【基础】索引

索引目的:
-
快速的查找我们的数据
索引的优势和劣势
-
优势
-
类似于书籍的目录索引,提高数据检索的效率,降低数据库的io成本
-
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
-
-
劣势
-
实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的
-
虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT,UPDATE,DELETE。因为更新表时,MYSQL不仅要保存数据,还需保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的简直变化后的索引信息
-
索引的结构
-
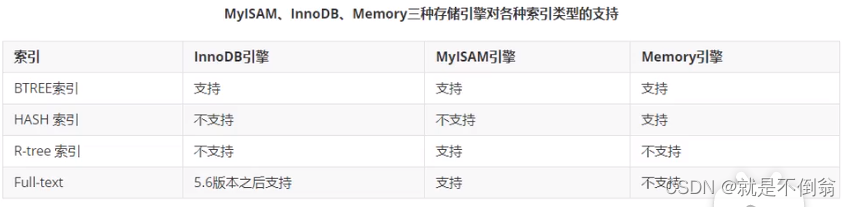
索引在mysql的存储引擎中实现的,而不是在服务器层实现的,所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。mysql目前提供了以下4种索引
-
BTree 索引:最常见的索引类型,大部分索引都支持B树索引
-
HASH索引:只有Memory引擎支持,使用场景简单
-
R Tree索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍
-
Full-text(全文索引):全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引
-
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引,其中聚集索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称为索引
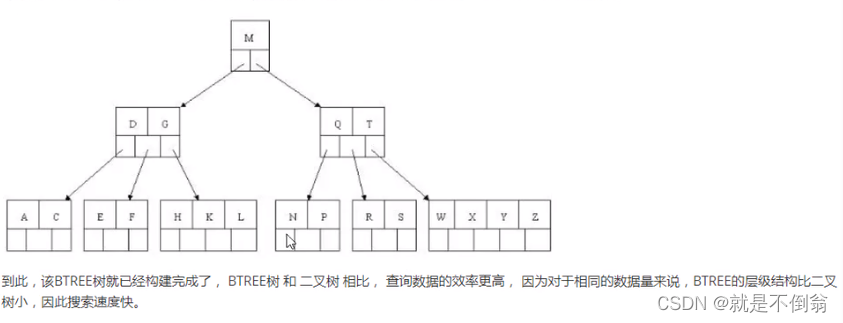
BTree结构
-
Btree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
-
树中每个节点最多包含m个孩子
-
除根节点与叶子节点外,每个节点至少又【cell(m/2)-1】个孩子
-
若根节点不是叶子节点,则至少有两个孩子
-
所有的叶子节点都在同一层
-
每个非叶子节点由n个key与n+1个指针组成,其中【cell(m/2)-1】<=n<=m-1
-
B+Tree结构
-
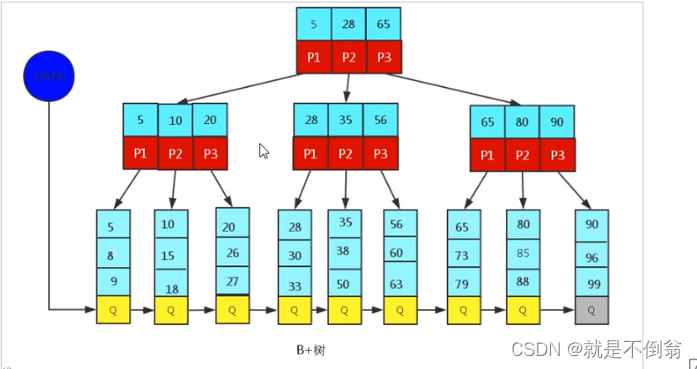
B+Tree为BTree的变种,B+Tree与BTree的区别为
-
n叉B+Tree最多包含有N个key,而BTree最多包含有n-1个key
-
B+Tree的叶子节点保存所有的key的信息,依key大小顺序排序
-
所有的非叶子节点都可以看作是key的索引部分
-
-
由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子,所以B+Tree的查询效率更加稳定
Mysql中的B+Tree
-
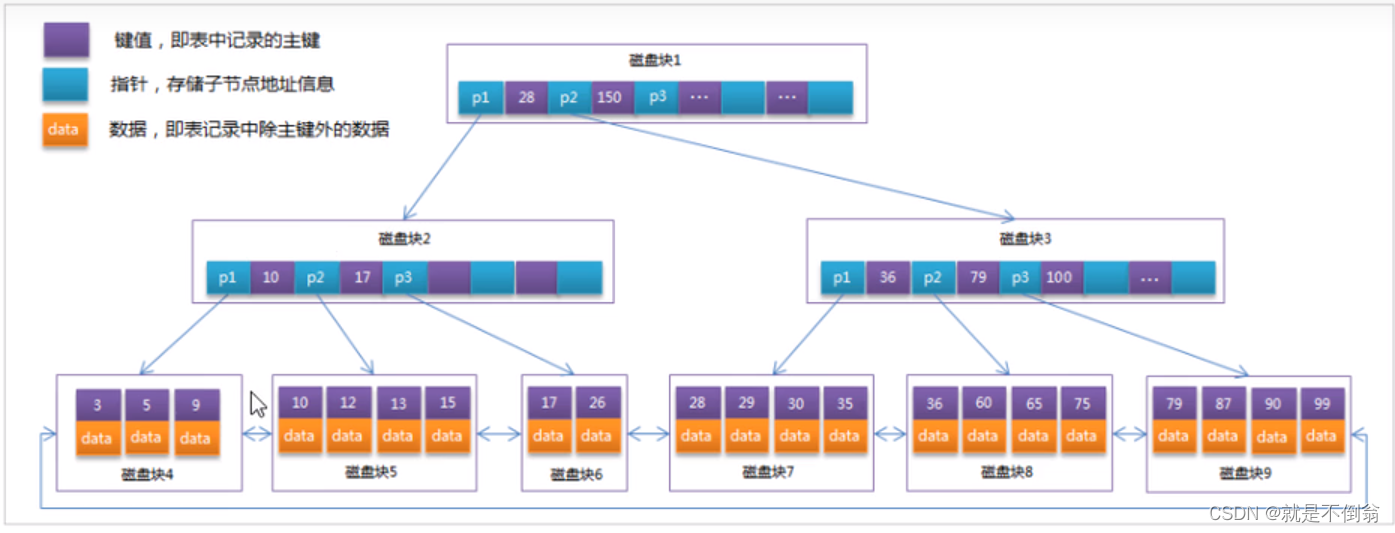
mysql索引数据结构对经典的B+Tree进行了优化,在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能
-
Mysql中的B+Tree索引结构示意图:
-
索引的分类:
-
单列索引:即一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引:索引列的值必须是唯一的,可以空值
-
复合索引:一个索引包含多个列
索引的语法:
创建索引:
-
不写索引类型,默认都是BTree类型
create index 索引名 on 表名(字段名);
查询索引:
show index from 表名
删除索引:
drop index from 索引名 on 表名
ALTER命令:
创建唯一索引 alter table 表名 add unique 表名(字段) 普通索引 alter table 表名 add index 表名(字段) 全文索引 alter table 表名 add fulltext 表名(字段)
索引设计原则:
索引的设计可以遵循一些已有的原则,创建索引的时候尽量考虑符合这些原则,使用提升索引的使用效率,更高效的使用索引。
-
对查询频繁次较高,且数量比较大的表建立索引
-
索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用,过滤效果最好的列的组合
-
使用唯一索引,区分度越高,使用索引的效率越高
-
索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然也就水涨船高,对于插入,更新,删除等DML操作比较频繁的表来说,索引过多,就引入相当高的维护代价,降低DML操作的效率,增加相应操作的时间消耗,另外索引过多的话,MYSQL也会犯选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价
-
使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的io效率,也可以提升总体的访问效率,假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升mysql访问索引的io效率
-
利用最左前缀,N个列组合而成的组合索引,南无相当于是创建了N个索引,如何查询时where子句中使用了组成该索引的前几个字段,南无这条查询sql可以利用组合索引来提升查询效率
什么是索引? 有什么用?
-
索引就相当于一本书目录,通过目录可以快速的找到对应的资源
在数据库方面,查询一张表的时候,有两种检索方式:
-
第一种方式:全表扫描
-
第二种方式:根据索引检索(效率很高)
索引为什么可以提高检索效率呢?
-
其实最根本的原理是缩小了扫描范围
索引虽然可以提高检索效率,但是不能随意的添加索引,因为索引也是根据数据库当中的对象,也需要数据库不断的维护,是有维护成本的。比如,表中的数据经常被修改这样就不适合添加索引,因为数据一旦修改,索引需要重新排序,进行维护
添加索引是给某一个字段,或者所某些字段添加索引。
select ename,sal from emo where ename = `SMITH`;
-
当ename字段上没有添加索引的时候,以上sql语句会进行全表扫描,扫描ename字段中所有的值
-
当ename字段上添加索引的时候,以上sql语句会根据索引扫描,扫描ename字段中所有的值
怎么创建索引对象?怎么删除索引对象?
-
创建索引对象:
-
create index 索引名称 on 表名(字段名);
-
-
删除索引对象:
-
drop index 索引名称 on 表名;
-
什么时候考虑给字段添加索引?(满足什么条件)
-
数据量庞大(根据客户的需求,根据线上的环境)
-
该字段很少的DML操作(因为字段进行修改操作,索引也需要维护)
-
该字段经常出现在where子句中。(经常根据那个字段查询)
注意:主键和具有unique约束的字段自动会添加索引
-
根据主键查询效率较高,尽量根据主键检索
查看sql语句的执行计划:
-
查看这个字段下有没有索引
explain select ename,sal from emp where sal = 5000;
给薪资sal字段添加索引:
create index emp_sal_index on emp(sal);
给薪资sql字段删除索引:
drop index emp_sql_index on emp;
索引底层采用的数据结构是:B+Tree
索引的实现原理?
-
通过B Tree缩小扫描范围,底层索引进行了排序,分区,索引会携带数据在表中的物理地址 ,最终通过索引检索到数据之后,获取到的物理地址,通过物理地址定位表中的数据,效率是最高的。
-
本来是:
-
select ename from emp where ename = ‘SMITH’;
-
-
通过索引转换为:
-
select ename from emp where 物理地址 = 0x3;
-
索引的分类:
-
单一索引:给单个字段添加索引
-
复合索引:给多个字段联合起来添加1个索引
-
主键索引:主键上会自动添加索引
-
唯一索引:有unique约束的字段上会自动添加索引
索引什么时候失效?
-
模糊查询的时候,第一个通配符使用的是%,这个时候索引是失效的