ElasticSearch的Deep Paging 性能问题和解决方案

一、深度分页问题
ES默认采用的分页方式是from + size的形式,类似于MySQL的分页limit。当请求数据量比较大时,ElasticSearch会对分页做出限制,因为此时消耗会很大。举个例子,一个索引分10个shards,然后一个搜索请求,from = 990,size = 10,这个时候,会带来严重的性能问题:CPU、内存、IO、网络带宽。
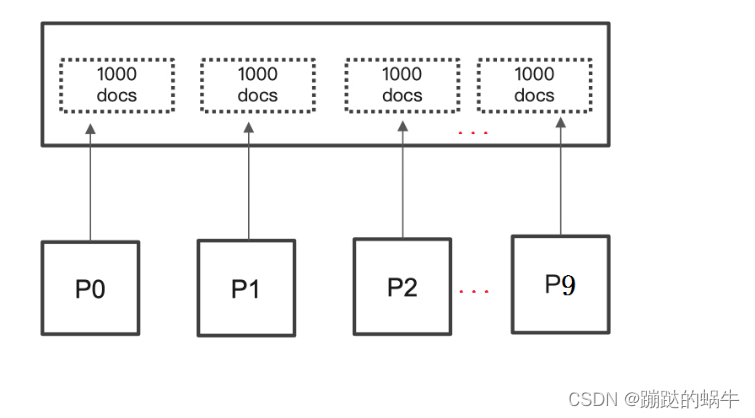
CPU、内存和IO消耗很容易理解,网络带宽问题稍微难理解一点。在query阶段,每个shard需要返回1000条数据给coordinating node,而coordinating node需要接收10 * 1000条数据,即使每条数据只有_doc_id和score,这个数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
ES有个设置index.max_result_window,默认是10000条数据,如果分页的数据超过了1万条,就拒绝返回结果了。有时这种深度分页的请求并不合理,因为很少有人看后面的请求,在很多业务场景中,都直接限制分页,比如只能看前100页。不过这种深度分页确实存在,比如有1千万分时的微信大V,要给所有粉丝群发消息,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用from + size来实现,但是这就会引发深度分页的问题,这就用到了接下来提到的解决方案。
二、深度分页解决方案
2.1 利用scroll遍历方式
scroll分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。因此scroll并不适合用来实时搜索,而更适合用于后台批量处理任务,比如群发。
1、初始化
POST /book/_search?scroll=1m&size=2
{"query": { "match_all": {}}
}
初始化时需要像普通search一样,指明index和type(当然,search是可以不指明index和type的),然后,加上scroll参数,表示暂存搜索结果的时间,其他就像一个普通的search请求一样。初始化返回一个scroll_id,scroll_id用来下次取数据用。
2、遍历
GET /_search/scroll
{"scroll": "1m","scroll_id" : "步骤1中查询出来的值"
}
这里scroll_id即上一次遍历取回的_scroll_id或者初始化返回的_scroll_id,同样的,需要带scroll参数。重复这一步骤,知道返回的数据为空,即遍历完成。注意,每次都要传参数scroll,刷新搜索结果的缓存时间。另外,不需要指定index和type。设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长。毕竟空间有限。
2.2 search after方式
满足实时获取下一页的文档信息,search _after分页的方式是根据上一页的最后一条数据来确定下一页的文职,同时在分页请求的过程中,如果索引数据的增删改,这些变更也会实时地反映到游标上,这种方式是在es-5.x后才提供的。为了找到每一页最后一条数据,每个文档的排序字段必须有一个全局唯一值,一般使用_id就可以了。
GET /book/_search
{"query":{"match_all": {}},"size":2,"sort":[{"_id": "desc"}]
}GET /book/_search
{"query":{"match_all": {}},"size":2,"search_after":[3],"sort":[{"_id": "desc"}]
}
下一页依赖上一页的最后一条的信息,所以不能跳页。
2.3 三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反映数据的实时性(快照版本) 维护成本高,需要维护一个 scroll_id | 海量数据的导出 需要查询海量结果集的数据 |
| search_after | 高 | 性能最好 | 不存在深度分页问题 能够反映数据的实时变更 | 实现连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 海量数据的分页 |