论文解读:PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model

发表时间:2022
论文地址:https://arxiv.org/abs/2204.02681
项目地址:https://github.com/PaddlePaddle/PaddleSeg

PP-LiteSeg,一个新的轻量级实时语义分割任务模型,在分割精度和推理速度之间实现了一种最先进的权衡。重点设计了一种新的实时语义分割网络。首先,提出了柔性和轻量级解码器(FLD),以提高以往解码器的效率。然后,我们提出了一个统一的注意融合模块(UAFM),它是有效的加强特征表示。此外,我们提出了一个简单的金字塔池模块(SPPM),以较低的计算成本聚合全局上下文。广泛的评估表明,与其他方法相比,PP-LiteSeg在精度和速度之间取得了优越的权衡。在Cityscapes测试集上,PP-LiteSeg在NVIDIA GTX 1080Ti上分别达到了72.0%的mIoU/273.6 FPS和77.5%的mIoU/102.6 FPS
基本总结
1、本文的核心其实就是提出了一种应用在解码器上基于attention的多尺度间特征的融合方式(UAFM,与Attention to Scale论文和 MULTI-SCALE ATTENTION 论文核心思想很像),但其attention map是针对整个尺度,而不是单个像素位。其所使用的backbone为paddle团队提出的STDC2
2、基于所提出的多尺度特征间融合方式UAFM,并指出解码器中存在计算冗余(高分辨率下chanel大,增加了解码压力)设计了一种轻量化的解码器头FLD
3、提出了一个简单的金字塔池模块(SPPM),其只针对编码器输出的最深层特征进行金字塔池化操作
4、模型是进行了深度监督的(对多个尺度下的特征图都单独添加seg_head训练loss),但在论文中没有提到
1、相关背景
1.1 现有轻量级模型
ENet [23]采用早期降采样策略来降低处理大型图像和特征图的计算成本。为了提高效率,
ICNet [28]设计了一个多分辨率的图像级联网络。[26]基于双边分割网络,分别提取细节特征和语义特征。双边网络是轻量级的,所以推理速度很快。
STDCSeg [8]提出了通道减少的接受域放大的STDC模块,并设计了一个有效的主干,可以以较低的计算成本加强特征表示。为了消除双分支网络中的冗余性,STDCSeg以详细的地面真实度来指导特征,从而进一步提高了效率;
Espnetv2 [21]使用组点级和深度级扩展的可分离卷积,以一种计算友好的方式从扩大的接受域中学习特征;
BiSeNetV2 [26]提出了双边分割网络,并分别提取了细节特征和语义特征。
1.2 PPLiteSeg轻量化方案
PPLiteSeg采用了编解码器架构,由三个新的模块组成:灵活和轻量级解码器(FLD)、统一注意融合模块(UAFM)和简单金字塔池模块(SPPM)。

这些模块的动机和细节介绍如下:
灵活的轻量级解码器 语义分割中编码器用于提取层次特征(对于编码器中从低层次到高层次的特征,通道数量增加,空间尺寸减小),解码器融合和上采样特征(对于解码器中从高到低的特征,空间大小增加,而最近的模型[8,15]的信道数量相同)。因此,我们提出了一个灵活的轻量级解码器(FLD),它逐渐减少feature map channel,增加了feature map size,减轻了解码器的冗余性,并平衡编码器和解码器的计算成本。灵活的设计平衡了编码器和解码器的计算复杂度,使整个模型更加高效。
加强特征表示 是提高分割精度的关键途径。它通常是通过在解码器中融合低级和高级特性来实现的。然而,现有方法中的融合模块通常计算成本较高。在这项工作中,我们提出了统一注意融合模块(UAFM),利用通道和空间注意来加强特征表示。如图4所示,UAFM首先利用注意模块产生权重α,然后将输入特征与α融合。在UAFM中,有两种注意模块,即空间注意模块和通道注意模块,它们利用了输入特征的空间间和通道间关系。 其本质就是提出来一个尺度attention,计算出尺度系数α来对不同层级的特征进行融合

上下文聚合 是提高分割精度的另一个关键,但以前的聚合模块对于实时网络来说很耗时。基于PPM [29]的框架,我们设计了一个简单的金字塔池模块(SPPM),它减少了中间通道和输出通道,消除了short-cut,并用一个add操作替换了concat操作,SPPM通过少量的推理时间提高分割精度。
我们通过在Cityscapes和CamVid数据集上的广泛实验来评估所提出的PP-LiteSeg。如图1所示,PP-LiteSeg在分割精度和推理速度之间实现了一个优越的权衡。具体来说,PP-LiteSeg在Cityscapes测试集上达到了72.0%的mIoU和273.6的FPS和77.5%的mIoU火热102.6的FPS。
2、方法实现
首先分别介绍了灵活轻量级解码器(Flexible and Lightweight Decoder,FLD)、统一注意融合模块( Unified Attention Fusion Module,UAFM)和简单金字塔池模块(Simple Pyramid Pooling Module,SPPM)。然后,我们提出了用于实时语义分割的PP-LiteSeg的体系结构。
基本实现代码如下,完整代码地址:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.7/paddleseg/models/pp_liteseg.py
代码中的PPLiteSegHead对应着论文中的解码器,SegHead为分类头,这里是可以看出模型是进行深度监督的(对多个尺度下的特征图进行训练loss)
class SegHead(nn.Layer):def __init__(self, in_chan, mid_chan, n_classes):super().__init__()self.conv = layers.ConvBNReLU(in_chan,mid_chan,kernel_size=3,stride=1,padding=1,bias_attr=False)self.conv_out = nn.Conv2D(mid_chan, n_classes, kernel_size=1, bias_attr=False)def forward(self, x):x = self.conv(x)x = self.conv_out(x)return x
@manager.MODELS.add_component
class PPLiteSeg(nn.Layer):def __init__(self,num_classes,backbone,backbone_indices=[2, 3, 4],arm_type='UAFM_SpAtten',cm_bin_sizes=[1, 2, 4],cm_out_ch=128,arm_out_chs=[64, 96, 128],seg_head_inter_chs=[64, 64, 64],resize_mode='bilinear',pretrained=None):super().__init__()self.backbone_indices = backbone_indices # [..., x16_id, x32_id]backbone_out_chs = [backbone.feat_channels[i] for i in backbone_indices]# headif len(arm_out_chs) == 1:arm_out_chs = arm_out_chs * len(backbone_indices)assert len(arm_out_chs) == len(backbone_indices), "The length of " \\"arm_out_chs and backbone_indices should be equal"self.ppseg_head = PPLiteSegHead(backbone_out_chs, arm_out_chs,cm_bin_sizes, cm_out_ch, arm_type,resize_mode)if len(seg_head_inter_chs) == 1:seg_head_inter_chs = seg_head_inter_chs * len(backbone_indices)self.seg_heads = nn.LayerList() # [..., head_16, head32]for in_ch, mid_ch in zip(arm_out_chs, seg_head_inter_chs):self.seg_heads.append(SegHead(in_ch, mid_ch, num_classes))# pretrainedself.pretrained = pretrainedself.init_weight()def forward(self, x):x_hw = paddle.shape(x)[2:]feats_backbone = self.backbone(x) # [x2, x4, x8, x16, x32]assert len(feats_backbone) >= len(self.backbone_indices), \\f"The nums of backbone feats ({len(feats_backbone)}) should be greater or " \\f"equal than the nums of backbone_indices ({len(self.backbone_indices)})"feats_selected = [feats_backbone[i] for i in self.backbone_indices]feats_head = self.ppseg_head(feats_selected) # [..., x8, x16, x32]if self.training:logit_list = []for x, seg_head in zip(feats_head, self.seg_heads):x = seg_head(x)logit_list.append(x)logit_list = [F.interpolate(x, x_hw, mode='bilinear', align_corners=False)for x in logit_list]else:x = self.seg_heads[0](feats_head[0])x = F.interpolate(x, x_hw, mode='bilinear', align_corners=False)logit_list = [x]return logit_listdef init_weight(self):if self.pretrained is not None:utils.load_entire_model(self, self.pretrained)2.1 Flexible and Lightweight Decoder
编解码器架构已被证明是有效的语义分割。一般来说,编码器利用一系列分成几个阶段的层来提取层次特征。对于从低层次到高层次的特征,通道的数量逐渐增加,特征的空间尺寸逐渐减小。该设计平衡了各阶段的计算成本,保证了编码器的效率。虽然特征的空间大小从高层特征到低层逐步编写,但其他的轻量级模型中的解码器在所有级别上保持特征通道相同,使浅阶段的计算成本远远大于深阶段的计算成本(浅层特征图空间大),这导致了浅阶段的计算冗余。
为了提高解码器的效率,我们提出了一种灵活的轻量级解码器(FLD)。如图3所示,FLD逐渐减少了来自底层特征的通道,其可以很容易地调整计算成本,以实现编码器和解码器之间更好的平衡。虽然FLD中的特征通道正在减少,但我们的实验表明,PP-LiteSeg与其他方法相比,具有竞争力的精度。

基本实现代码如下,其中的PPContextModule对应着SPPM模块,其中的arm即为UAFM模块
class PPLiteSegHead(nn.Layer):"""The head of PPLiteSeg.Args:backbone_out_chs (List(Tensor)): The channels of output tensors in the backbone.arm_out_chs (List(int)): The out channels of each arm module.cm_bin_sizes (List(int)): The bin size of context module.cm_out_ch (int): The output channel of the last context module.arm_type (str): The type of attention refinement module.resize_mode (str): The resize mode for the upsampling operation in decoder."""def __init__(self, backbone_out_chs, arm_out_chs, cm_bin_sizes, cm_out_ch,arm_type, resize_mode):super().__init__()self.cm = PPContextModule(backbone_out_chs[-1], cm_out_ch, cm_out_ch,cm_bin_sizes)assert hasattr(layers,arm_type), \\"Not support arm_type ({})".format(arm_type)arm_class = eval("layers." + arm_type)self.arm_list = nn.LayerList() # [..., arm8, arm16, arm32]for i in range(len(backbone_out_chs)):low_chs = backbone_out_chs[i]high_ch = cm_out_ch if i == len(backbone_out_chs) - 1 else arm_out_chs[i + 1]out_ch = arm_out_chs[i]arm = arm_class(low_chs, high_ch, out_ch, ksize=3, resize_mode=resize_mode)self.arm_list.append(arm)def forward(self, in_feat_list):"""Args:in_feat_list (List(Tensor)): Such as [x2, x4, x8, x16, x32].x2, x4 and x8 are optional.Returns:out_feat_list (List(Tensor)): Such as [x2, x4, x8, x16, x32].x2, x4 and x8 are optional.The length of in_feat_list and out_feat_list are the same."""high_feat = self.cm(in_feat_list[-1])out_feat_list = []for i in reversed(range(len(in_feat_list))):low_feat = in_feat_list[i]arm = self.arm_list[i]high_feat = arm(low_feat, high_feat)out_feat_list.insert(0, high_feat)return out_feat_list
2.2. Unified Attention Fusion Module
如上所述,融合多层次特征是实现高分割精度的必要条件。除了元素级的sum和concat外,研究人员还提出了几种方法,如SFNet [15]、FaPN [11]和AttaNet [25]。在这项工作中,我们提出了一个统一的注意融合模块(UAFM),它应用通道和空间注意来丰富融合的特征表示。

UAFM Framework. 如图4 (a)所示,UAFM利用一个注意模块来产生权重α,并通过Mul和Add操作将输入特性与α相融合。详细地说,输入特征被表示为FhighF_{high}Fhigh和FlowF_{low}Flow。FhighF_{high}Fhigh是深层模块的输出,而FlowF_{low}Flow是编码器的对应模块。请注意,它们有相同的通道。UAFM首先利用双线性插值操作将FhighF_{high}Fhigh上采样到相同的流大小,而上采样特征记为FupF_{up}Fup。然后,注意模块以FupF_{up}Fup和F_{low}作为输入,产生权重α。请注意,注意模块可以是一个插件,如空间注意模块、通道注意模块等。然后,为了获得注意加权特征,我们分别将元素级Mul操作应用于FupF_{up}Fup和F_{low}。最后,UAFM对注意加权特征进行元素加法,并输出融合特征。我们可以把上述过程表述为公式1。


具体实现代码如下,对应UAFM_SpAtten类,如论文中描述不同的是,对于high feature的融合权重不是固定为1-a,这里的1是一个可训练参数。
#实现基于resize后add的low、high特征融合方式
class UAFM(nn.Layer):def __init__(self, x_ch, y_ch, out_ch, ksize=3, resize_mode='bilinear'):super().__init__()self.conv_x = layers.ConvBNReLU(x_ch, y_ch, kernel_size=ksize, padding=ksize // 2, bias_attr=False)self.conv_out = layers.ConvBNReLU(y_ch, out_ch, kernel_size=3, padding=1, bias_attr=False)self.resize_mode = resize_modedef check(self, x, y):assert x.ndim == 4 and y.ndim == 4x_h, x_w = x.shape[2:]y_h, y_w = y.shape[2:]assert x_h >= y_h and x_w >= y_wdef prepare(self, x, y):x = self.prepare_x(x, y)y = self.prepare_y(x, y)return x, ydef prepare_x(self, x, y):x = self.conv_x(x)return xdef prepare_y(self, x, y):y_up = F.interpolate(y, paddle.shape(x)[2:], mode=self.resize_mode)return y_updef fuse(self, x, y):out = x + yout = self.conv_out(out)return outdef forward(self, x, y):"""Args:x (Tensor): The low level feature.y (Tensor): The high level feature."""self.check(x, y)x, y = self.prepare(x, y)out = self.fuse(x, y)return out
class UAFM_SpAtten(UAFM):"""The UAFM with spatial attention, which uses mean and max values.Args:x_ch (int): The channel of x tensor, which is the low level feature.y_ch (int): The channel of y tensor, which is the high level feature.out_ch (int): The channel of output tensor.ksize (int, optional): The kernel size of the conv for x tensor. Default: 3.resize_mode (str, optional): The resize model in unsampling y tensor. Default: bilinear."""def __init__(self, x_ch, y_ch, out_ch, ksize=3, resize_mode='bilinear'):super().__init__(x_ch, y_ch, out_ch, ksize, resize_mode)self.conv_xy_atten = nn.Sequential(layers.ConvBNReLU(4, 2, kernel_size=3, padding=1, bias_attr=False),layers.ConvBN(2, 1, kernel_size=3, padding=1, bias_attr=False))self._scale = self.create_parameter(shape=[1],attr=ParamAttr(initializer=Constant(value=1.)),dtype="float32")self._scale.stop_gradient = Truedef fuse(self, x, y):"""Args:x (Tensor): The low level feature.y (Tensor): The high level feature."""atten = helper.avg_max_reduce_channel([x, y])atten = F.sigmoid(self.conv_xy_atten(atten))out = x * atten + y * (self._scale - atten)out = self.conv_out(out)return out
Spatial Attention Module. 空间注意模块的动机是利用空间间关系来产生一个权重,该权重表示输入特征中每个像素的重要性。如图4 (b)所示,给定输入特征,即Fup∈RC×H×WF_{up}∈R^{C×H×W}Fup∈RC×H×W和Flow∈RC×H×WF_{low}∈R^{C×H×W}Flow∈RC×H×W,我们首先沿着通道轴进行平均和最大操作,生成四个特征,其中维度为R1×H×WR^{1×H×W}R1×H×W。然后,将这四个特征连接到一个特征Fcat∈R4×H×WF_{cat}∈R^{4×H×W}Fcat∈R4×H×W上。对于连接的特征,将卷积和s型运算应用于输出α∈R1×H×Wα∈R^{1×H×W}α∈R1×H×W。空间注意模块的公式如式2所示。此外,空间注意模块还可以灵活地实现,例如去除最大操作以降低计算成本


所对应的实现代码为,对应上文代码中的helper.avg_max_reduce_channel与F.sigmoid(self.conv_xy_atten(atten)),在channel维度取最大值和平均值然后融合
self.conv_xy_atten = nn.Sequential(layers.ConvBNReLU(4, 2, kernel_size=3, padding=1, bias_attr=False),layers.ConvBN(2, 1, kernel_size=3, padding=1, bias_attr=False))def avg_max_reduce_channel_helper(x, use_concat=True):# Reduce hw by avg and max, only support single inputassert not isinstance(x, (list, tuple))mean_value = paddle.mean(x, axis=1, keepdim=True)max_value = paddle.max(x, axis=1, keepdim=True)if use_concat:res = paddle.concat([mean_value, max_value], axis=1)else:res = [mean_value, max_value]return resdef avg_max_reduce_channel(x):# Reduce hw by avg and max# Return cat([avg_ch_0, max_ch_0, avg_ch_1, max_ch_1, ...])if not isinstance(x, (list, tuple)):return avg_max_reduce_channel_helper(x)elif len(x) == 1:return avg_max_reduce_channel_helper(x[0])else:res = []for xi in x:res.extend(avg_max_reduce_channel_helper(xi, False))return paddle.concat(res, axis=1)Channel Attention Module. 通道注意模块的关键概念是利用通道间的关系来产生一个权重,这表明了每个通道在输入特征中的重要性。如图4 (b)所示,所提出的信道注意模块利用平均池化和最大池化操作来压缩输入特征的空间维数。此过程使用维度RC×1×1R^{C×1×1}RC×1×1生成四个特性。然后,它将这四个特征沿着通道轴连接起来,并执行卷积和s型运算,以产生一个权重α∈RC×1×1。简而言之,通道注意模块的过程可以表述为公式3。

并未从官方源码中找到对应实现代码
2.3. Simple Pyramid Pooling Module
如图5所示,我们提出了一个简单的金字塔池模块(SPPM)。它首先利用金字塔池化模块来融合输入特性。金字塔池模块有三个全局平均池操作,pool大小分别为1×1、2×2和4×4。然后,在输出特征之后,再进行卷积和上采样操作。对于卷积操作,核大小为1×1,输出通道小于输入通道。最后,我们添加了这些上采样的特征,并应用卷积运算来产生细化的特征。与原始的PPM相比,SPPM减少了中间通道和输出通道,删除了捷径,并用附加操作替换了连接操作。因此,SPPM更有效,也更适合用于实时模型。

其具体实现代码如下所示,其输入是一个feature map,输出也是一个feature map。只针对编码器输出的最深层特征进行金字塔池化。
class PPContextModule(nn.Layer):"""Simple Context module.Args:in_channels (int): The number of input channels to pyramid pooling module.inter_channels (int): The number of inter channels to pyramid pooling module.out_channels (int): The number of output channels after pyramid pooling module.bin_sizes (tuple, optional): The out size of pooled feature maps. Default: (1, 3).align_corners (bool): An argument of F.interpolate. It should be set to Falsewhen the output size of feature is even, e.g. 1024x512, otherwise it is True, e.g. 769x769."""def __init__(self,in_channels,inter_channels,out_channels,bin_sizes,align_corners=False):super().__init__()self.stages = nn.LayerList([self._make_stage(in_channels, inter_channels, size)for size in bin_sizes])self.conv_out = layers.ConvBNReLU(in_channels=inter_channels,out_channels=out_channels,kernel_size=3,padding=1)self.align_corners = align_cornersdef _make_stage(self, in_channels, out_channels, size):prior = nn.AdaptiveAvgPool2D(output_size=size)conv = layers.ConvBNReLU(in_channels=in_channels, out_channels=out_channels, kernel_size=1)return nn.Sequential(prior, conv)def forward(self, input):out = Noneinput_shape = paddle.shape(input)[2:]for stage in self.stages:x = stage(input)x = F.interpolate(x,input_shape,mode='bilinear',align_corners=self.align_corners)if out is None:out = xelse:out += xout = self.conv_out(out)return out2.4. Network Architecture
所提议的PP-LiteSeg的体系结构如图2所示。PP-LiteSeg主要由三个模块组成:编码器、聚合器和解码器。

首先,给定一个输入图像,PP-Lite利用一个通用的轻量级网络作为编码器来提取层次特征。详细地说,我们选择STDCNet [8]是因为其出色的性能。STDCNet有5个阶段,每个阶段的步幅为2,所以最终的特征大小是输入图像的1/32。如表1所示,我们提供了两个版本的PP-LiteSeg,即PP-LiteSeg-T和PP-LiteSeg-B,其中的编码器分别为STDC1和STDC2。PPLiteSeg-B具有较高的分割精度,而PP-LiteSeg-T的推理速度更快。值得注意的是,我们将SSLD [7]方法应用于编码器的训练,得到了增强的预训练权值,有利于分割训练的收敛。
| Model | Encoder Channels in Decoder |
|---|---|
| PP-LiteSeg-T | STDC1 32, 64, 128 |
| PP-LiteSeg-B | STDC2 64, 96, 128 |
| 其次,PP-LiteSeg采用SPPM对随机依赖进行建模。SPPM以编码器的输出特性作为输入,生成一个包含全局上下文信息的特性。 |
最后,PP-LiteSeg利用我们提出的FLD逐步融合多层次特征并输出得到的图像。具体来说,FLD由两个UAFM和一个分割头组成。为了提高效率,我们在UAFM中采用了空间注意模块。每个UAFM以两个特征作为输入,即由编码器的各个阶段提取的一个低级特征,由SPPM或更深层的融合模块生成的高级特征。后者的UAFM输出融合的特征,降样本比为1/8。在分割头部中,我们执行Conv-BN-Relu操作,将1/8个下样本特征的信道减少到类的数量。采用上采样操作将特征大小扩展到输入图像大小,并采用argmax操作预测每个像素的标签。采用在线硬样本挖掘的交叉熵损失方法对模型进行了优化。
3、实验
首先将介绍数据集和实现细节。然后,我们将实验结果在准确性和推理速度方面与其他最先进的实时方法进行了比较。最后,我们通过消融研究证明了所提出的模块的有效性。
3.1 数据集和实施细节
数据集
Cityscapes。Cityscapes[6]是一个用于城市分割的大规模数据集。它包含5000张精细注释的图像,分别被进一步分成2975,500和1525张图像,分别进行训练、验证和测试。图像的分辨率为2048×1024,这给实时语义分割方法带来了巨大的挑战。注释的图像有30个类,我们的实验只使用19个类与其他方法进行公平的比较。
CamVid。剑桥驾驶标记视频数据库(CamVid)[2]是一个用于道路场景分割的小型数据集。共有701张具有高质量像素级标注的图像,其中分别选择了367张、101张和233张图像进行训练、验证和测试。这些图像的分辨率同样为960×720。标注的图像提供了32个类别,其中11个类别的子集被用于我们的实验。
训练测试
根据一般的设置,选择0.9动量的随机梯度下降(SGD)算法作为优化器。我们还采用了热身策略和“多聚”学习速率调度器。
对于Cityscapes,批处理大小为16,最大迭代次数为160,000,初始学习率为0.005,优化器中的权重衰减为5e−4。
对于CamVid,批处理大小为24,最大迭代次数为1000,初始学习速率为0.01,权值衰减为1e−4。
数据扩充
使用随机缩放,随机裁剪,随机水平翻转,随机的颜色抖动和标准化。Cityscapes和Camvid的随机量表范围分别为[0.125、1.5]、[0.5、2.5]。Cityscapes的裁剪分辨率为1024×512,CamVid的裁剪分辨率为960×720。
推理设置
为了进行公平的比较,我们将PPLiteSeg导出到ONNX中,并利用TensorRT来执行模型。与其他方法[8,26]类似,首先将Cityscapes的图像调整到1024×512和1536×768,然后推理模型将缩放图像生成预测图像,最后将预测图像调整到输入图像的原始大小。这三个步骤的成本被计算为推理时间。对于CamVid,推理模型以原始图像为输入,分辨率为960×720。我们在NVIDIA 1080Ti GPU上进行了CUDA 10.2,CUDNN 7.6,TensorRT 7.1.3下的所有推理实验。我们采用标准的mIoU进行分割精度比较,并采用FPS进行推理速度比较
3.2 Cityscapes效果
通过上面提到的训练和推理设置,我们将所提出的PP-LiteSeg与之前最先进的Cityscapes实时模型进行了比较。为了进行公平的比较,我们对PP-LiteSeg-T和PP-LiteSeg-B在两种分辨率下进行了评估,即512×1024和768×1536。表2介绍了各种方法的模型信息、输入分辨率、mIoU和FPS。

图1提供了分割精度和推理速度的直观比较。实验结果表明,所提出的PP-LiteSeg方法在精度和速度之间实现了最先进的权衡。具体来说,我们可以观察到PP-LiteSeg-T1达到273.6 FPS和72.0%的mIoU,这意味着最快的推理速度和竞争精度。PPLiteSeg-B2的分辨率为768×1536,即验证集78.2% mIoU,测试集77.5% mIoU。此外,使用与STDC-Seg相同的编码器和输入分辨率,PPLiteSeg显示出更好的性能。

通过消融实验,验证了所提模块的有效性。实验在比较中选择PP-LiteSeg-B2,并使用相同的训练和推理设置。基线模型为无该模块的PP-LiteSeg-B2,而解码器中的特征通道数为96个,融合方法为元素级求和。表3显示了我们的消融研究的定量结果。我们可以发现,PP-LiteSeg-B2中的FLD使mIoU提高了0.17%。添加SPPM和UAFM也提高了分割精度,而推理速度略有降低。基于三个提出的模块,PP-LiteSeg-B2以102.6 FPS达到78.21 mIoU。mIoU与基线模型相比提高了0.71%。图6提供了定性的比较。我们可以观察到,当逐个添加FLD、SPPM和UAFM时,预测的图像更符合地面真相。总之,我们提出的模块对于语义分割是有效的。
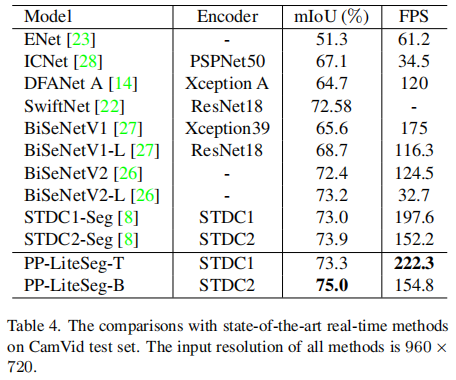
3.3 CamVid效果
为了进一步证明PP-LiteSeg的能力,我们还在CamVid数据集上进行了实验。与其他工作类似,训练和推理的输入分辨率是960×720。如表4所示,PP-LiteSeg-T达到222.3 FPS,比其他方法快12.5%以上。PP-LiteSeg-B的精度最高,即154.8 FPS情况下下mIoU达到了75.0%。总的来说,比较显示PP-LiteSeg在Camvid上实现了精度和速度之间的最先进的权衡。