lamda表达式

lamda表达式
-
- 一. lamda表达式的特性
- 二.常用匿名函数式接口
-
- 2.1 Supplier接口
- 2.2 Consumer接口
- 2.3 Predicate接口
- 2.4 Function接口
- 2.5 BiFunction接口
- 三.stream流传递先后顺序
- 四.表达式
-
- 4.1 ForEach
- 4.2 Collect
- 4.3 Filter
- 4.4 Map
- 4.5 MapToInt
- 4.6 Distinct
- 4.7 Sorted
- 4.8 groupingBy
- 4.9 FindFirst
- 4.10 Reduce
- 4.11 Peek
- 4.12 Limit
- 4.13 Max,Min
- 4.14 partitioningBy
- 末尾
一. lamda表达式的特性
1.匿名函数
与匿名内部类的区别:Lamda对应的接口只能有一个方法。匿名内部类对应的接口可以有多个方法
2.可传递性
可传递性理解:Lambda表达式传递给其他的函数,它当做参数例如:list.stream().map(s -> Integer.valueOf(s)).distinct().collect(Collectors.toList());
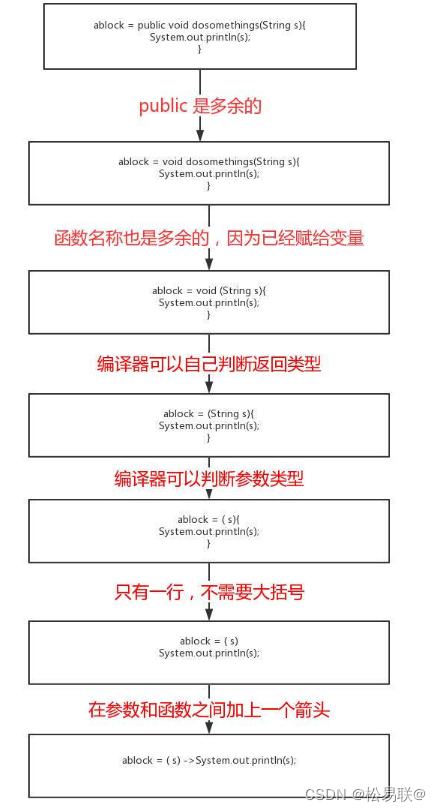
lamda表达式的格式
三要素:形式参数,箭头,代码块
形如:(形参)->代码块
形参如果多个参数,参数之间逗号隔开,如果没有参数,留空括号,不用留空格
-> 一定的是英文,固定写法,表示执行
代码块:具体要做的事情
使用前提:使用接口:接口当中有且只有一个抽象方法
二.常用匿名函数式接口
2.1 Supplier接口
作用:Supplier接口是对象实例的提供者,定义了一个名叫get的抽象方法,它没有任何入参,并返回一个泛型T对象
源码如下:
package java.util.function;@FunctionalInterface //注释:@FunctionalInterface写不写都可以。// 此注解主要用于编译级错误检查:当接口不符合函数式接口定义的时候,编译器会报错。
public interface Supplier<T> {T get();
}举例:
/* 口罩类*/
public class Mask {public Mask(String brand, String type) {this.brand = brand;this.type = type;}/* 品牌*/private String brand;/* 类型*/private String type;public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public String getType() {return type;}public void setType(String type) {this.type = type;}
}//创建实例与获取对象
Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建实例
Mask mask = supplier.get(); ---获取对象2.2 Consumer接口
Consumer接口是一个类似消费者的接口,定义了一个名叫accept的抽象方法,它的入参是一个泛型T对象,没有任何返回(void)
源码:
package java.util.function;@FunctionalInterface
public interface Consumer<T> {void accept(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建supplier实例
Consumer<Mask> consumer = (Mask mask) -> {System.out.println("Brand: " + mask.getBrand() + ", Type: " + mask.getType());
}; ----创建Consume实例
consumer.accept(supplier.get()); ---consume实例消费supplier实例
2.3 Predicate接口
Predicate接口是判断是与否的接口,定义了一个名叫test的抽象方法,它的入参是一个泛型T对象,并返回一个boolean类型
源码:
package java.util.function;@FunctionalInterface
public interface Predicate<T> {boolean test(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建supplier实例
Predicate<Mask> n95 = (Mask mask) -> "N95".equals(mask.getType()); ---用于判断是否为N95口罩
Predicate<Mask> kn95 = (Mask mask) -> "KN95".equals(mask.getType());
System.out.println("是否为N95口罩:" + n95.test(supplier.get()));
System.out.println("是否为KN95口罩:" + kn95.test(supplier.get()));2.4 Function接口
Function接口是对实例进行处理转换的接口,定义了一个名叫apply的抽象方法,它的入参是一个泛型T对象,并返回一个泛型R对象
源码:
package java.util.function;@FunctionalInterface
public interface Function<T, R> {R apply(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建一个supplier对象
Function<Mask, String> brand = (Mask mask) -> mask.getBrand(); ---Function对象获取Mask 转换为String 类型的值
Function<Mask, String> type = (Mask mask) -> mask.getType();
System.out.println("口罩品牌:" + brand.apply(supplier.get()));
System.out.println("口罩类型:" + type.apply(supplier.get()));
2.5 BiFunction接口
Function接口的入参只有一个泛型对象,JDK还为我们提供了两个泛型对象入参的接口:BiFunction接口
源码:
package java.util.function;@FunctionalInterface
public interface BiFunction<T, U, R> {R apply(T t, U u);
}//创建BiFunction实例---实现Mask对象
BiFunction<String,String,Mask> biFunction = (String brand, String type) -> new Mask(brand, type);
Mask mask = biFunction.apply("3M", "N95"); //赋值
System.out.println("Brand: " + mask.getBrand() + ", Type: " + mask.getType());三.stream流传递先后顺序
允许你以声明式的方式处理数据集合,可以把 它看作是遍历数据集的高级迭代器。此外与 stream 与 lambada 表达示结合后 编码效率与大大提高,并且可读性更强。
流更偏向于数据处理和计算,比如 filter、map、find、sort 等。简单来说,我们通过一个集合的 stream 方法获取一个流,然后对流进行一 系列流操作,最后再构建成我们需要的数据集合

这里分为 3 步 :
获得流—>中间操作---->终端操作
中间操作
往往对数据进行筛选
filter:过滤流中的某些元素,
sorted(): 自然排序,流中元素需实现 Comparable 接口
distinct: 去除重复元素
limit(n): 获取 n 个元素
skip(n): 跳过 n 元素,配合 limit(n)可实现分页
map(): 将其映射成一个新的元素
终端操作
往往对结果集进行处理
forEach: 遍历流中的元素
toArray:将流中的元素倒入一个数组
Min:返回流中元素最小值 Max:返回流中元素最大值
count:返回流中元素的总个数
Reduce:所有元素求和
anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足条件则返回 true,否则返回
falseallMatch:接收一个 Predicate 函数,当流中每个元素都符合条件时才返回 true,否则返回 false
findFirst:返回流中第一个元素
collect:将流中的元素倒入一个集合,Collection 或 Map
四.表达式
4.1 ForEach
集合的遍历
public void testForEach(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.forEach(s-> System.out.println(s));}
4.2 Collect
将操作后的对象转化为新的对象
public void testCollect(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};//转换为新的listList newList = list.stream().map(s -> Integer.valueOf(s)).collect(Collectors.toList());}
4.3 Filter
Filter 为过滤的意思,只要满足 Filter 表达式的数据就可以留下来,不满足的数据被过滤掉
public void testFilter() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}}; list.stream()// 过滤掉我们希望留下来的值// 表示我们希望字符串是 1 能留下来// 其他的过滤掉.filter(str -> "1".equals(str)).collect(Collectors.toList());}
4.4 Map
map 方法可以让我们进行一些流的转化,比如原来流中的元素是 A,通过 map 操作,可以使返回的流中的元素是 B
public void testMap() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};//通过 map 方法list中元素转化成 小写List<String> strLowerList = list.stream().map(str -> str.toLowerCase()).collect(Collectors.toList());}
4.5 MapToInt
mapToInt 方法的功能和 map 方法一样,只不过 mapToInt 返回的结果已经没有泛型,已经明确是 int 类型的流
public void testMapToInt() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().mapToInt(s->Integer.valueOf(s))// 一定要有 mapToObj,因为 mapToInt 返回的是 IntStream,因为已经确定是 int 类型了// 所有没有泛型的,而 Collectors.toList() 强制要求有泛型的流,所以需要使用 mapToObj// 方法返回有泛型的流.mapToObj(s->s).collect(Collectors.toList());list.stream().mapToDouble(s->Double.valueOf(s))// DoubleStream/IntStream 有许多 sum(求和)、min(求最小值)、max(求最大值)、average(求平均值)等方法.sum();}
4.6 Distinct
distinct 方法有去重的功能
public void testDistinct(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().map(s -> Integer.valueOf(s)).distinct().collect(Collectors.toList());}
4.7 Sorted
Sorted 方法提供了排序的功能,并且允许我们自定义排序
public void testSorted(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s))// 等同于 .sorted(Comparator.naturalOrder()) 自然排序.sorted().collect(Collectors.toList());// 自定义排序器list.stream().map(s -> Integer.valueOf(s))// 反自然排序.sorted(Comparator.reverseOrder()).collect(Collectors.toList());}
4.8 groupingBy
groupingBy 是能够根据字段进行分组,toMap 是把 List 的数据格式转化成 Map 的格式
public void testGroupBy(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};Map<String, List<String>> strList = list.stream().collect(Collectors.groupingBy(s -> {if("2".equals(s)) {return "2";}else {return "1";}}));}
4.9 FindFirst
findFirst 表示匹配到第一个满足条件的值就返回
public void testFindFirst(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().filter(s->"2".equals(s)).findFirst().get();// 防止空指针list.stream().filter(s->"2".equals(s)).findFirst()// orElse 表示如果 findFirst 返回 null 的话,就返回 orElse 里的内容.orElse("3");Optional<String> str= list.stream().filter(s->"2".equals(s)).findFirst();// isPresent 为 true 的话,表示 value != nullif(str.isPresent()){return;}}
4.10 Reduce
reduce 方法允许我们在循环里面叠加计算值
public void testReduce(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s))// s1 和 s2 表示循环中的前后两个数.reduce((s1,s2) -> s1+s2).orElse(0);list.stream().map(s -> Integer.valueOf(s))// 第一个参数表示基数,会从 100 开始加.reduce(100,(s1,s2) -> s1+s2);}
4.11 Peek
peek 方法很简单,我们在 peek 方法里面做任意没有返回值的事情,比如打印日志
public void testPeek(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s)).peek(s -> System.out.println(s)).collect(Collectors.toList());}
4.12 Limit
limit 方法会限制输出值个数,入参是限制的个数大小
public void testLimit(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s)).limit(2L).collect(Collectors.toList());}
4.13 Max,Min
通过max、min方法,可以获取集合中最大、最小的对象
public void testMaxMin(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().max(Comparator.comparing(s -> Integer.valueOf(s))).get();list.stream().min(Comparator.comparing(s -> Integer.valueOf(s))).get();}
4.14 partitioningBy
partitioningBy要求传入一个Predicate,会按照满足条件和不满足条件分成两组,得到的结果是Map<Boolean, List>结构
Map<Boolean, List<Person>> personsByAge = persons.stream().collect(Collectors.partitioningBy(p -> p.getAge() > 18));
System.out.println(JSON.toJSONString(personsByAge));
末尾
lamda不带类型的原因