pytorch

目录
- anaconda3 安装
-
- 将先前的python版本 加入到 后来的anaconda
- 使用 jupyter
- Dataset 获取数据集
- Tensorboard
- Transforms
-
- 归一化 Normalize:
- Resize
- Compose
- RandomCrop 随机裁剪
- Torchvision 中的数据集使用
- Dataloader
- 神经网络
anaconda3 安装
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
下载过后,配置环境变量,如下所示。
python 和 anaconda 都是python环境,将之前配置的python环境变量删掉,替换为下面。

配置过后在cmd控制台检验版本
conda --version
提示未找到的话就重启下主机。
将先前的python版本 加入到 后来的anaconda
安装过 anaconda 后,输入指令
conda env list # 查看 conda 中的python 环境
当要采用某一conda 环境时
activate base # 激活环境
deactivate # 关闭环境
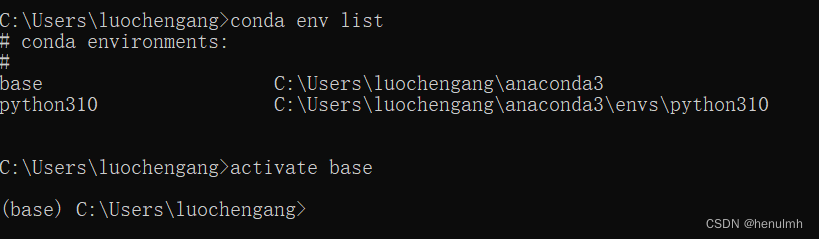
anaconda 默认只有一个 base 环境,添加新环境:
conda create --name python310 python=3.10 # python310 是文件夹、最后是指定版本
创建过后在 安装 anaconda3 的目录的 envs 下可看到 python310
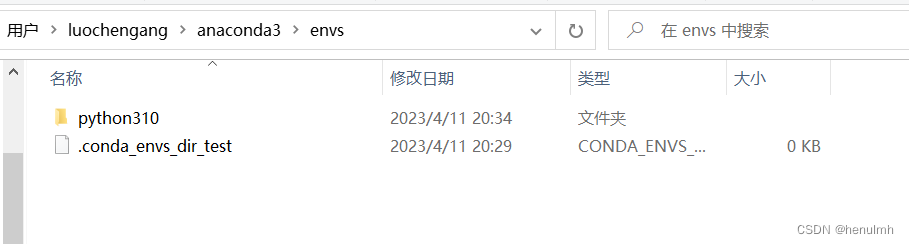
关键的一步来了。如果想用自己之前安装的python版本加入到 anaconda3 中,则直接找到自己python的位置,将其中的所有文件粘贴到此处 python310 文件夹中。直接替换即可!
使用 jupyter
activate 环境 # 先激活某一环境
jupyter notebook # 进入编辑页面
Dataset 获取数据集
Dataset 主要是提供了一种方式去获取数据以及数据的 label
下面以蚂蚁和蜜蜂的数据集图片为例,运用 Dataset。
import os.pathfrom torch.utils.data import Dataset
from PIL import Imageclass MyData(Dataset): # 继承自Datasetdef __init__(self, root_dir, label_dir):self.root_dir = root_dir # 数据总目录self.label_dir = label_dir # 总目录下的某label数据集名称self.path = os.path.join(self.root_dir, self.label_dir) # 拼接路径self.img_path = os.listdir(self.path) # 拼接后的路径下的该label所有图片def __getitem__(self, idx): # 通过索引获取到数据集中的元素img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 根据索引定位到的图片的路径img = Image.open(img_item_path)label = self.label_dirreturn img, label # 返回图片,以及该图片 labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir) # 根据路径获取到蚂蚁数据集
bees_dataset = MyData(root_dir, bees_label_dir) # 根据路径获取到蜜蜂数据集print(ants_dataset[1]) # 通过索引获取值时,相当于是调用 __getitem__ 方法,返回img 和 labeltrain_dataset = ants_dataset + bees_dataset # 数据集之间可直接相加Tensorboard
常用于展示图象,比如若想查看训练过程中图像每一步的变化,每一阶段的显示结果。
例如:如下代码
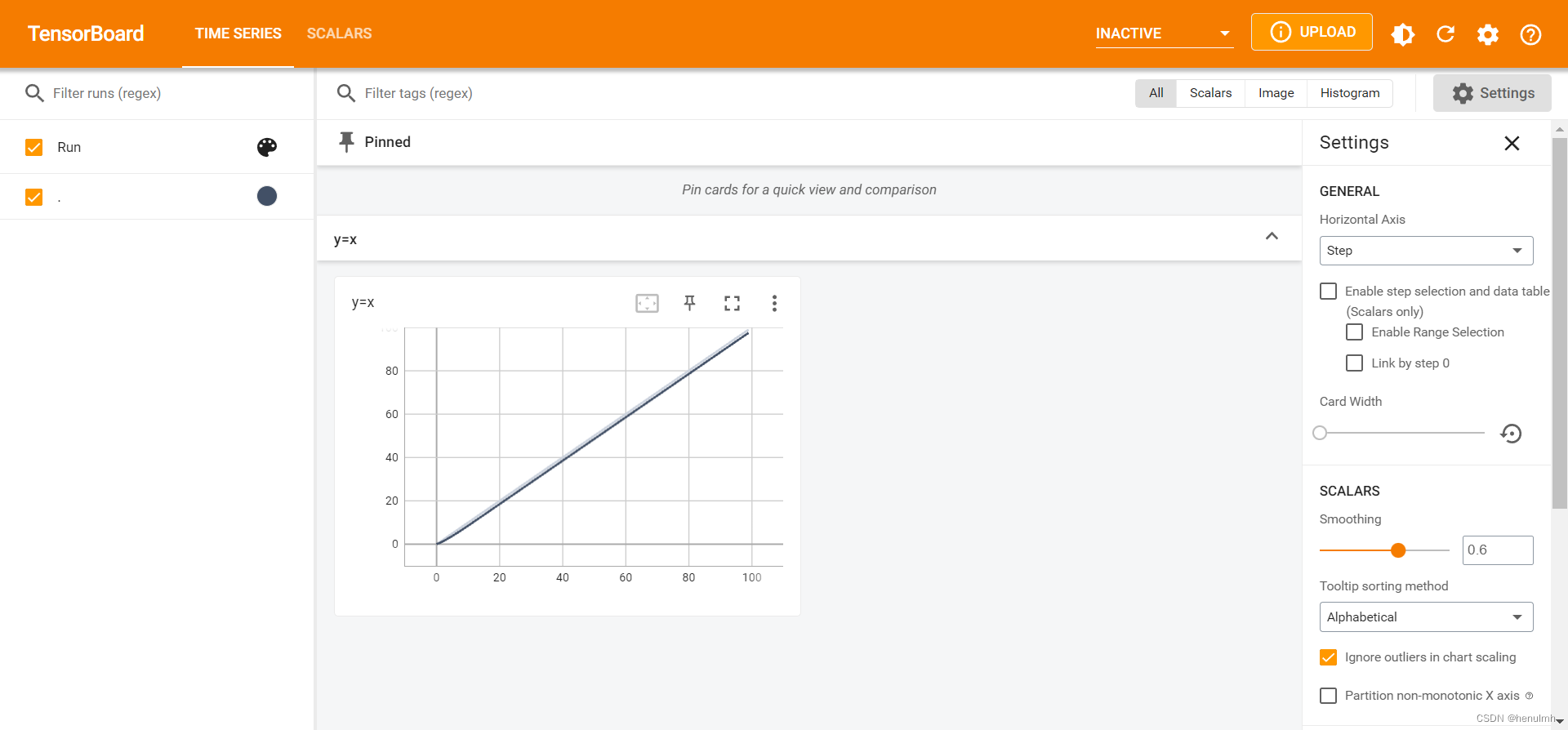
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs")
for i in range(100):writer.add_scalar("y=x", i, i)
writer.close()
执行过后在终端输入:tensorboard --logdir=logs

在给出的网址查看:
再如下面代码:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
writer = SummaryWriter("logs")
image_path = "dataset/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL) # 将类型转为 numpy 类型
print(type(img_array))
print(img_array.shape) # 形式为 HWCwriter.add_image("test", img_array, 1, dataformats="HWC") # 四个参数:名称、图像、步骤数、指定数据格式(默认接收CHW,不加会报错)writer.close()
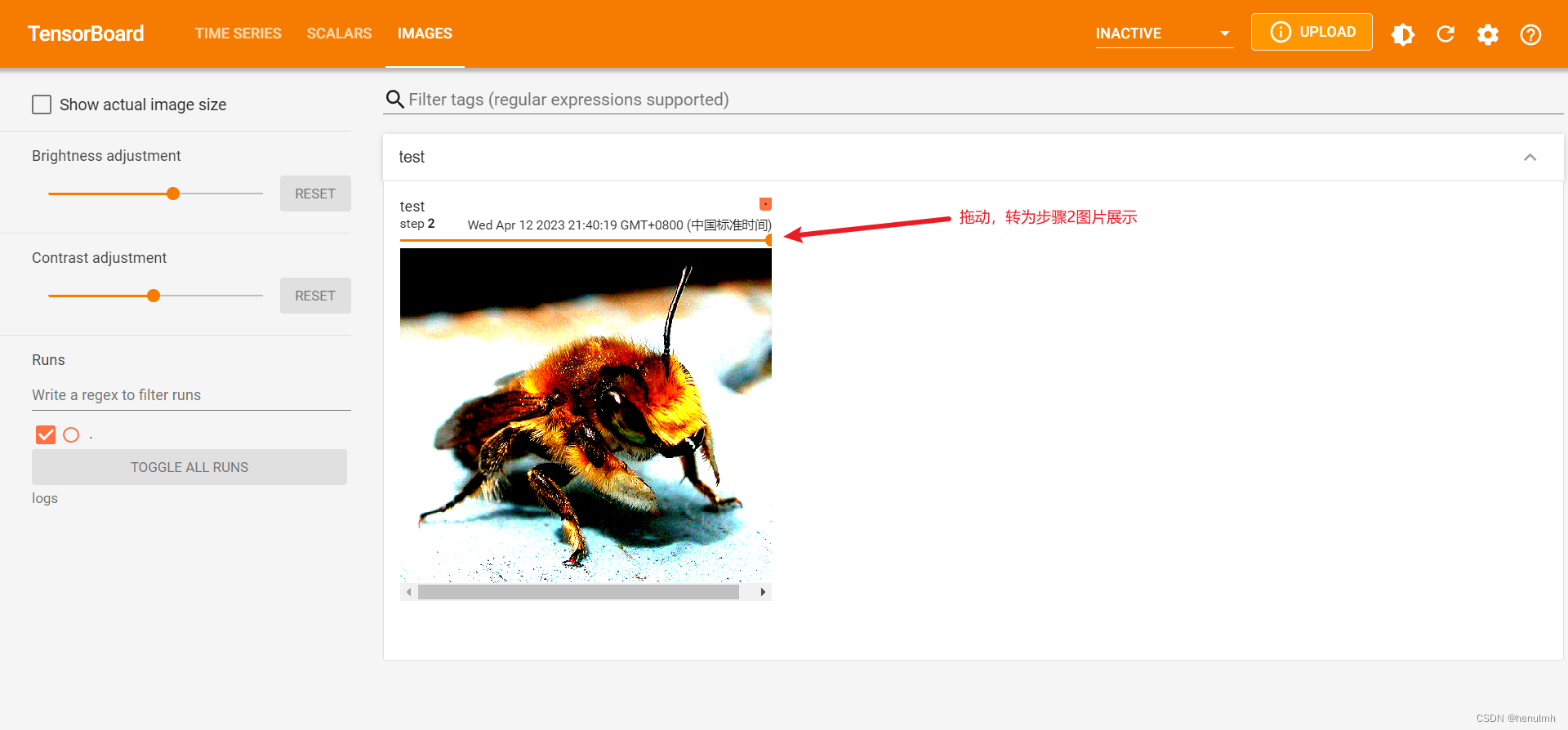
执行上面代码后,做如下改动,再执行代码。
image_path = "dataset/train/bees_image/16838648_415acd9e3f.jpg"
writer.add_image("test", img_array, 1, dataformats="HWC") # 四个参数:名称、图像、步骤数、指定数据格式(默认接收CHW,而我们图像转为numpy格式后是HWC形式,不因此需指定格式)
去网页查看:
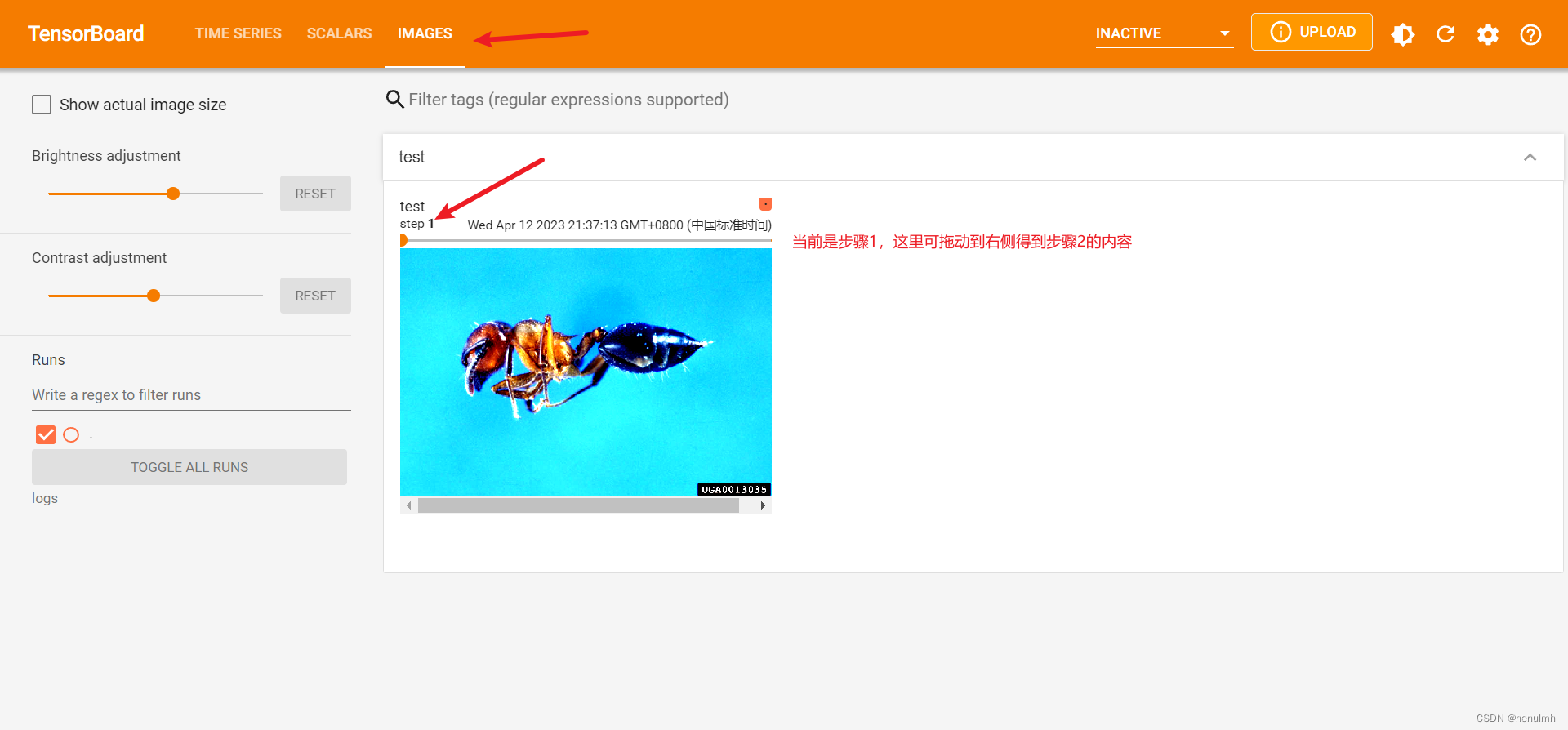
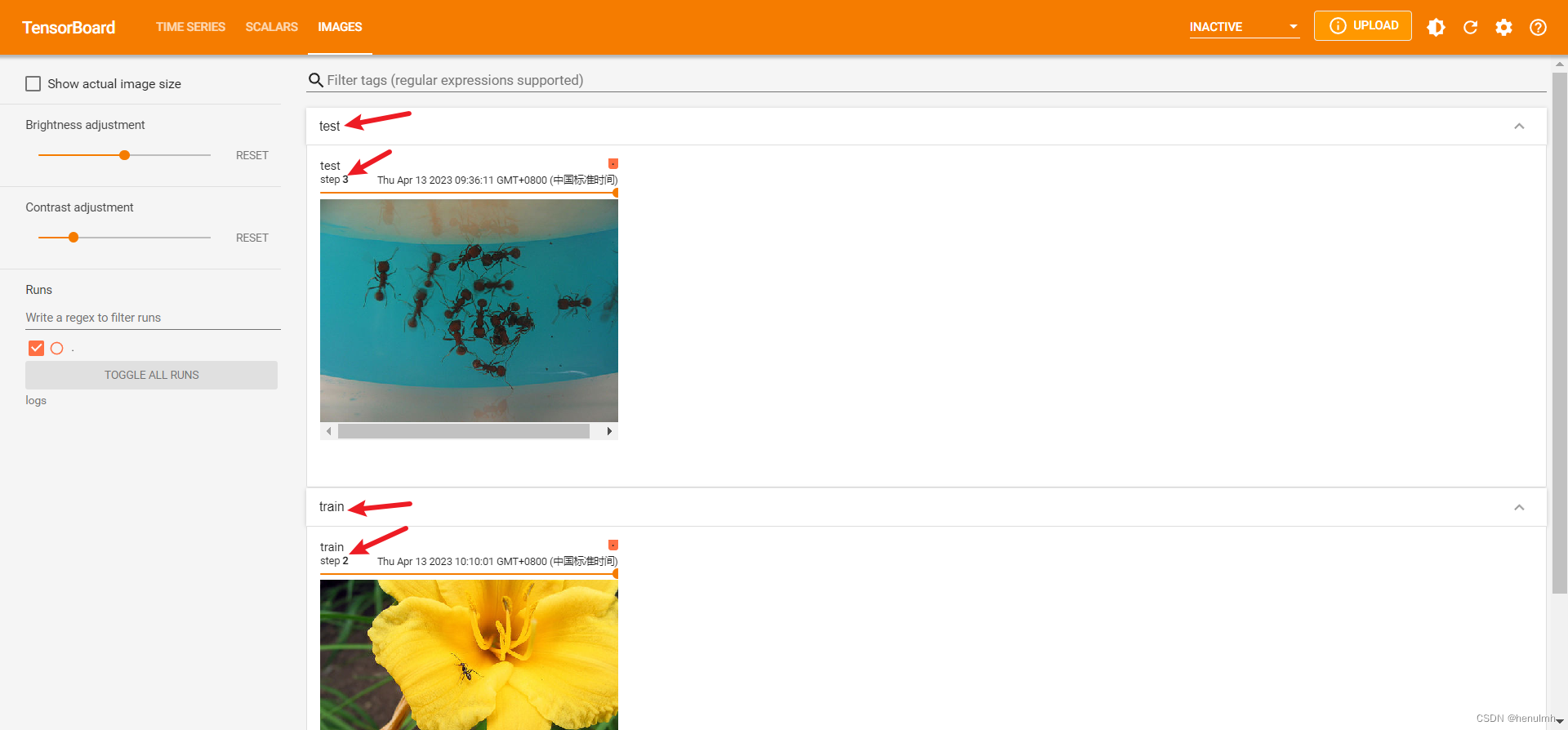
可以对不同的名称,分别展示:
writer.add_image("train", img_array, 2, dataformats="HWC") # 这里用train名称
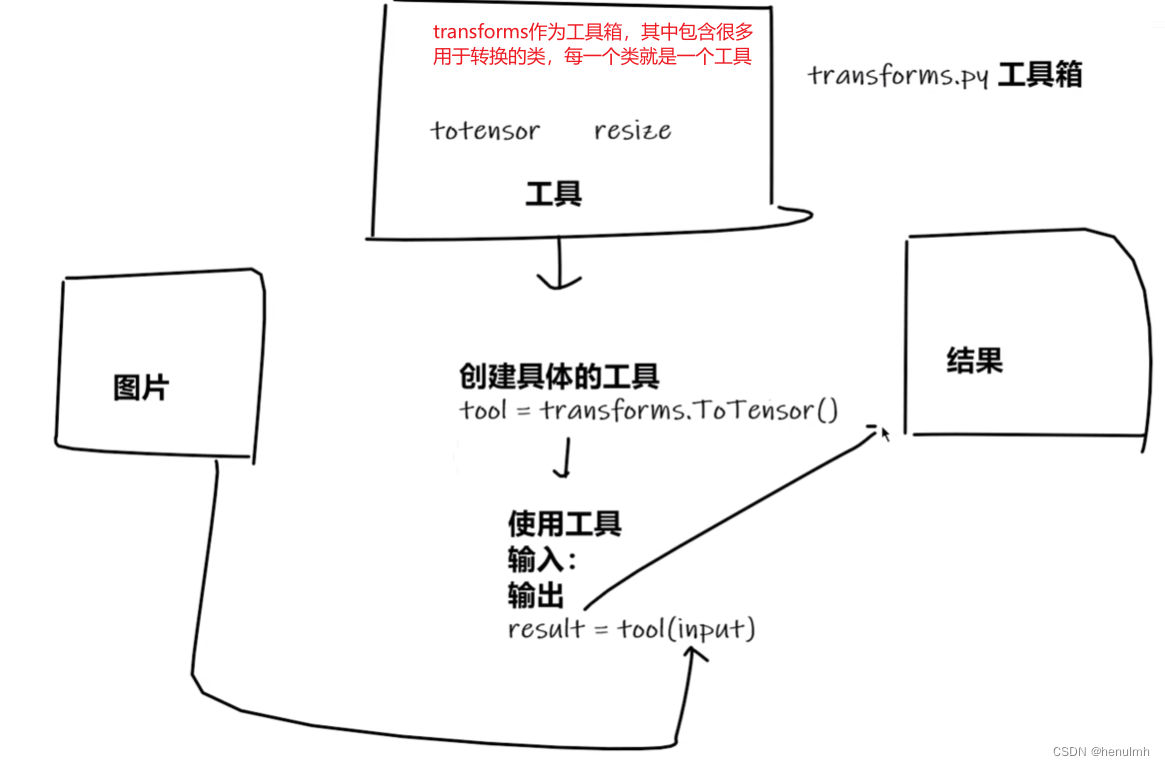
Transforms
主要用于对图片做变换、做处理
执行结构如下所示:输入图片-创建具体工具-使用工具-输出结果
tensor 数据类型包装了反向神经网络中所需要的一些理论基础参数。在神经网络中需要此数据类型进行训练。
下面结合 tensorboard,writer.add_image 传入 tensor 类型。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = "dataset/train/ants_image/0013035.jpg"
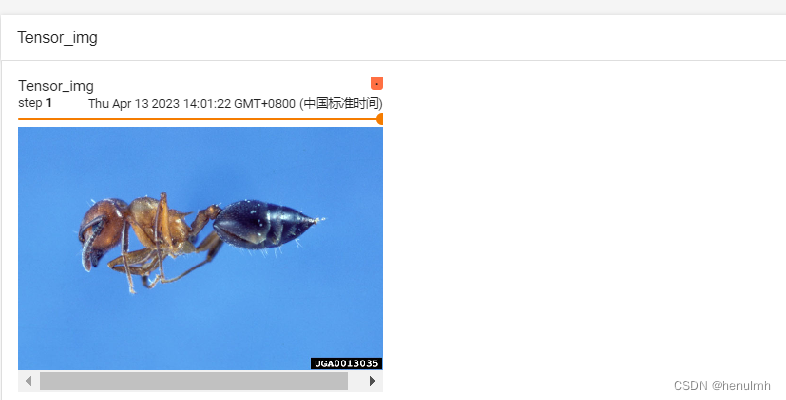
img = Image.open(img_path)writer = SummaryWriter("logs")tensor_trans = transforms.ToTensor() # transforms的 ToTensor类,接收 PIL image 或 numpy.array 类型转为 tensor类型的图片
tensor_img = tensor_trans(img) # 将图片转换为 tensor 类型,这里传入的是 PIL image类型。当用 cv2 来读取图片时:cv_img = cv2.imread(img_path) 得到的是 numpy.array类型。
print(tensor_img)
writer.add_image("Tensor_img", tensor_img, 1) # tensorboard既接收 numpy.array 类型,又接收 tensor 类型writer.close()
展示:
注:在一个方法的括号中按 ctrl + p,可查看需要传入的参数。
在 structure 可以看到 transforms.py 下的所有工具类
接下来简要再练习两个:
归一化 Normalize:
归一化是为了消除奇异值,即样本数据中与其他数据相比特别大或特别小的数据,这样可以加快训练速度。
对图片每一信道的值(比如图片的RGB值)归一化
# ToTensor
trans_tensor = transforms.ToTensor() # transforms的 ToTensor类,接收 PIL image 或 numpy.array 类型转为 tensor类型的图片
img_tensor = trans_tensor(img) # 将图片转换为 tensor 类型
print(img_tensor)
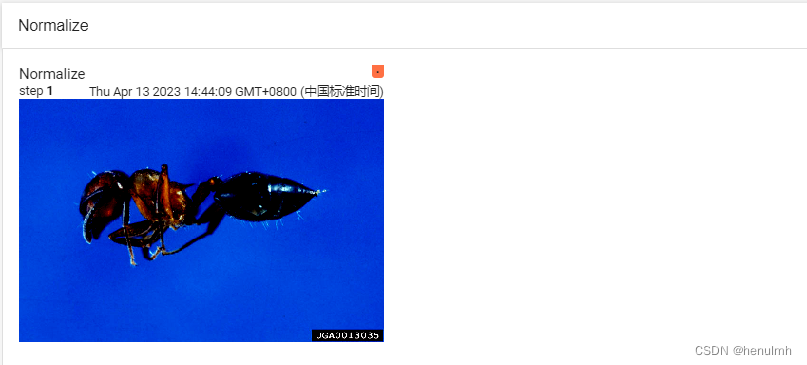
writer.add_image("Tensor_img", img_tensor, 1) # tensorboard既接收 numpy 类型,又接收 tensor 类型# Normalize 传入每个信道的均值 和 标准差
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor) # 需要输入一个 tensor 图片
writer.add_image("Normalize", img_norm, 1)
展示
换不同的参数,多执行几步,展示:
Resize
对图像进行等比的缩放。
# Resize
print(img.size)
trans_resize = transforms.Resize((128, 128))
img_resize = trans_resize(img)
img_resize_tensor = trans_tensor(img_resize)
writer.add_image("Resize", img_resize_tensor, 2)
print(img_resize)

256 x 256 -> 128 x 128

Compose
主要是对多个转换操作合并,逐个执行。
# Compose
# Resize 只传一个参数时,另一参数会进行等比缩放
trans_resize_2 = transforms.Resize(128) # 原图片为 768 x 512 ,这里只传入128,较短的512会变成128,然后768等比例缩放。
trans_compose = transforms.Compose([trans_resize_2, trans_tensor]) # 先进行 resize 变换,再进行 tensor 转换
img_resize_2 = trans_compose(img)
writer.add_image("Compose", img_resize_2, 2)
RandomCrop 随机裁剪
# 仅输入一个参数,从 768x512中 裁剪 512x512
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_tensor])
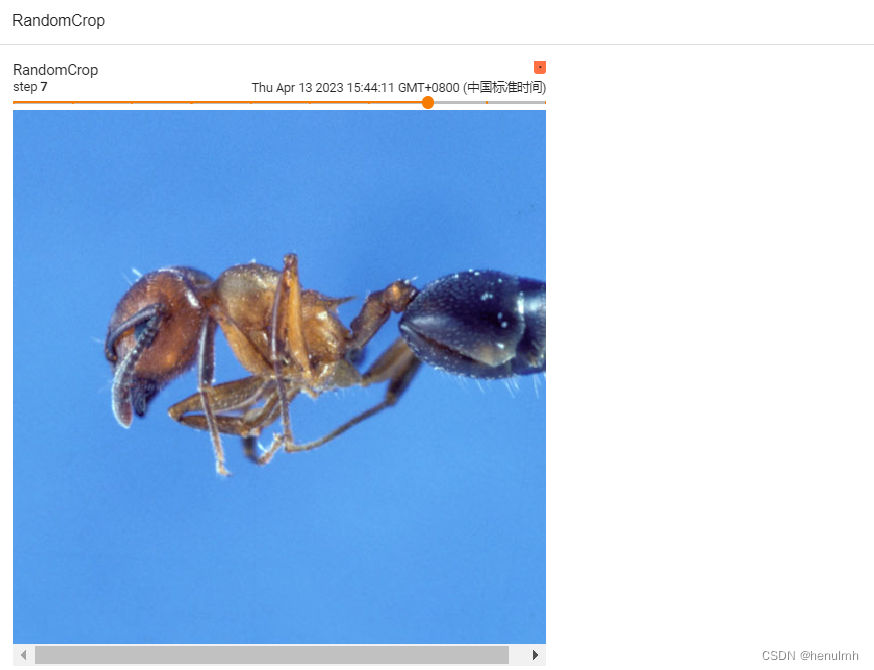
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("RandomCrop", img_crop, i)
可查看到每一步图片的大小都不变,但裁剪位置在变化。
Torchvision 中的数据集使用
在 pytorch 官网可查找常用数据集
常用数据集
这里测试采用 CIFAR-10 数据集
下载测试 CIFAR-10 数据集代码如下:
import torchvisiontrain_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True) # 当已经下载过后,再执行,就不会再下载
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)print(test_set.classes) # 数据集中所有的label
img, target = test_set[0] # test_set 第一个数据,返回图片,和该图片的label索引
print(test_set.classes[target]) # 展示该图片label
img.show() # 展示图片

下面结合 transforms 和 tensorboard 进行测试:
import torchvision
from torch.utils.tensorboard import SummaryWriterdateset_transforms = torchvision.transforms.Compose([ # 变换规则,这里只将 PIL img 转为 tensortorchvision.transforms.ToTensor()
])
# 指定变换规则,对全体数据执行此变换
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dateset_transforms, download=True) # 当已经下载过后,再执行,就不会再下载
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dateset_transforms, download=True)writer = SummaryWriter("logs")
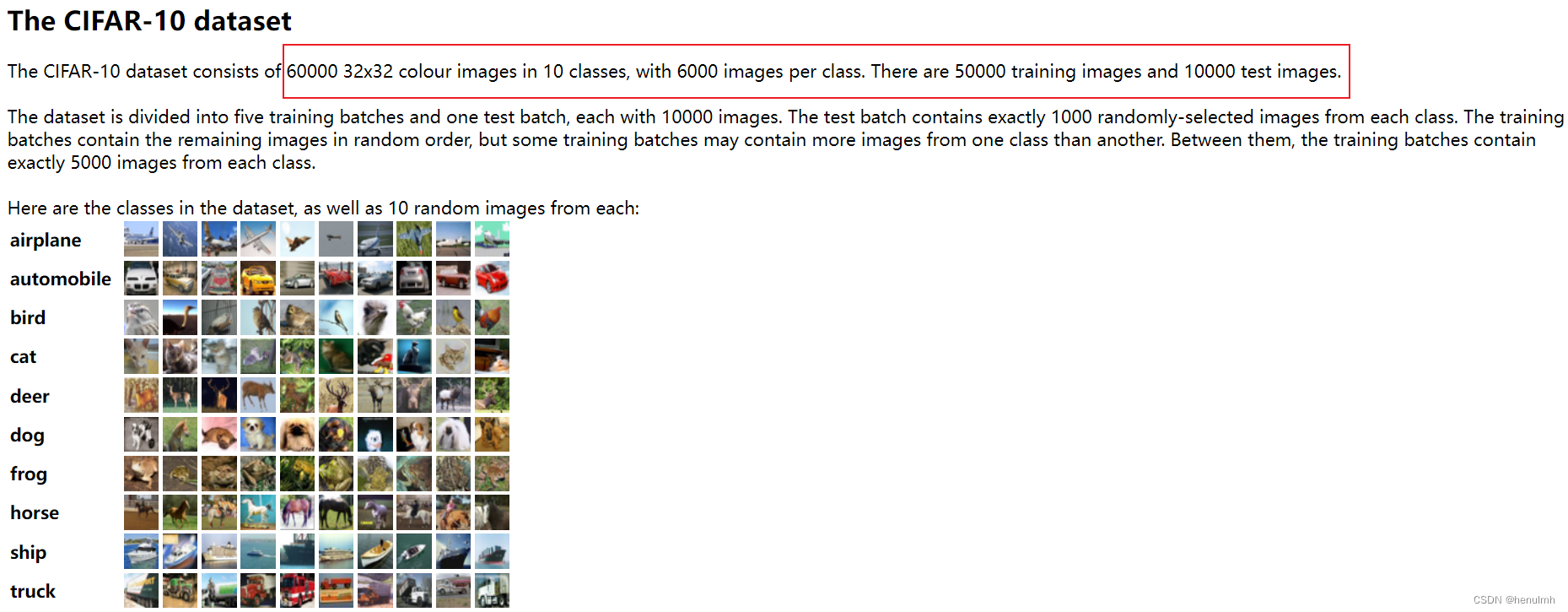
for i in range(10):img_tensor, target = train_set[i] # 获取 tensorprint(target)writer.add_image("CIFAR", img_tensor, i)
writer.close()
终端输入 :
tensorboard --logdir=logs --port=6007
展示:
Dataloader
前面说了 dataset,dataset作用主要是告诉数据集的位置,以及通过索引获取到每一个数据。
dataloader的作用是通过设置一些参数,来从 dataset 中分批次取出数据。
官方介绍:官方介绍
如下代码:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 获取数据集、并通过 ToTensor 将数据集转为 tensor
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
# 从 test_data 中获取,每次取64个,shuffle采取不打乱(epoch每一轮都一样),num_workers多进程取0,drop_last 为数据集对64取模的余数是否舍弃
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=True)# 测试数据集中第一张图片及 target
img, target = test_data[0]
print(img.shape) # [3,32,32]
print(target) # 3writer = SummaryWriter("logs")
step = 0
# 每一个 data 对应每次取出的64个数据
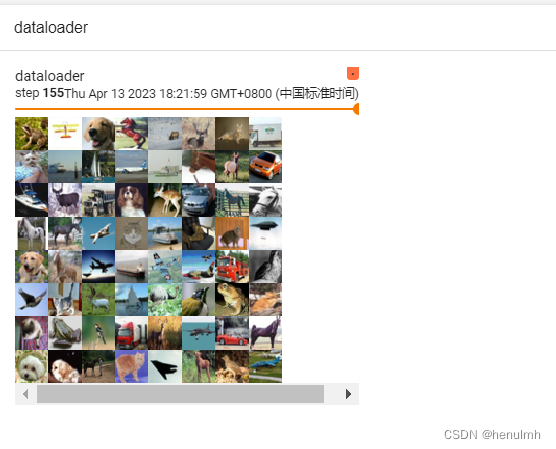
for data in test_loader:imgs, target = datawriter.add_images("dataloader", imgs, step) # 注意这里是 add_imagesstep = step + 1writer.close()
在终端执行:
tensorboard --logdir=logs --port=6007 --samples_per_plugin=images=10000000
–samples_per_plugin=images=10000000 目的是 展示出每一 step
展示如下:每一 step 展示64个数据
当把 shuffle 设为 True 时,可发现两轮 epoch 展示的数据不一致。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 获取数据集、并通过 ToTensor 将数据集转为 tensor
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
# 从 test_data 中获取,每次取64个,shuffle采取不打乱(epoch每一轮都一样),num_workers多进程取0,drop_last 为数据集对64取模的余数是否舍弃
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)# 测试数据集中第一张图片及 target
img, target = test_data[0]
print(img.shape) # [3,32,32]
print(target) # 3writer = SummaryWriter("logs")
# shuffle = True ,每轮从 test_loader 中取数据会不一致!
for epoch in range(2):step = 0for data in test_loader:imgs, target = datawriter.add_images("Epoch: {}".format(epoch), imgs, step) # 注意这里是 add_imagesstep = step + 1writer.close()
展示如下:

神经网络
官方文档:https://pytorch.org/docs/stable/nn.html