论文阅读_GLaM

论文信息
name_en: GLaM:Efficient Scaling of Language Models with Mixture-of-Experts
name_ch: GLaM:使用混合专家有效扩展语言模型
paper_addr: http://arxiv.org/abs/2112.06905
doi: 10.48550/arXiv.2112.06905
date_read: 2023-03-26
date_publish: 2022-08-01
tags: [‘深度学习’,‘自然语言处理’]
journal: ICML 2022(会议)
author: Nan Du,Google
citation: 89
读后感
针对节约计算资源的研究,推进了针对细分专家领域。
一种混合专家(MoE)模型,可以将其视为具有不同子模型(或专家)的模型,每个子模型都专门针对不同的输入。每层中的专家由门控网络控制,该网络根据输入数据激活专家。
摘要
文中提出 GLaM (Generalist Language Model) 通用语言模型,它使用稀疏激活的专家混合架构来扩展模型容量,同时与密集变体相比,训练成本也大大降低,其中输入批次中的每个标记仅激活 96.6B(1.2T 的 8%)参数的子网络。
最大的 GLaM 有 1.2 万亿个参数,大约是 GPT-3 的 7 倍。它仅消耗用于训练 GPT-3 的 1/3 的能量,并且只需要一半的计算触发器来进行推理。
介绍
算力和效果

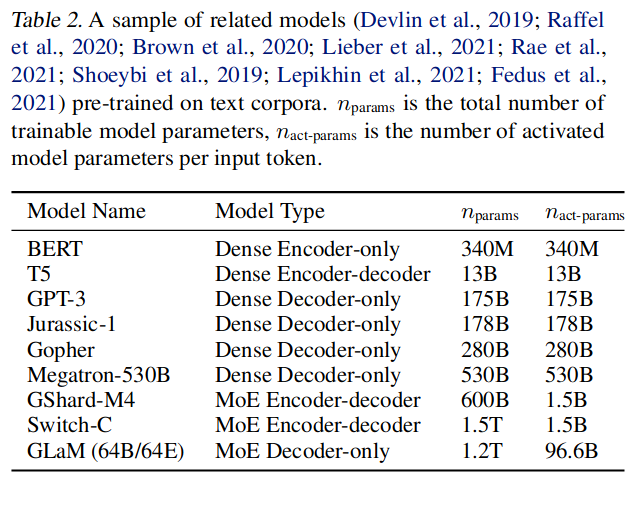
模型结构对比
训练数据
使用1.6T token,开发了自己的文本质量分类器,以从大型原始语料库中生成高质量的网络语料库。通过使用 Pareto 分布根据网页的分数对网页进行抽样来应用此分类器。
数据如下图所示:

模型结构

每个 MoE 层(底部灰块)与 Transformer 层(上部块)交错。对于每个输入token,例如“玫瑰”,门控模块从 64 个专家中动态选择两个最相关的专家,由 MoE 层中的蓝色网格表示。这两个专家的输出的加权平均值将被传递到上层的 Transformer 层。专家是被稀疏激活的,从而节约了计算资源。在推理阶段,同样是针对每个token选择两个专家。
实验
作者训练规模不同的多个GLaM模型,并在Zero/Few Shot, 自然语言生成(NLG),自然语言理解(NLU)等任务中评测了模型。
模型效果对比:

没有注入知识图,仅是从当前信息里直接学习。
实验还对比了根据质量筛选数据对模型训练的影响。过滤后的网页包含 143B 个token,而未过滤的网页包含大约 7T 个token。图-3©(d)展示了过滤前后的对比,说明有些任务需要高质量的数据训练。

图-3的(a)(b)展示了,在各种计算量条件下,MoE都表现出相对稠密模型更好的效果。
模型名称定义如下表所示,E表示专家个数。

图-4展示了模型效果和效率:

从左边三个图可以看出,达到相同效果稀疏模型需要的token更少,且稀疏模型优于稠密模型。从右边的图也可以看到稀疏模型有效节约了资源。