【大数据Hive】Hive ddl语法使用详解

一、前言
使用过关系型数据库mysql的同学对mysql的ddl语法应该不陌生,使用ddl语言来创建数据库中的表、索引、视图、存储过程、触发器等,hive中也提供了类似ddl的语法。本篇将详细讲述hive中ddl的使用。
二、hive - ddl 整体概述
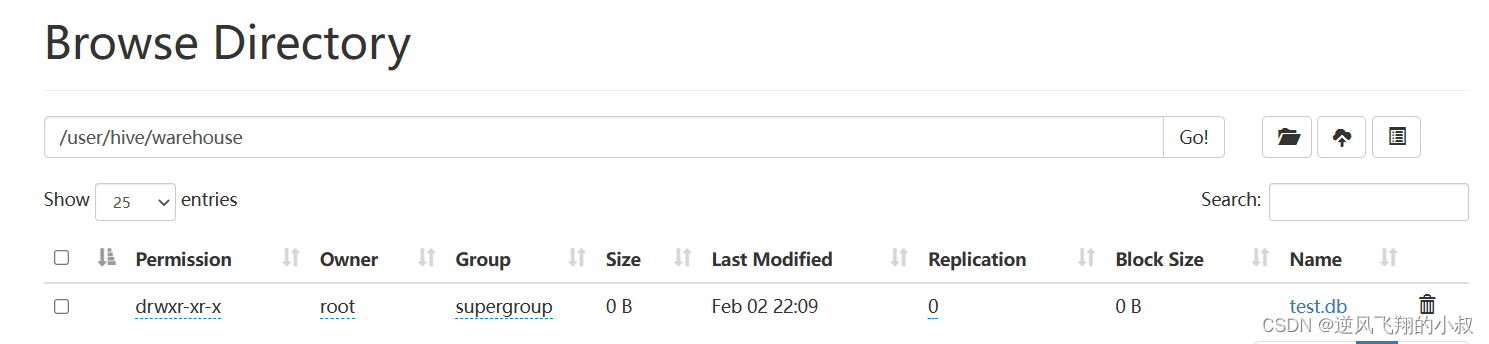
在Hive中,DATABASE的概念和RDBMS中类似,我们称之为数据库,DATABASE和SCHEMA是可互换的,都可以使用,默认的数据库叫做default,存储数据位置位于/user/hive/warehouse下,用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。
如下是我们操作演示时候创建的一个名叫test的数据库,在hdfs上的目录展示如下
ddl主要包括数据库数据表相关的操作,接下来分别通过操作进行演示说明
三、数据库操作
3.1 创建数据库完整语法
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];参数说明:
- COMMENT:数据库的注释说明语句;
- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db;
- WITH DBPROPERTIES:用于指定一些数据库的属性配置;
3.2 数据库操作 DDL
创建一个数据库
create database if not exists mydb
comment "this is my first db"
with dbproperties ('createdBy'='congge');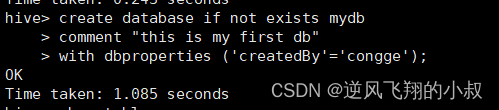
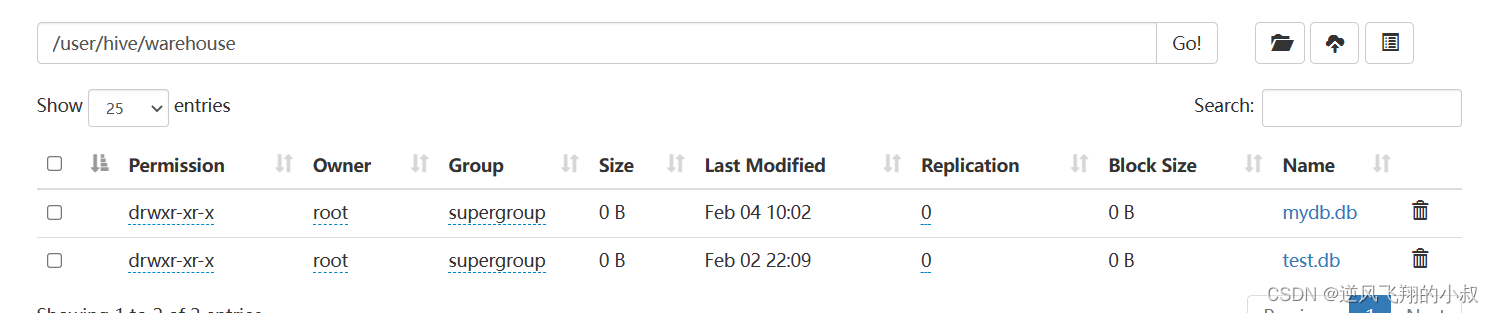
创建成功后hdfs上就创建了与库对应的目录
查看数据库信息
可以通过下面的命令查看数据库的信息
describe database mydb;
describe database extended mydb;
desc database extended mydb;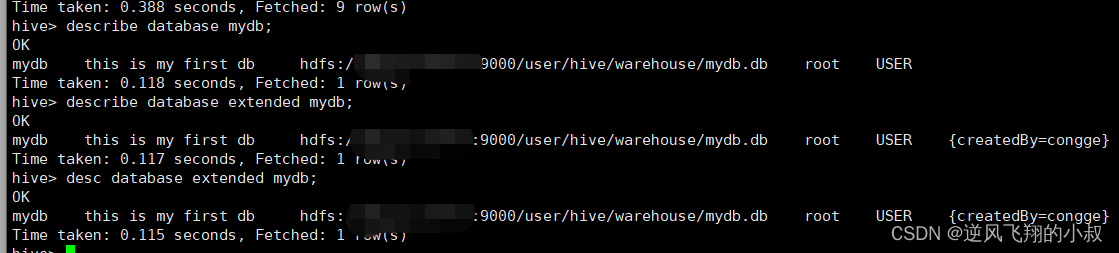
切换数据库
use 数据库名称;
删除数据库
语法
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
默认情况下,如果待删除的数据库下面有表的情况下,直接执行drop命令时会失败,其实是hive对数据库的一种保护操作,如下,假如my_db下面创建一张表,此时直接执行删除,会报错;
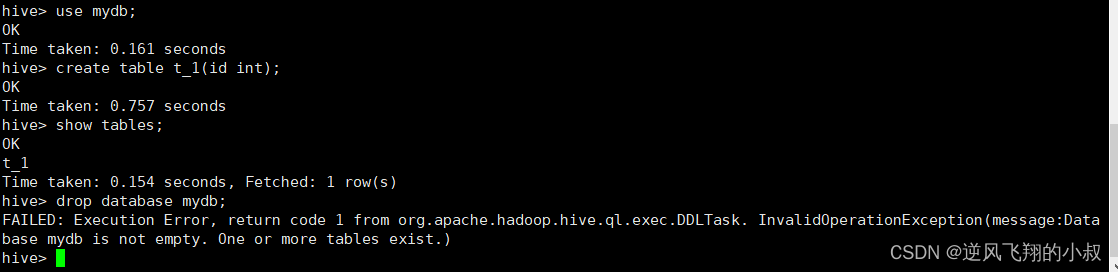
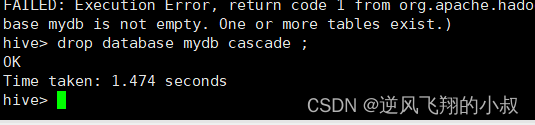
当然如果没有表的话就可以直接删除成功了,但是在存在表的情况下仍然要删除,就可以在语句后加上CASCADE关键字;
drop database mydb cascade ;
执行效果
修改数据库
数据库的修改主要是更改与Hive中的数据库关联的元数据;
更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER USER user;
更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
四、数据表table操作
4.1 整体概述
1、Hive中针对表的DDL操作可以说是DDL中的核心操作,包括建表、修改表、删除表、描述表元数据信息;
2、其中以建表语句为核心中的核心,详见Hive DDL建表语句;
3、可以说表的定义是否成功直接影响着数据能够成功映射,进而影响是否可以顺利的使用Hive开展数据分析;
4、由于Hive建表之后加载映射数据很快,实际中如果建表有问题,可以不用修改,直接删除重建;
4.2 操作演示
创建表
见之前的DDL的一篇:hive ddl操作
删除表
DROP TABLE [IF EXISTS] table_name [PURGE]; -- (Note: PURGE available in Hive 0.14.0 and later)
执行drop table 删除该表的元数据和数据
- 如果已配置垃圾桶且未指定PURGE,则该表对应的数据实际上将移动到HDFS垃圾桶,而元数据完全丢失。 删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据;
- 如果指定了PURGE,则表数据跳过HDFS垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据;
从表中删除所有行
TRUNCATE [TABLE] table_name;
可以简单理解为清空表的所有数据但是保留表的元数据结构,如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。
查询指定表的元数据信息
describe formatted test.t_2;
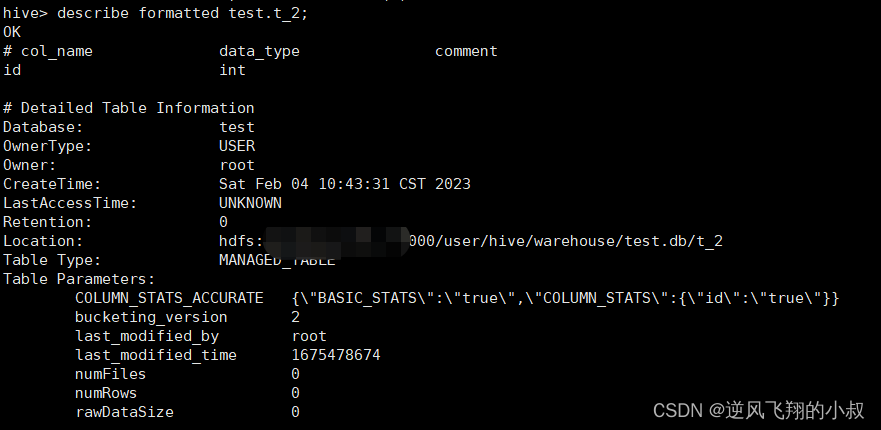
修改表操作
--1、更改表名
ALTER TABLE table_name RENAME TO new_table_name;--2、更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );--更改表注释
ALTER TABLE student SET TBLPROPERTIES ('comment' = "new comment for student table");--3、更改SerDe属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',');--移除SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );--4、更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行
ALTER TABLE table_name SET FILEFORMAT file_format;--5、更改表的存储位置路径
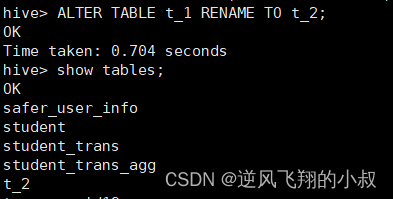
ALTER TABLE table_name SET LOCATION "new location";比如将t_1表改为t_2;
ALTER TABLE table_name RENAME TO new_table_name;
修改表字段操作
修改数据表中的字段相关的操作也是日常DDL中的重要操作,下面以一个表为例进行操作演示
创建一个表
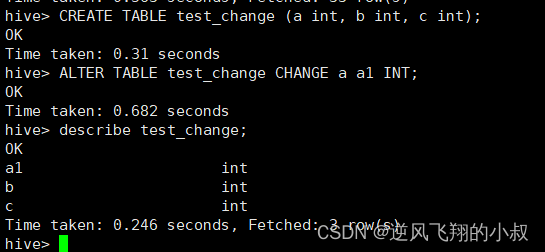
CREATE TABLE test_change (a int, b int, c int);

修改字段名称
ALTER TABLE test_change CHANGE a a1 INT;
修改字段名称和类型
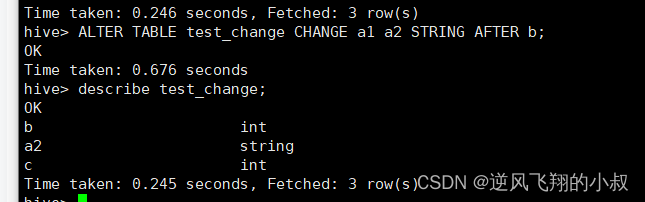
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
修改字段名称并将字段位置提前
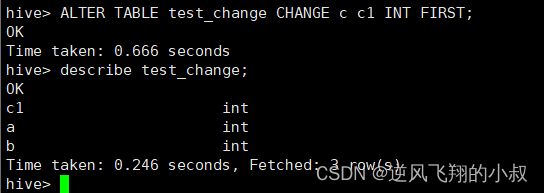
ALTER TABLE test_change CHANGE c c1 INT FIRST;
给字段补充注释
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
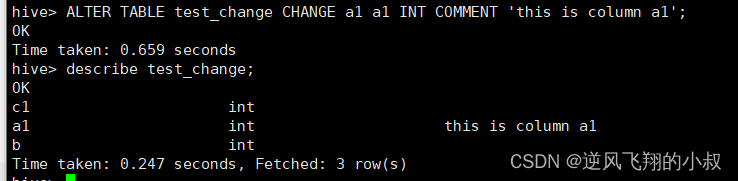
添加/替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type,...);
- 使用ADD COLUMNS,您可以将新列添加到现有列的末尾但在分区列之前;
- REPLACE COLUMNS 将删除所有现有列,并添加新的列集;
4.3 分区表DDL相关操作
在之前的学习中了解到,hive中还有一种分区表,有必要对分区表相关的DDL做一下补充说明
Hive中针对分区Partition的操作主要包括:增加分区、删除分区、重命名分区、修复分区、修改分区
1)增加分区概述
- ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询时将不会返回结果;
- 因此需要保证增加的分区位置路径下,数据已经存在,或者增加完分区之后导入分区数据;
接下来通过实际的操作演示一下
2)添加分区操作演示
创建表手动加载分区数据
drop table if exists t_user_province;
create table t_user_province (num int,name string,sex string,age int,dept string) partitioned by (province string);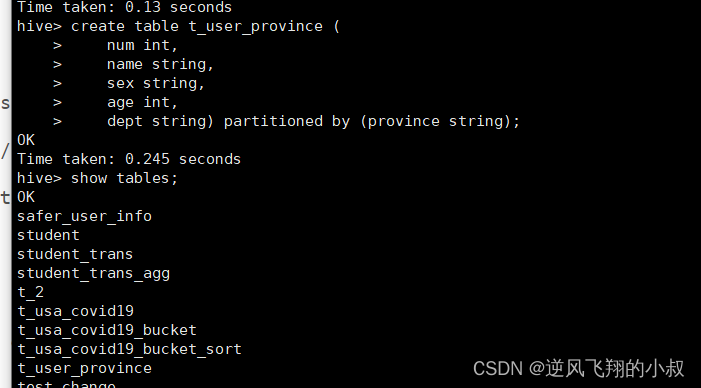
给t_user_province表加载数据
load data local inpath '/usr/local/soft/hivedata/students.txt' into table t_user_province partition(province ="SH");

执行完成后可以在hdfs文件目录下看到一个分区的目录
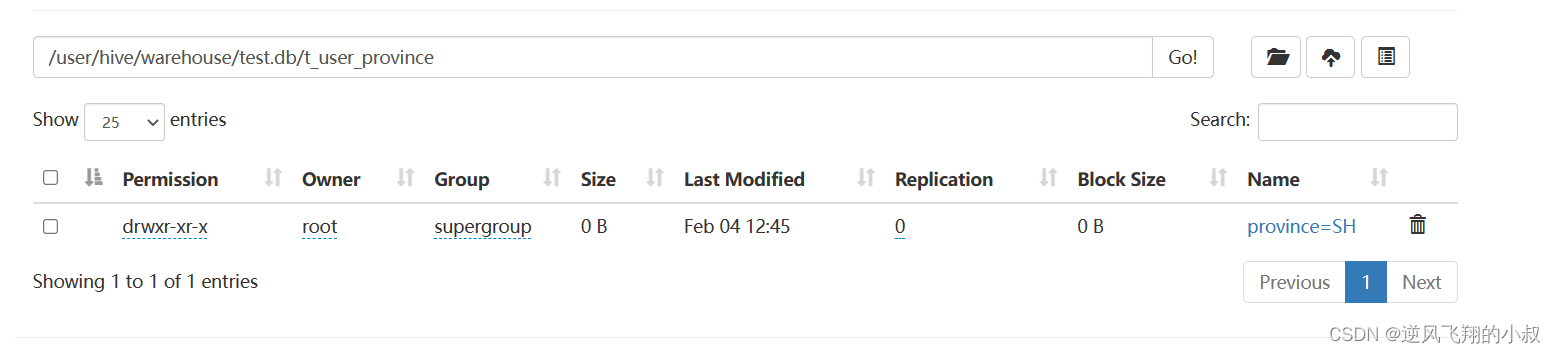
添加一个分区
ALTER TABLE t_user_province ADD PARTITION (province='BJ') location '/user/hive/warehouse/test.db/t_user_province/province=BJ';

执行完成后可以在hdfs文件目录下看到一个新的分区目录

最后,还必须自己把数据加载到增加的分区中 hive不会帮你添加;
此外还支持一次添加多个分区,具体语法
ALTER TABLE table_name ADD PARTITION (dt='2022-08-08', country='us') location '/path/to/us/part220808'
PARTITION (dt='2022-08-09', country='us') location '/path/to/us/part220809';
3)重命名分区
语法
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
ALTER TABLE table_name PARTITION (dt='2022-08-09') RENAME TO PARTITION (dt='20220909');
4)删除分区
删除表的分区,将删除该分区的数据和元数据
删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2022-08-08', country='us');
直接删除数据 不进垃圾桶
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2022-08-08', country='us') PURGE;
5)修改分区
更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET FILEFORMAT file_format;
更改分区位置
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET LOCATION "new location";
6)分区修复
背景:
Hive将每个表的分区列表信息存储在其metastore中。但是,如果将新分区直接添加到HDFS(例如通过使用hadoop fs -put命令)或从HDFS中直接删除分区文件夹,则除非用户ALTER TABLE table_name ADD/DROP PARTITION在每个新添加的分区上运行命令,否则metastore(也就是Hive)将不会意识到分区信息的这些更改。
MSCK是metastore check的缩写,表示元数据检查操作,可用于元数据的修复,语法如下:
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
关于MSCK的几点说明
- MSCK默认行为ADD PARTITIONS,使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到metastore;
- DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息;
- SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS;
- 如果存在大量未跟踪的分区,则可以批量运行MSCK REPAIR TABLE,以避免OOME(内存不足错误);
下面看一个案例的具体的操作演示
- 创建一张分区表,直接使用HDFS命令在表文件夹下创建分区文件夹并上传数据,此时在Hive中查询是无法显示表数据的,因为metastore中没有记录,使用MSCK ADD PARTITIONS进行修复;
- 针对分区表,直接使用HDFS命令删除分区文件夹,此时在Hive中查询显示分区还在,因为metastore中还没有被删除,使用MSCK DROP PARTITIONS进行修复;
4.4 案例一:直接通过HDFS创建分区并加载数据
创建分区表
create table t_all_hero_part_msck(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string
) partitioned by (role string)row format delimitedfields terminated by "\\t";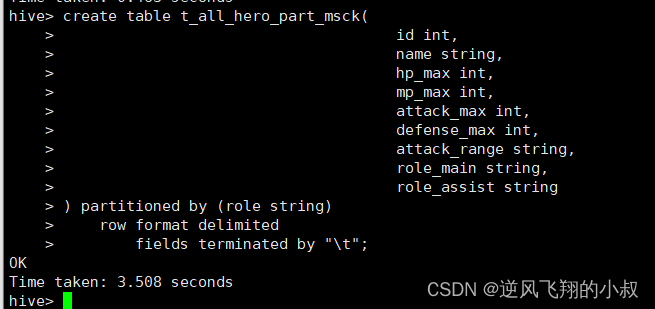
在linux上,使用HDFS命令创建分区文件夹
hdfs dfs -mkdir -p /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou
hdfs dfs -mkdir -p /user/hive/warehouse/test.db/t_all_hero_part_msck/role=tanke
执行完成后效果如下,这个操作就是说,直接通过hdfs命令创建分区,对于hive的底层来说是感知不到的;
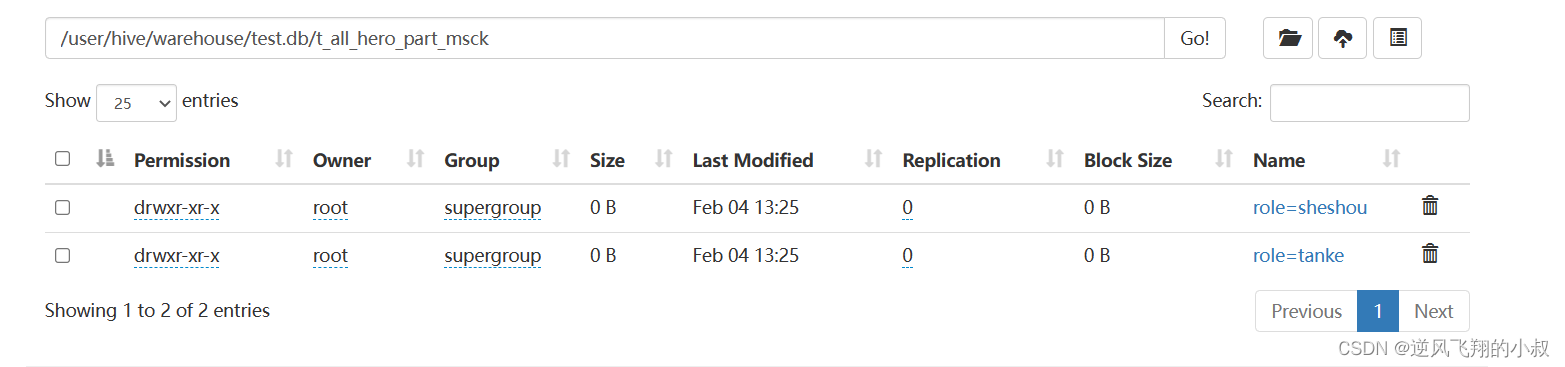
把数据文件上传到对应的分区文件夹下
hdfs dfs -put ./archer.txt /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou
hdfs dfs -put ./tank.txt /user/hive/warehouse/test.db/t_all_hero_part_msck/role=tanke执行上传

上传完毕后,hdfs的分区表下也加载了对应的数据文件

查询分区表数据
select * from t_all_hero_part_msck;
查询发现表中并没有数据,这就进一步说明,直接通过hdfs命令操作,对于hive来说是无法感知到数据变化的;

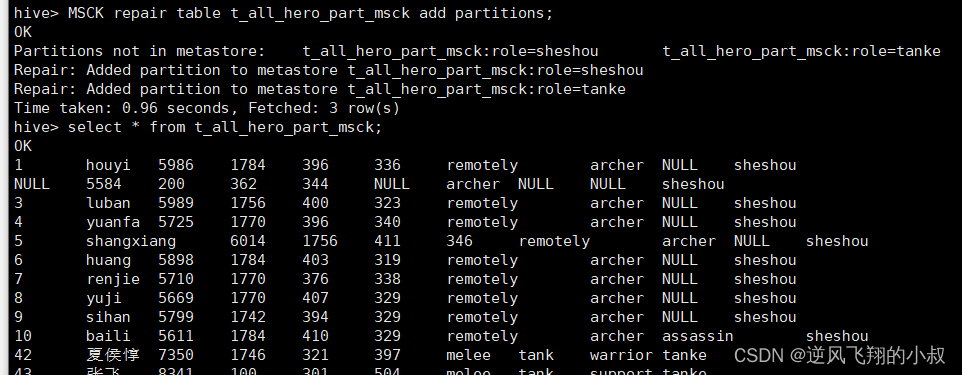
使用MSCK命令进行修复
add partitions可以不写 因为默认就是增加分区
MSCK repair table t_all_hero_part_msck add partitions;
执行完上述的命令后再次查询数据表,发现就有数据了;
4.5 案例二:直接通过HDFS删除分区表某个分区文件夹
删除分区表的某个分区文件夹
hdfs dfs -rm -r /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou

执行完成检查hdfs分区目录已经被删除
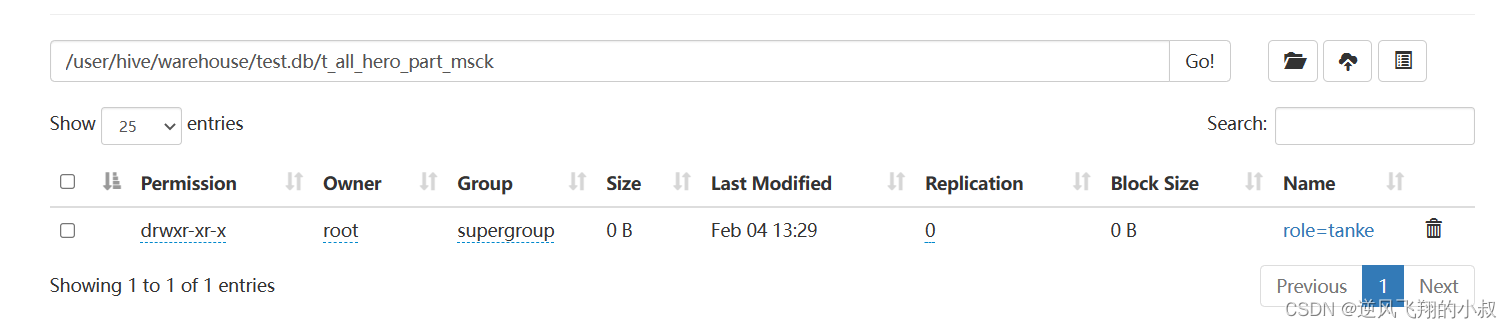
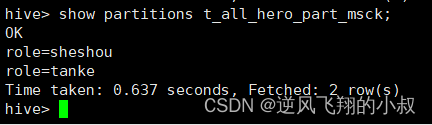
查询数据表数据
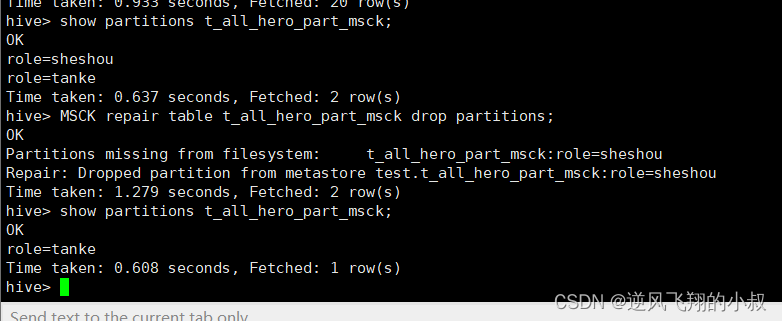
show partitions t_all_hero_part_msck;
查询结果发现分区的信息仍然还在,这是因为hive的元数据信息还没有删除 ,也就是说hive并没有感知到变化;
使用MSCK命令进行修复
MSCK repair table t_all_hero_part_msck drop partitions;
执行修复命令之后,再次检查分区信息,此时分区就只剩下一个了;