Pytorch入门

Pytorch入门
本次学习代码
1_传统深度学习
传统深度学习使用的是全连接网络。全连接层的输入数据只能是二维的。
1.1_实现流程
读取数据——>处理数据——>构建神经网络模型——>定义网络模型(前向传播:定义模型;后向传播:定义损失函数、定义优化器)——>训练模型(输入数据得到输出、计算损失、计算梯度、调整权值)——>根据训练好的模型进行测试
线性回归示例代码块:
import matplotlib.pyplot as plt
from torch import nn,optim
from torch.autograd import Variable
import torch
import numpy as np
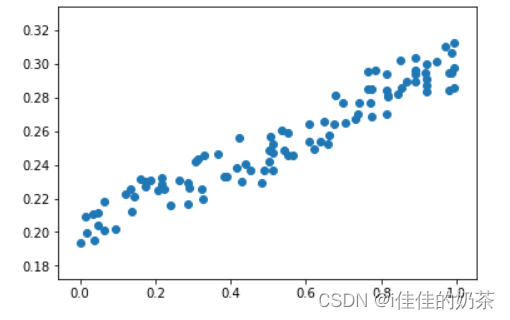
x_data = np.random.rand(100)# 生成100个随机数
noise = np.random.normal(0,0.01,x_data.shape)# 生成指定均值和标准差的高斯分布(正态分布)样本
y_data = x_data*0.1 + 0.2 + noiseplt.scatter(x_data,y_data)#话散点图
plt.show()#显示
x_data = x_data.reshape(100,1)#reshape(a,b)函数改变xdata的维度为a行b列
y_data = y_data.reshape(-1,1)#-1代表自动匹配data的原本行数
#把numpy数据变成tensor
x_data = torch.FloatTensor(x_data)
y_data = torch.FloatTensor(x_data)
input = Variable(x_data)
target = Variable(y_data)
# 构建神经网络模型
# nn.Module是PyTorch中所有神经网络模块的基类
class LinearRegression(nn.Module):#定义网络结构,一般将网络中具有可学习参数的层放在__init__()中def __init__(self):# 初始化nn.modulesuper(LinearRegression, self).__init__()self.fc = nn.Linear(1, 1)#一个输入对应一个输出# 定义网络计算,输入x,根据nn.Linear自动生成的参数计算outdef forward(self, x):out = self.fc(x)return out
# 定义模型
model = LinearRegression()
# 定义损失函数
mse_loss = nn.MSELoss()
# 定义优化器,用于调整权值,这里使用的是梯度下降法,第一个参数是模型的参数,第二个参数是学习率
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 定义好模型后可以查看一下这个模型都有哪些参数
for name, parameters in model.named_parameters():print('name:{}, param:{}'.format(name, parameters))

# 开始模型的训练
for i in range(1001):out = model(input)# 计算lossloss = mse_loss(out, target)# 梯度清零optimizer.zero_grad()# 计算梯度loss.backward()# 调整权值optimizer.step()if i%200 == 0:print(i,loss.item())

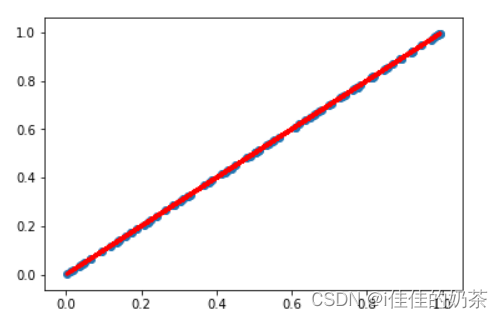
# 测试
y_pred = model(input)
plt.scatter(x_data, y_data)
plt.plot(x_data, y_pred.data.numpy(), 'r-', lw = 3)
plt.show()
1.2_nn.module
nn.Module是PyTorch中所有神经网络模块的基类,包括层(layers)、损失函数(loss
functions)、优化器(optimizers)等。继承自nn.Module类的子类可以具有以下特性:
- 参数信息:我们可以使用
model.parameters()方法获取模型中的可学习参数列表。PyTorch会自动跟踪模型中所有需要梯度进行更新的参数,并将它们加入到模型的参数列表中。- 前向计算逻辑:子类必须实现
forward方法,该方法实现了模型的前向计算逻辑。在这个方法中,我们可以定义模型的计算流程和各种操作。- 后向传播逻辑(可选):如果我们需要自定义模型,例如实现自己的损失函数或层,我们可以通过实现
backward方法来定义梯度计算逻辑。通常情况下,PyTorch提供的默认实现就足够了。
1.3_过拟合
过拟合现象:通俗的来讲就是网络模型在训练样本上可以获得很好的结果,但是在测试集样本得到的效果不是很好,不是很好的泛化模型。有两个三个解决办法分别是early stopping、dropout神经元、正则化。
- early stopping
一般的做法是记录到目前为止最好的validation accuracy,当连续10个Epoch没有达到最佳accuracy时,则可以认为accuracy不再提高了。
- Dropout
即设置一定比例的神经元不生效,减少权值个数。
- 正则化
这个没听明白。
1.4_优化器
优化器根据损失结果进行权值的调整,经典的优化方法为梯度下降法即SGD优化器。
- SGD
下降速度慢,并且有鞍点问题
- Adam
常用的优化器
- Momentum
加入惯性的优化器,但是有“冲过头”的问题
- Nag
Momentum优化,在走过头前提前预知
- 其他优化器
Adadelta、Adagrad、Adamax、AdamW、ASGD、LBFGS、RMSprop、Rprop、SparseAdam
2_卷积神经网络
- 卷积神经网络出现的现实需要
传统神经网络处理图像时有以下问题:权值太多计算量太大、权值太多需要大量样本训练。
- 卷积层和隐藏层概念
在神经网络中卷积是最常见的操作,通常情况下它应用在神经网络的Input层后面,所以我们多数情况下称这一层为卷积层或隐藏层,这里提一句什么是隐藏层,在神经网络中有输入层和输出层,这两层对于外界是可见的,并且它接收来自外界的输入或输出到外界里去,当然一个完整的神经网络不可能只有输入层和输出层,就以CNN卷积神经网络来说当图像输入到输入层之后会被传递给下一层做特征提取下一层一般是卷积层,随后卷积层会传递给池化层,在由池化层传递给全连接层,这三层对于外界来说是不可见的,它不能直接接收外界的输入或直接输出到外界,所以通常情况下我们称这些为隐藏层。
卷积的作用就是为了将Input的数据做一次特征提取。
- 卷积层数据
卷积层的输入数据必须是四维的如[a, b, c, d]:表示每批有a个图片,每个图片有b个通道(如黑白就只有一个通道),图片尺寸为c*d。
若想卷积之后图像尺寸不变,需要满足如下要求:
| 卷积核尺寸 | padding边缘圈数 |
|---|---|
| 3 | 1 |
| 5 | 2 |
| 7 | 3 |
2.1_相关技术
2.1.1_神经元
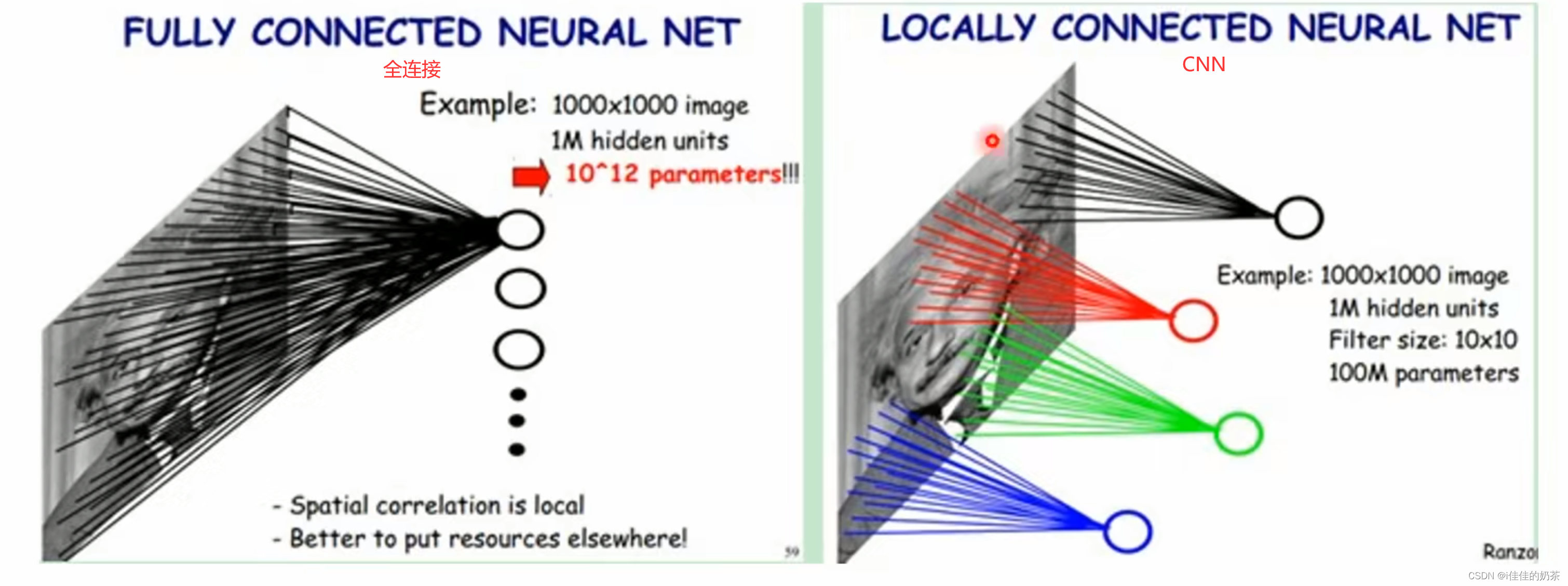
卷积神经网络通过局部感受野和权值共享减少了神经网络需要训练的参数个数
- 局部感受野
如上图所示,全连接神经网络是每个神经元都要和整个输入数据有一组权值,而CNN则是每个神经元负责某一部分并且只和此部分数据连接(有一小组权值)即可
- 权值共享
即每一个神经元连接的权值都一样,如上图每个神经元(红色、蓝色、绿色)的权值都一样
2.1.2_卷积
卷积核/滤波器:
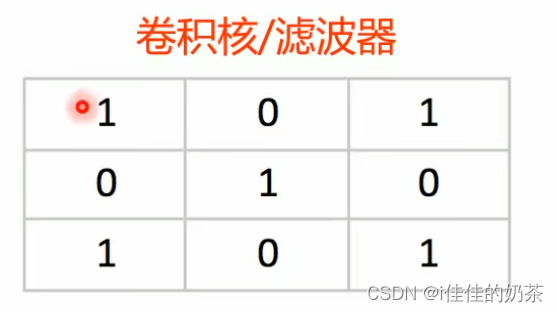
计算方法不再赘述,有需要的可以查看此链接卷积计算
若想卷积之后图像尺寸不变,需要满足如下要求:
| 卷积核尺寸 | padding边缘圈数 |
|---|---|
| 3 | 1 |
| 5 | 2 |
| 7 | 3 |
2.1.3_Pooling池化
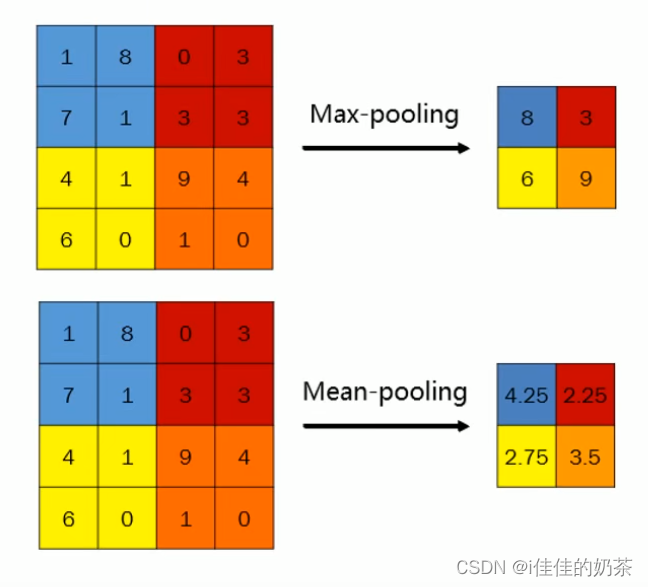
- 池化的三种常用方式:
max-pooling(最大池化)、mean-pooling(平均池化)、stochastic pooling(随机池化),其中最大池化使用的最频繁。
- 池化的一些作用
进行特征的进一步提取、有一定的平移不变性功能(即同一个物体在图片的不同地方能够识别为同一个物体)。
2.1.4_Padding
分为两种方式:SAME PADDING和VALID PADDING。
- SAME PADDING
做完卷积会在图像矩阵的最外层补0。
- VALID PADDING
卷积的时候卷积核覆盖的区域不会超出图像最边缘。
2.2_模型介绍
2.2.1_LwNet-5介绍
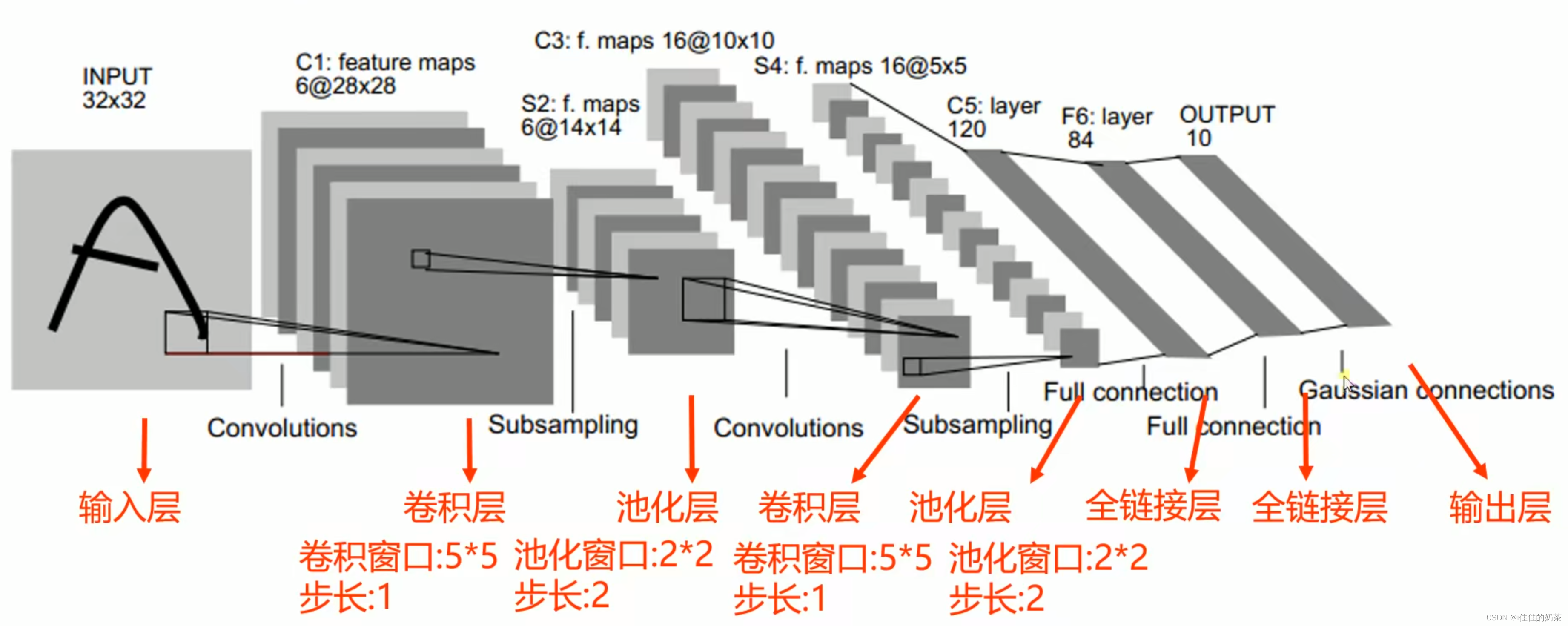
LeNET-5是最早的卷积神经网络之一,曾广泛用于美国。
- 第一层Convolutions卷积层
卷积层的输入数据必须是四维的如[a, b, c, d]:表示每批有a个图片,每个图片有b个通道(如黑白就只有一个通道),图片尺寸为cd。
使用了6个卷积核(使用不同的卷积核以防遗漏特征),分别生成了6个特征图;损失了边缘信息,由于卷积核大小为55,所以特征图大小为28*28.
- 第二层Subsampling池化层
池化窗口为22,所以尺寸变为1414.
- 第三层Convolutions卷积层
第三层卷积层和第一层卷积层有所不同,第三层卷积层和第二层的对象不是一对一的,而是对多个第二层池化结果进行卷积,生成一个卷积结果。
- 第四层全连接层
因为全连接层的输入数据必须是二维的,所以将数据变成二维数据(图中未体现这一步),然后进行全连接,再进行反向传播、权值优化、进行训练(与传统深度学习一样)。
- 第五层全连接层
与传统深度学习一样,是第二个全连接层。

3_pyplot
引入:
import matplotlib.pyplot as plt
3.1_scatter绘制散点图
plt.scatter()是Python中matplotlib库中的一种绘图函数,用于绘制散点图。其语法为:
plt.scatter(x, y, s=None, c=None, marker=None, cmap=None, vmin=None, vmax=None, alpha=None, edgecolors=None, linewidths=None)
其中,参数解释如下:
x:x轴上的数值数组或列表。y:y轴上的数值数组或列表。s:散点的大小,缺省值为20。c:散点的颜色或颜色序列,缺省值为None。marker:散点的标记,缺省值为’o’,即小圆点。cmap:给定颜色映射,缺省值为None。vmin, vmax:标量,用于标定c中颜色的映射范围,如果缺省则以c数组的最大值和最小值为准。alpha:图形的透明度,范围为[0, 1],缺省值为None。edgecolors:散点的边界颜色,缺省值为None。linewidths:散点边界的线宽,确省值为None。
3.2_show显示图形
plt.show()是matplotlib库中的一个函数,用于显示图形。在使用matplotlib库绘制图形时,如果没有调用plt.show()函数,图形将不会显示出来。
4_pytorch中文文档
pytorch中文文档