图嵌入 DeepWalk

文章目录
- 图表示学习-图嵌入 DeepWalk
-
- 1 图嵌入
- 2 随机游走-Random walks
- 3 DeepWalk
-
- 3.1 Hierarchical Softmax
-
- 3.1.1 哈夫曼树
- 3.1.2 Logistic Regression
- 3.1.3 Softmax 回归
- 3.1.4 Hierarchical Softmax
- 3.2 模型训练
图表示学习-图嵌入 DeepWalk
1 图嵌入
为什么要将节点映射为 d 维的实向量(嵌入到 d 维的空间)?
为了将节点进行数学表示,以度量节点间的相似度,有了节点对应的向量,才可以进行节点分类、连接预测等任务(为下游各种任务做准备)
2 随机游走-Random walks
算法的目标:将节点编码为向量,使得节点所表示的 d 维向量间尽可能的相似
-
编码器 ENC(v):将节点映射为向量(本文中为 DeepWalk)
-
相似度函数:similarity(v1,v2)similarity(v_1, v_2)similarity(v1,v2)
-
解码器 DEC:根据两个节点向量计算其相似度
3 DeepWalk
论文地址:https://arxiv.org/pdf/1403.6652.pdf
由于图的节点往往非常的多,经过 one-hot 编码之后得到的节点向量往往非常地大,且向量每个元素的值为 0 和 1。通过神经网络训练得到的节点向量是低维的、元素值是实数(连续值),且可进行相似度的度量,可以反应节点间的关系
随机得到游走序列,将随机游走序列视为句子(中心词+上下文),使用 Skip-gram 来训练节点向量!


使用 Hierarchical Softmax 计算输出的每个节点的概率
3.1 Hierarchical Softmax
3.1.1 哈夫曼树
-
带权路径长度最短的二叉树
-
可以使用哈夫曼编码
-
频率相关:节点出现频率越高,其越靠近根节点
-
唯一编码、且编码长度减小(压缩编码)
-
3.1.2 Logistic Regression
y=Sigmoid(wx+b)y = Sigmoid(wx+b) y=Sigmoid(wx+b)
LR 是传统线性回归 y=wx+by=wx+by=wx+b 与 SigmoidSigmoidSigmoid 变换结合,将连续值转化为0到1之间的类概率值,并设定分类阈值如 0.5,来完成二分类任务
3.1.3 Softmax 回归
神经网络的多分类,最基本的是使用Softmax回归
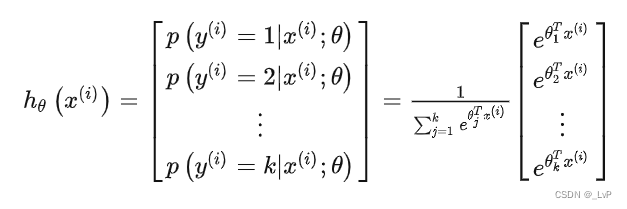
但是 Softmax 回归需要构建一个每个词的全连接层,即需要对词表中的每个词均计算一遍输出值并归一化,再找到输出概率最大的词。当词表非常大的时候,Softmax 回归将会非常耗时
传统 ML 中的多分类:用二分类解决多分类问题,这种方法要训练多个模型,对于神经网络这种庞大参数的模型来说无疑是行不通的
用二分类解决多分类问题:OvR (one versus rest)、OvO (one versus one)
OvO一对一:将 n 个类别两两配对,产生n∗(n−1)2\\frac{n*(n-1)}{2}2n∗(n−1)个二分类任务进行训练,最终把预测出来次数最多的类别作为最终的分类类别
OvR一对其他:每次将一个类作为正例,别的类作为反例,共训练 n 个分类器。预测时,用 n 个分类器预测,若只得到一个预测值是正例,则取此为最终预测类别;若多个分类器得到正例,则对比它们的置信度(如 LR 中得到的类概率值,来比较它们谁最大)
3.1.4 Hierarchical Softmax
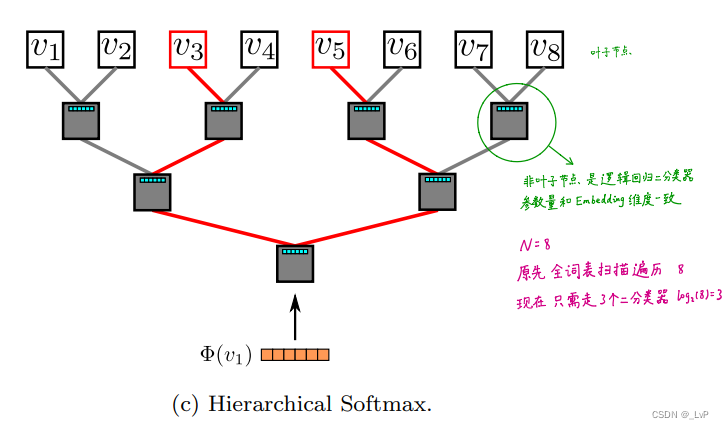
分层 Softmax 如图,构建一颗二叉树,其中每个叶子节点对应一个词,非叶子结点是一个 LR 分类器,LR 在这里的应用就是判断在当前节点要走左子树还是右子树,其输出的值在当前节点往左走或右走的概率。

)]
由于此树从根节点的分类器到叶子节点的编码是唯一的(路径是唯一的),路径上每个 LR 预测概率之积,就可以视为在当前输入词的词向量下,得到的输出周围词(skip-gram根据中心词预测上下文的词)的词向量条件概率
分层 Softmax 比 Softmax 牛的地方:设窗口为2,训练的每轮迭代,Softmax 都得把词表遍历一遍,找到预测概率最大的俩词,而分层 Softmax 运行的次数是路径长度之和(从根节点到叶子节点经过的节点数之和),分层Softmax 运行的时间复杂度会大大减小。
3.2 模型训练
更新两套权重
-
n 个节点的 v 维节点向量
-
n-1 个 LR,每个 LR 的输入特征向量的维度是 v
为什么是 n-1 个 LR,因为二叉树性质 n0=n2−1n_0 = n_2 - 1n0=n2−1,n 个节点对应其叶子节点,所以飞叶子节点的个数即 LR 的个数是 n-1