海量数据去重的Hash与BloomFilter,bitmap,分布式一致性hash

目录
- 1.hash
-
- 1.1 散列表
- 1.2 hash函数
- 1.3 hash冲突
- 2.BloomFilter(布隆过滤器)
-
- 2.1 定义
- 2.2 原理
- 2.3 应用场景
- 2.4 应用分析
- 3.分布式一致性hash
-
- 3.1 背景
- 3.2 原理
1.hash
1.1 散列表
- 组成:hash函数 ,数组
- 记录了key与节点存储位置的映射关系
- 查找效率:二叉树通过比较key进行查找,如果比较key的效率比较低,查找的效率也会比较低;hash散列表通过hash函数将key值映射到节点的存储位置,从而实现查找,查找效率取决于hash函数的计算效率
1.2 hash函数
- 映射函数Hash(key) = addr,hash函数可能把两个或两个以上的不同的key值映射到同一地址,这种情况称为冲突(或哈希碰撞)
- 选择hash:计算速度快,强随机分布(等概率,均匀的分布在整个地址空间)
- murmurhash1(计算速度快,但分布质量一般),murmurhash2(计算速度和分布质量都还可以),murmurhash3(计算速度慢,但分布质量最好)siphash(redis6.0中使用,rust等大多数语言选用的hash算法来实现hashmap),cityhash都具备强随机分布性
- siphash主要解决字符串接近的强随机分布性
1.3 hash冲突
- 负载因子
- 数组存储元素的个数/数组长度
- 用来形容散列表的存储密度/hash冲突的程度;负载因子越小,冲突程度越小;负载因子越大,冲突程度越大
- 解决冲突:
2.1 负载因子在合理范围内时(<1)
- 链表法:将冲突元素用链表连接起来,如果冲突元素过多,链表过长,可以将链表转换为红黑树、最小堆,降低查询时间复杂度。可以采用超过256个(经验值)节点的时候将链表结构转换为红黑树或堆结构(Java hashmap)
- 开放寻址法:将所有的元素都存在哈希表的数组中,不适用额外的数据结构;一般使用线性探查的思路解决;
a. 当插入新元素时,使用哈希函数在哈希表中定位元素位置
b. 检查数组中该槽位是否已经存在元素。如果该槽位为空,则插入,否则c
c. 在b检测的槽位索引上加一定步长(i+1,i+2,i+3…或i-1²,i+2²,i-3²…)接着检查2
d.会导致同类hash聚集,也就是近似的key值它的hash值也近似,所在的数组槽位也比较靠近,形成hash聚集。第一种(i+1,i+2,i+3…)冲突聚集在前,第二种(i-1²,i+2²,i-3²…)只是将聚集冲突延后;另外还可以使用双重哈希来解决上面出现的hash聚集现象
2.2 负载因子不在合理范围内
- 扩容:数组存储元素的个数 > 数组长度,通常采取翻倍扩容的方式,并rehash,可以解决冲突
- 缩容:数组存储元素的个数 < 数组长度 * 0.1,为了节约空间
2.BloomFilter(布隆过滤器)
2.1 定义
- 布隆过滤器是由位图和k个hash函数构成的
- 有时,我们不需要通过key查找特定的value,只是想确定某个key是否存在,又或是为了节省内存,可以使用布隆过滤器。
2.2 原理
- 当一个元素加入位图时,通过k个hash函数将这个元素映射到位图的k个位置,并把它们都置为1;当检索时,再通过k个hash函数运算检测位图的k个点是否都为1 ;如果有不为1的点,那么认为该key不存在;如果全部为1,则可能存在
- 为什么不支持删除操作:在位图中每个槽位只有两种状态(0或1),一个槽位被置为1状态。但不确定它被设置了多少次;也就是不知道被多少个key映射而来以及是被具体哪个key映射而来
2.3 应用场景
布隆过滤器通常用于判断某个key一定不存在的场景,同时允许判断存在一定程度的误差
2.4 应用分析
- n:预期布隆过滤器中元素的个数
- p:假阳率,在0-1之间
- m:位图所占空间
- k:hash函数的个数
公式如下:
- n = ceil( m / ( -k / log(1-exp(log( p ) / k) ) )
- p = pow( 1 - exp(-k / (m/n)), k )
- m = ceil( ( n * log( p ) ) / log(1 / pow(2, log(2)) ) )
- k = round( (m/n) * log(2) )
在实际使用布隆过滤器时,首先需要确定n和p,通过上面的公式运算得出m和k;通常可以在下面的网站上选出合适的值:Bloom filter calculator
3.分布式一致性hash
3.1 背景
- 假设服务器只有一个缓存结点,当存储的数据越来越多时,效率就会变得很低,这时就需要增加结点分流分压
- 使用hash来控制节点分布:hash(key) % n,在扩容时出现算法改变:hash(key) % (n+1),会造成大面积的缓存失效(即扩容后,通过新的hash算法得到的结点的存储位置和实际结点的存储位置不一致)问题
3.2 原理
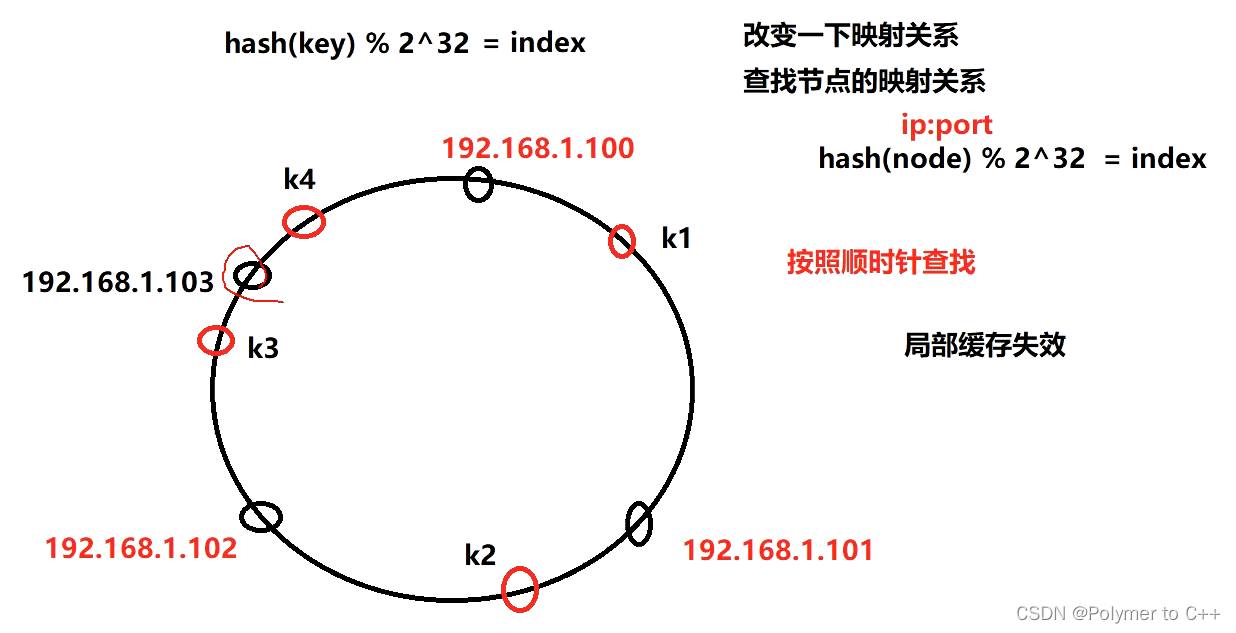
数据哈希值:hash(key) % 232,图中用红色小圈表示;机器哈希值:hash(node) % 232,图中用黑色小圈表示。
- 映射空间可抽象为一个环,长度为 232,范围为[0, 232-1],每个服务器结点根据hash(node) % 232被映射到这个环上
- 判断一条数据属于哪个服务器节点的方法:根据数据哈希值,去哈希环找到第一个机器哈希值大于等于数据哈希值的机器(假设约定按顺时针查找)。如果数据的哈希值大于当前最大的机器哈希值,那么就把这个数据放在位置最靠前(哈希值最小)的机器上
- 由于实际机器结点往往较少,通过hash算法又具有随机性,容易导致哈希偏移问题(例如目前一共有3台机器,机器A、B的哈希值分别为1和2,而另一个机器C的哈希值为 2^32-1,那么大部分的数据都会被分给机器C)。
- 因此引入了虚拟节点概念,虚拟节点相当于真实节点的分身,一个真实节点可以有很多个虚拟节点,当数据被分配给这些虚拟节点时,本质上是分给这个真实节点的。数量变多了,机器结点分布的随机性会有所提高,解决了数据结点存储分布不均的问题
- 新增节点时:例如原本的节点哈希值列表为[1,500,1000,5000],新增节点3000后,在1001~3000范围内的数据原本是分给哈希值为5000的机器节点的,现在要把这部分数据迁移到节点5000,称为哈希迁移
- 删除节点:例如原本的节点哈希值列表为[1,500,1000,5000],删除节点1000后,原本范围是501~1000的数据要迁移到节点5000