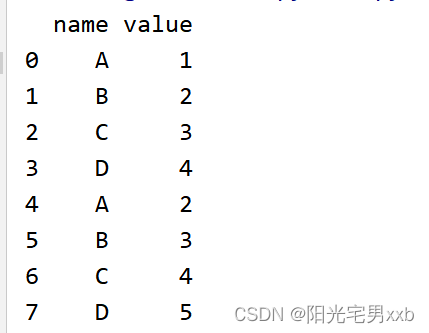
2、对于数据进行分组,使得同一个属性对应的值形成一对多的关系
df = df.groupby(["name"]).agg(list).reset_index()
3、 对数组形式的列表拆分为字符便于后面继续拆分
df['value']= df['value'].apply(lambda x:','.join(x))
4、 将行列翻转
#将行列翻转
df = df.T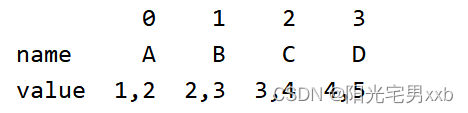
5、将A、B、C、D作为列索引
#设置第一行为列索引
df.columns = df.iloc[0]
#第一行已作为索引列,删除这一行
df.drop(['name'],inplace=True)
6、将value列的多个值扩展为多个列
df=df.loc['value'].str.split(',',expand=True)
7、将列索引0 1转变成行索引:这里也就是把一行的两列转为两行两列了,从而由一行变多行
df=df.stack()
8、将name列由列变为行
df=df.unstack(0)其中0表示第一层,也可以修改为“name”表示name列

9、目标达成,最后写回文件中
df.to_excel('test.xls',index=False)
四、pandas行列转换
上面的示例中,其实就是用到了pandas中行列转换的知识。
1、df.T对数据进行转置相信大家都用到过,可以实现简单的行列翻转
2、stack可以将数据的列“旋转”为行
3、unstack相当于stack的逆方法,将数据的行“旋转”为列
stack和unstack方法要注意的是可以设置一个level参数,用于指定翻转的层级是哪一个,不同的值翻转效果不一样。具体可以参考这位博主的介绍:
【Python】pandas轴旋转stack和unstack用法详解_dataframe stack_Asher117的博客-CSDN博客