推荐算法——NCF知识总结代码实现

NCF知识总结代码实现
- 1. NeuralCF 模型的结构
-
- 1.1 回顾CF和MF
- 1.2 NCF 模型结构
- 1.3 NeuralCF 模型的扩展---双塔模型
- 2. NCF代码实现
-
- 2.1 tensorflow
- 2.2 pytorch
NeuralCF:如何用深度学习改造协同过滤?
随着技术的发展,协同过滤相比深度学习模型的弊端就日益显现,因为它是通过直接利用非常稀疏的共现矩阵进行预测的,所以模型的泛化能力非常弱,遇到历史行为非常少的用户,就没法产生准确的推荐结果。
虽然,可以通过矩阵分解算法增强它的泛化能力,但因为矩阵分解是利用非常简单的内积方式来处理用户向量和物品向量的交叉问题的,所以,它的拟合能力也比较弱。
2017 年,新加坡国立的研究者就使用深度学习网络来改进了传统的协同过滤算法,取名 NeuralCF(神经网络协同过滤)。NeuralCF 大大提高了协同过滤算法的泛化能力和拟合能力,让这个经典的推荐算法又重新在深度学习时代焕发生机。
1. NeuralCF 模型的结构
1.1 回顾CF和MF
先来简单回顾一下协同过滤和矩阵分解的原理。协同过滤是利用用户和物品之间的交互行为历史,构建出一个像图左一样的共现矩阵。在共现矩阵的基础上,利用每一行的用户向量相似性,找到相似用户,再利用相似用户喜欢的物品进行推荐。
矩阵分解则进一步加强了协同过滤的泛化能力,它把协同过滤中的共现矩阵分解成了用户矩阵和物品矩阵,从用户矩阵中提取出用户隐向量,从物品矩阵中提取出物品隐向量,再利用它们之间的内积相似性进行推荐排序。
如果用神经网络的思路来理解矩阵分解,它的结构图就是图 2 这样的。

图 2 中的输入层是由用户 ID 和物品 ID 生成的 One-hot 向量,Embedding 层是把 One-hot 向量转化成稠密的 Embedding 向量表达,这部分就是矩阵分解中的用户隐向量和物品隐向量。输出层使用了用户隐向量和物品隐向量的内积作为最终预测得分,之后通过跟目标得分对比,进行反向梯度传播,更新整个网络。
把矩阵分解神经网络化之后,把它跟 Embedding+MLP 以及 Wide&Deep 模型做对比,我们可以一眼看出网络中的薄弱环节:矩阵分解在 Embedding 层之上的操作好像过于简单了,就是直接利用内积得出最终结果。这会导致特征之间还没有充分交叉就直接输出结果,模型会有欠拟合的风险。
1.2 NCF 模型结构
针对矩阵分解的弱点,NeuralCF 对矩阵分解进行了改进,它的结构图是图 3 这样的。

NeuralCF 用一个多层的神经网络替代掉了原来简单的点积操作。这样就可以让用户和物品隐向量之间进行充分的交叉,提高模型整体的拟合能力。
1.3 NeuralCF 模型的扩展—双塔模型
NeuralCF 的模型结构之中,蕴含了一个非常有价值的思想,就是我们可以把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。
这里的用户侧模型结构和物品侧模型结构,可以是简单的 Embedding 层,也可以是复杂的神经网络结构,最后的互操作层可以是简单的点积操作,也可以是比较复杂的 MLP 结构。但只要是这种物品侧模型 + 用户侧模型 + 互操作层的模型结构,我们把它统称为“双塔模型”结构。

对于 NerualCF 来说,它只利用了用户 ID 作为“用户塔”的输入特征,用物品 ID 作为“物品塔”的输入特征。事实上,我们完全可以把其他用户和物品相关的特征也分别放入用户塔和物品塔,让模型能够学到的信息更全面。比如说,YouTube 在构建用于召回层的双塔模型时,就分别在用户侧和物品侧输入了多种不同的特征。
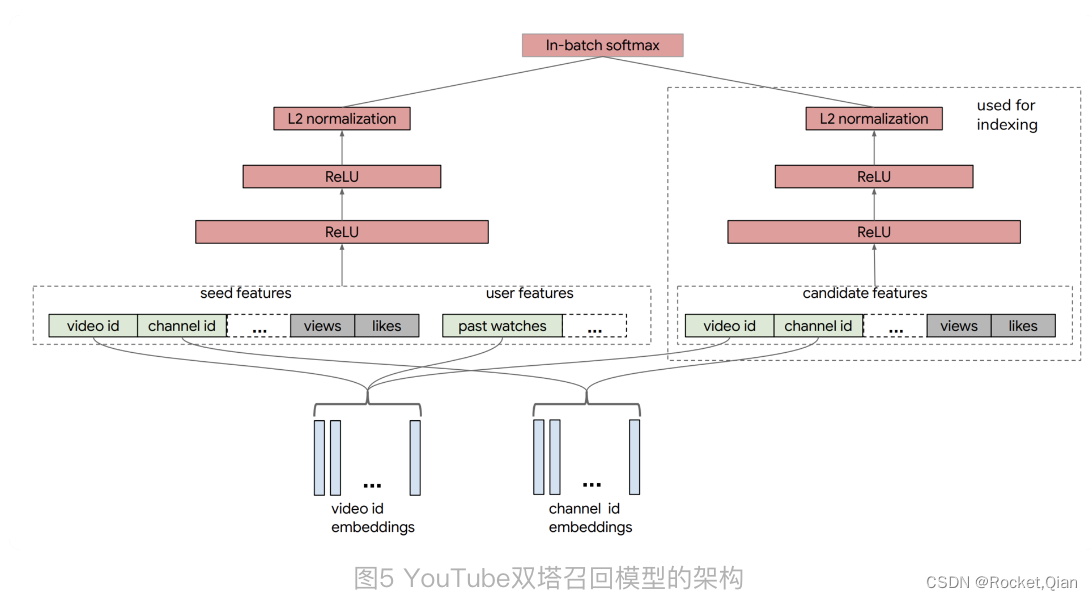
YouTube 召回双塔模型的用户侧特征包括了用户正在观看的视频 ID、频道 ID(图中的 seed features)、该视频的观看数、被喜欢的次数,以及用户历史观看过的视频 ID 等等。物品侧的特征包括了候选视频的 ID、频道 ID、被观看次数、被喜欢次数等等。在经过了多层 ReLU 神经网络的学习之后,双塔模型最终通过 softmax 输出层连接两部分,输出最终预测分数。
这个双塔模型相比Embedding MLP 和 Wide&Deep 有优势:在实际工作中,双塔模型最重要的优势就在于它易上线、易服务。
注意看物品塔和用户塔最顶端的那层神经元,那层神经元的输出其实就是一个全新的物品 Embedding 和用户 Embedding。拿图 4 来说,物品塔的输入特征向量是 x,经过物品塔的一系列变换,生成了向量 u(x),那么这个 u(x) 就是这个物品的 Embedding 向量。同理,v(y) 是用户 y 的 Embedding 向量,这时,我们就可以把 u(x) 和 v(y) 存入特征数据库,这样一来,线上服务的时候,我们只要把 u(x) 和 v(y) 取出来,再对它们做简单的互操作层运算就可以得出最后的模型预估结果了。
所以使用双塔模型,不用把整个模型都部署上线,只需要预存物品塔和用户塔的输出,以及在线上实现互操作层就可以了。如果这个互操作层是点积操作,那么这个实现可以说没有任何难度,这是实际应用中非常容易落地的,这也正是双塔模型在业界巨大的优势所在。
2. NCF代码实现
2.1 tensorflow
NeuralCF模型部分的实现
# neural cf model arch two. only embedding in each tower, then MLP as the interaction layers
def neural_cf_model_1(feature_inputs, item_feature_columns, user_feature_columns, hidden_units):# 物品侧特征层item_tower = tf.keras.layers.DenseFeatures(item_feature_columns)(feature_inputs)# 用户侧特征层user_tower = tf.keras.layers.DenseFeatures(user_feature_columns)(feature_inputs)# 连接层及后续多层神经网络interact_layer = tf.keras.layers.concatenate([item_tower, user_tower])for num_nodes in hidden_units:interact_layer = tf.keras.layers.Dense(num_nodes, activation='relu')(interact_layer)# sigmoid单神经元输出层output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(interact_layer)# 定义keras模型neural_cf_model = tf.keras.Model(feature_inputs, output_layer)return neural_cf_model
代码中定义的生成 NeuralCF 模型的函数,接收了四个输入变量。其中 feature_inputs 代表着所有的模型输入, item_feature_columns 和 user_feature_columns 分别包含了物品侧和用户侧的特征。在训练时,如果只在 item_feature_columns 中放入 movie_id ,在 user_feature_columns 放入 user_id, 就是NeuralCF的经典实现了。
通过 DenseFeatures 层创建好用户侧和物品侧输入层之后,再利用 concatenate 层将二者连接起来,然后输入多层神经网络进行训练。如果想要定义多层神经网络的层数和神经元数量,可以通过设置 hidden_units 数组来实现。
2.2 pytorch
#GMF层
class GMF(nn.Module):def __init__(self,embedding_dim):super(GMF, self).__init__()self.embedding_dim = embedding_dimself.fc = nn.Linear(self.embedding_dim,self.embedding_dim)def forward(self, user_emb, item_emb):out = self.fc(user_emb*item_emb).sigmoid()return out#MLP
class MLP_Layer(nn.Module):def __init__(self,input_dim,output_dim=None,hidden_units=[],hidden_activations="ReLU",final_activation=None,dropout_rates=0,batch_norm=False,use_bias=True):super(MLP_Layer, self).__init__()dense_layers = []if not isinstance(dropout_rates, list):dropout_rates = [dropout_rates] * len(hidden_units)if not isinstance(hidden_activations, list):hidden_activations = [hidden_activations] * len(hidden_units)hidden_activations = [set_activation(x) for x in hidden_activations]hidden_units = [input_dim] + hidden_unitsfor idx in range(len(hidden_units) - 1):dense_layers.append(nn.Linear(hidden_units[idx], hidden_units[idx + 1], bias=use_bias))if batch_norm:dense_layers.append(nn.BatchNorm1d(hidden_units[idx + 1]))if hidden_activations[idx]:dense_layers.append(hidden_activations[idx])if dropout_rates[idx] > 0:dense_layers.append(nn.Dropout(p=dropout_rates[idx]))if output_dim is not None:dense_layers.append(nn.Linear(hidden_units[-1], output_dim, bias=use_bias))if final_activation is not None:dense_layers.append(set_activation(final_activation))self.dnn = nn.Sequential(*dense_layers) # * used to unpack listdef forward(self, inputs):return self.dnn(inputs)def set_device(gpu=-1):if gpu >= 0 and torch.cuda.is_available():os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)device = torch.device(f"cuda:{gpu}")else:device = torch.device("cpu")return devicedef set_activation(activation):if isinstance(activation, str):if activation.lower() == "relu":return nn.ReLU()elif activation.lower() == "sigmoid":return nn.Sigmoid()elif activation.lower() == "tanh":return nn.Tanh()else:return getattr(nn, activation)()else:return activationdef get_dnn_input_dim(enc_dict,embedding_dim):num_sparse = 0num_dense = 0for col in enc_dict.keys():if 'min' in enc_dict[col].keys():num_dense+=1elif 'vocab_size' in enc_dict[col].keys():num_sparse+=1return num_sparse*embedding_dim+num_densedef get_linear_input(enc_dict,data):res_data = []for col in enc_dict.keys():if 'min' in enc_dict[col].keys():res_data.append(data[col])res_data = torch.stack(res_data,axis=1)return res_data
# NCF 模型
class NCF(nn.Module):def __init__(self,embedding_dim1=16, # GMF 对应的Embedding层embedding_dim2=32, # MLP 对应的Embedding层hidden_units=[64, 32, 16],loss_fun = 'torch.nn.BCELoss()',enc_dict=None):super(NCF, self).__init__()self.embedding_dim1 = embedding_dim1 # GMF Embself.embedding_dim2 = embedding_dim2 # MLP Embself.hidden_units = hidden_unitsself.loss_fun = eval(loss_fun)self.enc_dict = enc_dict# GMFself.user_emb_layer1 = nn.Embedding(self.enc_dict['user_id']['vocab_size'],self.embedding_dim1)self.item_emb_layer1 = nn.Embedding(self.enc_dict['item_id']['vocab_size'],self.embedding_dim1)# MLPself.user_emb_layer2 = nn.Embedding(self.enc_dict['user_id']['vocab_size'],self.embedding_dim2)self.item_emb_layer2 = nn.Embedding(self.enc_dict['item_id']['vocab_size'],self.embedding_dim2)self.gmf = GMF(self.embedding_dim1)self.mlp = MLP_Layer(input_dim=self.embedding_dim2*2, hidden_units=self.hidden_units,hidden_activations='relu', dropout_rates=0)# GMF:[batch,Emb1] MLP:[batch,hidden_units[-1]]-> FC的输入维度:self.embedding_dim1 + self.hidden_units[-1]self.fc = nn.Linear(self.embedding_dim1 + self.hidden_units[-1],1)def forward(self, data):# GMFuser_emb1 = self.user_emb_layer1(data['user_id'])item_emb1 = self.item_emb_layer1(data['item_id'])# MLPuser_emb2 = self.user_emb_layer2(data['user_id'])item_emb2 = self.item_emb_layer2(data['item_id'])# GMFgmf_out = self.gmf(user_emb1, item_emb1)# MLPmlp_input = torch.cat([user_emb2,item_emb2],axis=-1)mlp_out = self.mlp(mlp_input)#输出final_input = torch.cat([gmf_out,mlp_out],axis=-1)y_pred = self.fc(final_input).sigmoid()loss = self.loss_fun(y_pred.squeeze(-1),data['label'])output_dict = {'pred':y_pred,'loss':loss}return output_dict