Grover算法与Qiskit-runtime的应用:数字预测

# Oracle 생성
import random
from qiskit.quantum_info import Statevectorsecret = random.randint(0,7) # 随机整数0~7
secret_string = format(secret, '03b')
#0 表示用零来填充左侧未被占满的位置。
#3 表示字符串的总宽度为 3 位。
#'b' 表示将整数转换为二进制格式的字符串。
oracle = Statevector.from_label(secret_string) # Statevector 是 Qiskit 中表示量子态的一种对象# 它描述了量子系统的所有状态信息,可以用于模拟量子电路的演化。
# 在这里,secret_string 是一个长度为 3 的二进制字符串,表示了一个所有者的标识。
# Statevector.from_label 方法将这个字符串转换为一个量子态向量,它的长度为 $2^3=8$,
# 因为这个量子电路包含 3 个量子比特,所以总共有 $2^3$ 种可能的状态。这个向量中只有一个元素为 $1$,
# 表示了一个特定的量子态,即该所有者对应的态。在这个例子中,这个量子态被称为 Oracle,因为它将被用来构造一个用于量子搜索的算法。接下来生成 Search Problem ,代码如下:
from qiskit.algorithms import AmplificationProblemproblem = AmplificationProblem(oracle, is_good_state=secret_string)这段代码创建了一个名为 problem 的 AmplificationProblem 对象,用于量子搜索的放大器算法。这个算法的目的是在一个有 nnn 个元素的列表中寻找一个特定的元素,通过询问 Oracle 来确定元素的位置。在这里,oracle 参数是一个 Statevector 类型的对象,它表示了一个量子电路,可以用来查询元素的位置。is_good_state 参数是一个字符串,表示我们要搜索的元素在列表中对应的状态。例如,如果我们要在一个长度为 8 的列表中搜索元素 5,则 is_good_state 应该设置为 ‘101’,即二进制字符串 101,对应于元素 5 的二进制表示。
在 AmplificationProblem 对象中,我们还可以设置其他参数,例如搜索列表的长度、查询 Oracle 的次数等。这些参数的设置将影响放大器算法的性能和效率。完成 AmplificationProblem 对象的构建后,我们可以将其传递给 Qiskit 中的其他算法,例如 Grover 搜索算法的实现。
from qiskit.algorithms import Grover
grover_circuits = []
for iteration in range(1,3):grover = Grover(iterations=iteration)circuit = grover.construct_circuit(problem)circuit.measure_all()grover_circuits.append(circuit)
这段代码使用 Qiskit 实现了 Grover 搜索算法的量子电路,并构建了一系列 Grover 电路,以便进行多次迭代搜索。它的作用是对于迭代次数 iteration 在 1 到 2 之间循环,执行以下操作:
创建一个 Grover 对象,设置迭代次数为 iteration。
调用 grover.construct_circuit(problem) 方法,使用 problem 参数作为输入,构建一个量子电路,该电路可以执行 Grover 搜索算法并找到 is_good_state 对应的元素。
在量子电路的所有量子比特上添加测量门,以便将最终的量子态转换为经典比特。
将构建的 Grover 电路添加到一个名为 grover_circuits 的列表中,以便后续进行模拟或执行。
在构建多个 Grover 电路之后,我们可以使用这些电路来模拟或执行多次迭代的 Grover 搜索算法,以便找到列表中特定元素的位置。
逐行分析的话,range(1,3) 返回一个迭代器,包含从 1 开始,但不包含 3 的整数序列。因此,这个迭代器将依次生成 1 和 2 两个整数。将现在的迭代次数更新到这里,在 Qiskit 中,Grover 类封装了 Grover 搜索算法的实现,可以直接使用。iterations 参数是一个整数,表示执行 Grover 搜索算法时应该迭代的次数。
circuit = grover.construct_circuit(problem)
该电路实现了 Grover 搜索算法,并用于查找 problem 对象中指定的元素。
#problem 对象是一个 AmplificationProblem 类型的实例,描述了我们要查找的目标元素在列表中的状态,并提供了一个用于查询目标元素的 Oracle 电路
construct_circuit(problem) 方法接受一个 AmplificationProblem 对象作为输入,返回量子电路,该电路可以执行 Grover 搜索算法,并找到目标元素。
在这个电路中,我们首先将所有的量子比特初始化为 ∣0⟩|0\\rangle∣0⟩ 状态,然后执行多个 Grover 迭代,每次迭代包含:
应用 Oracle 电路,使目标元素的状态翻转;应用 Diffusion 电路,使所有非目标元素的状态翻转;重复步骤 1 和步骤 2,直到搜索目标被定位。
circuit.measure_all()
在所有量子比特上添加测量,转化为经典bit
grover_circuits.append(circuit)
把这个grover电路添加到之前创建的空集电路中,以便后续模拟或执行。
通过在列表中保存多个 Grover 电路,我们可以轻松地比较不同迭代次数的 Grover 搜索算法的性能和效率,并找到最优的搜索策略。
grover_circuits[0].draw('mpl')
grover_circuits[1].draw('mpl')print(grover_circuits)
该步骤执行后可以直观的输出量子电路图,由于比较简单就不上图了。
#from qiskit import IBMQ#api_key = "API"
#IBMQ.save_account(api_key)
#from qiskit_ibm_provider import IBMProvider#api_key = "API"
#IBMProvider.save_account(api_key)
# 只需要执行一次,在本地生成token
这段代码只需要执行一次,即便不在本程序中执行也可以。作用是将 IBM账户的令牌保存在本地后,使用IBM合法身份访问对应的量子设备,进而执行我们想要的结果。
from qiskit_ibm_runtime import QiskitRuntimeServiceservice = QiskitRuntimeService()
backend = "ibmq_qasm_simulator" from qiskit_ibm_runtime import Sampler, Session, Optionsoptions = Options(simulator={"seed_simulator": 42}, resilience_level=0)with Session(service=service, backend=backend):sampler = Sampler(options=options)job = sampler.run(circuits=grover_circuits, shots=1024)result = job.result()print(result)这段代码使用了 Qiskit Runtime Service 提供的 QiskitRuntimeService 类,创建了一个与 Qiskit Runtime 服务通信的客户端对象service。Qiskit Runtime 是一个基于云端的量子计算服务,提供了一种快速且高效的方式来运行和优化量子程序,包括 Grover 搜索算法。
使用 Qiskit Runtime Service 提供的 Sampler 类来将 Grover 量子电路发送到后端进行模拟或执行。
options = Options(simulator={“seed_simulator”: 42}, resilience_level=0)
在创建 Sampler 对象时,我们使用了一个名为 options 的参数,它是一个包含模拟器选项和容错级别的字典。
我们指定了 QASM 模拟器的随机种子值为 42,以确保每次模拟的结果都是相同的。
随机种子是一个可以控制随机数生成的值,它可以帮助我们重现和调试量子程序的结果。
此外,我们将容错级别设置为 0,表示在模拟或执行过程中不进行任何容错操作,以加快程序的运行速度和降低错误率,但可能会影响结果的准确性和稳定性。
sampler = Sampler(options=options)
Sampler 类封装了 Qiskit Runtime 服务的采样器功能,可以将量子程序发送到后端执行,并返回测量结果。
这个option传递的值是一个包含模拟器选项的词典,包含simulator参数(种子的值);resilience_level(容错级别)
from qiskit.tools.visualization import plot_histogramresult_dict = result.quasi_dists[1].binary_probabilities()
answer = max(result_dict, key=result_dict.get)
print(f"As you can see, the quantum computer returned '{answer}' as the answer with highest probability.\\n""And the results with 2 iterations have higher probability than the results with 1 iteration."
)#上下没有太大关系,上面的代码获得1或者2迭代中的最大概率事件。并非两个迭代种类中的不同事件。
#plot_histogram(result_dict, legend=['1 iteration'])
plot_histogram(result.quasi_dists, legend=['1 iteration', '2 iterations'])
这个函数的原理是将 Qiskit Runtime 返回的 Result 对象中的测量结果 quasi_dists 转换为一个字典,其中包含每个二进制字符串的测量次数和概率。测量结果可以被表示为一个字典,其中每个键是一个二进制字符串,表示测量得到的状态,每个值是一个整数,表示测量得到该状态的次数。这个字典可以使用 result.get_counts(circuit) 方法获取,其中 circuit 是要测量的量子电路对象。使用 Qiskit Runtime 服务时,测量结果并不是通过 get_counts() 方法返回的,而是作为 Result 对象的一个属性 quasi_dists 存在。因此,我们需要使用 binary_probabilities() 方法将 quasi_dists 转换为一个字典,以便对测量结果进行后续处理和分析。binary_probabilities() 方法的工作原理是将 quasi_dists 对象中的测量结果转换为一个列表,其中每个元素都是一个 BinaryDistribution 对象。BinaryDistribution 对象表示一个二进制字符串和其对应的测量次数和概率使用 [1] 索引来获取列表中的第二个元素,也就是包含了 2 次迭代结果的 BinaryDistribution 对象。我们使用 binary_probabilities() 方法从该对象中提取二进制字符串和其对应的概率,并将其保存为一个字典 result_dict。该字典的键是二进制字符串,值是对应的测量概率。
answer = max(result_dict, key=result_dict.get) 这行代码的作用是从测量结果的字典 result_dict 中获取具有最大概率的状态,即概率分布最大的二进制字符串。这个字符串代表了搜索到的目标元素在列表中的状态。max() 函数的第一个参数是要进行比较的可迭代对象,这里是 result_dict 字典。key 参数是一个可选的函数,用于指定用于比较的键。在这里,我们使用 get 函数作为 key 参数,它将返回每个键对应的值,即测量概率。通过将 key=result_dict.get 传递给 max() 函数,我们告诉它在比较字典中的值时使用字典的值作为键,而不是键本身。因此,max() 函数将返回具有最大测量概率的键,也就是我们搜索到的目标元素的状态。
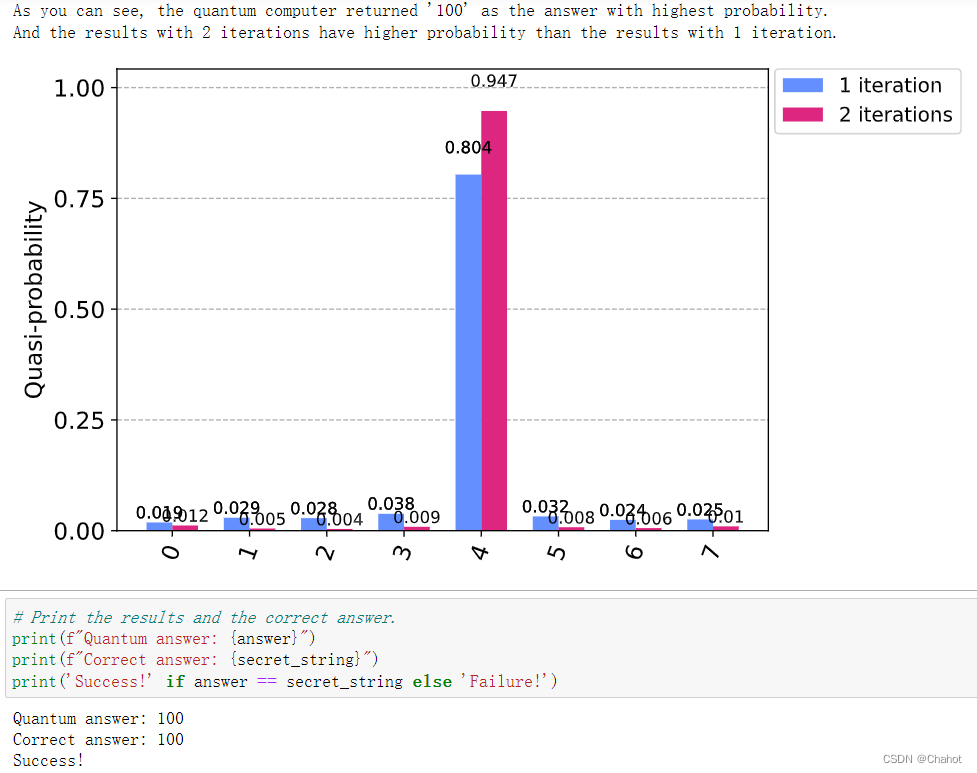
最后的运行结果如上所示。