基于集成学习的用户流失预测并利用shap进行特征解释

基于集成学习的用户流失预测并利用shap进行特征解释
小P:小H,如果我只想尽可能的提高准确率,有什么好的办法吗?
小H:优化数据、调参侠、集成学习都可以啊
小P:什么是集成学习啊,听起来就很厉害的样子
小H:集成学习就类似于【三个臭皮匠顶个诸葛亮】,将一些基础模型组合起来使用,以期得到更好的结果
集成学习实战
数据准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import warnings
warnings.filterwarnings('ignore')from scipy import stats
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV, KFold
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, VotingClassifier, ExtraTreesClassifier
import xgboost as xgb
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, \\precision_score, recall_score, roc_curve # 导入指标库
import prettytable
import sweetviz as sv # 自动eda
import toad
from sklearn.model_selection import StratifiedKFold, cross_val_score # 导入交叉检验算法# 绘图初始化
%matplotlib inline
pd.set_option('display.max_columns', None) # 显示所有列
sns.set(style="ticks")
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 导入自定义模块
import sys
sys.path.append("/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册")
from keyIndicatorMapping import *
上述自定义模块
keyIndicatorMapping如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-自定义函数】自动获取~
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-集成学习】自动获取~
# 读取数据
raw_data = pd.read_csv('classification.csv')
raw_data.head()

# 缺失值填充,SMOTE方法限制非空
raw_data=raw_data.fillna(raw_data.mean())
# 数据集分割
X = raw_data[raw_data.columns.drop('churn')]
y = raw_data['churn']
# 标准化
scaler = StandardScaler()
scale_data = scaler.fit_transform(X)
X = pd.DataFrame(scale_data, columns = X.columns)
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=0)
# 过采样
model_smote = SMOTE(random_state=0) # 建立SMOTE模型对象
X_train, y_train = model_smote.fit_resample(X_train, y_train)
模型对比
%%time
# 初选分类模型
model_names = ['LR', 'SVC', 'RFC', 'XGBC'] # 不同模型的名称列表
model_lr = LogisticRegression(random_state=10) # 建立逻辑回归对象
model_svc = SVC(random_state=0, probability=True) # 建立支持向量机分类对象
model_rfc = RandomForestClassifier(random_state=10) # 建立随机森林分类对象
model_xgbc = xgb.XGBClassifier(use_label_encoder=False, eval_metric='auc', random_state=10) # 建立XGBC对象# 模型拟合结果
model_list = [model_lr, model_svc, model_rfc, model_xgbc] # 不同分类模型对象的集合
pre_y_list = [model.fit(X_train, y_train).predict(X_test) for model in model_list] # 各个回归模型预测的y值列表
CPU times: user 2.49 s, sys: 125 ms, total: 2.62 s
Wall time: 843 ms
# 核心评估指标
metrics_dic = {'model_names':[],'auc':[],'ks':[],'accuracy':[],'precision':[],'recall':[],'f1':[]}
for model_name, model, pre_y in zip(model_names, model_list, pre_y_list):y_prob = model.predict_proba(X_test) # 获得决策树的预测概率,返回各标签(即0,1)的概率fpr, tpr, thres = roc_curve(y_test, y_prob[:, 1]) # ROC y_score[:, 1]取标签为1的概率,这样画出来的roc曲线为正metrics_dic['model_names'].append(model_name)metrics_dic['auc'].append(auc(fpr, tpr)) # AUCmetrics_dic['ks'].append(max(tpr - fpr)) # KS值metrics_dic['accuracy'].append(accuracy_score(y_test, pre_y))metrics_dic['precision'].append(precision_score(y_test, pre_y))metrics_dic['recall'].append(recall_score(y_test, pre_y))metrics_dic['f1'].append(f1_score(y_test, pre_y))
pd.DataFrame(metrics_dic)

集成学习
%%time
# 建立组合评估器列表 均衡稳定性和准确性 这里只是演示,就将所有模型都纳入了
estimators = [('SVC', model_svc), ('RFC', model_rfc), ('XGBC', model_xgbc), ('LR', model_lr)]
model_vot = VotingClassifier(estimators=estimators, voting='soft', weights=[1.1, 1.1, 0.9, 1.2],n_jobs=-1) # 建立组合评估模型
cv = StratifiedKFold(5) # 设置交叉检验方法 分类算法常用交叉检验方法
cv_score = cross_val_score(model_vot, X_train, y_train, cv=cv, scoring='accuracy') # 交叉检验
print('{:*^60}'.format('Cross val scores:'),'\\n',cv_score) # 打印每次交叉检验得分
print('Mean scores is: %.2f' % cv_score.mean()) # 打印平均交叉检验得分
*Cross val scores: [0.73529412 0.7745098 0.85294118 0.85294118 0.87745098]
Mean scores is: 0.82
CPU times: user 2.38 s, sys: 432 ms, total: 2.81 s
Wall time: 5 s
# 模型训练
model_vot.fit(X_train, y_train) # 模型训练
VotingClassifier(estimators=[('SVC', SVC(probability=True, random_state=0)),('RFC', RandomForestClassifier(random_state=10)),('XGBC',XGBClassifier(base_score=0.5, booster='gbtree',colsample_bylevel=1,colsample_bynode=1,colsample_bytree=1,eval_metric='rmse', gamma=0,gpu_id=-1, importance_type='gain',interaction_constraints='',learning_rate=0.300000012,max...min_child_weight=1, missing=nan,monotone_constraints='()',n_estimators=100, n_jobs=8,num_parallel_tree=1,random_state=10, reg_alpha=0,reg_lambda=1, scale_pos_weight=1,subsample=1, tree_method='exact',use_label_encoder=False,validate_parameters=1,verbosity=None)),('LR', LogisticRegression(random_state=10))],n_jobs=-1, voting='soft', weights=[1.1, 1.1, 0.9, 1.2])
model_confusion_metrics(model_vot, X_test, y_test, 'test')
model_core_metrics(model_vot, X_test, y_test, 'test')
confusion matrix for test+----------+--------------+--------------+
| | prediction-0 | prediction-1 |
+----------+--------------+--------------+
| actual-0 | 53 | 31 |
| actual-1 | 37 | 179 |
+----------+--------------+--------------+
core metrics for test+-------+----------+-----------+--------+-------+-------+
| auc | accuracy | precision | recall | f1 | ks |
+-------+----------+-----------+--------+-------+-------+
| 0.805 | 0.773 | 0.589 | 0.631 | 0.609 | 0.504 |
+-------+----------+-----------+--------+-------+-------+
可以看到集成学习的各项指标表现均优异,只有召回率低于LR
利用shap进行模型解释
shap作为一种经典的事后解释框架,可以对每一个样本中的每一个特征变量,计算出其重要性值,达到解释的效果。该值在shap中被专门称为Shapley Value。
该系列以应用为主,对于具体的理论只会简单的介绍它的用途和使用场景。这里的shap相关知识 可以参考黑盒模型事后归因解析:SHAP方法、SHAP知识点全汇总
学无止境,且学且珍惜~
# pip install shap
import shap
# 初始化
shap.initjs()
# 通过采样提高计算效率,但会导致准确率降低。表现在base_value与mean(model.predict_proba(X))存在差异,不建议K太小
# X_test_summary = shap.sample(X_test, 200)
# X_test_summary = shap.kmeans(X_test, 150)
explainer = shap.KernelExplainer(model_vot.predict_proba, X_test)
shap_values = explainer.shap_values(X_test, nsamples = 10)
Using 300 background data samples could cause slower run times. Consider using shap.sample(data, K) or shap.kmeans(data, K) to summarize the background as K samples.
- 单样本查看
# 单样本查看-1概率较高的样本 # 208
shap.force_plot(base_value=explainer.expected_value[1],shap_values=shap_values[1][208],features = X_test.iloc[208,:])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AxXaXK0k-1679902455430)(null)]
base_value:所有样本预测值的均值,即
base_value=model_vot.predict_proba(X_test)[:,1].mean()⚠️注意:当进行采样或者kmean加速计算时,会损失一定准确度。即explainer带入的是X_test_summary
f(x):预测的实际值
model_vot.predict_proba(X_test)[:,1]data:样本特征值
shap_values:f(x)-base_value;shap值越大越红,越小越蓝
# 验证base_value print('所有样本预测标签1的概率均值:',model_vot.predict_proba(X_test)[:,1].mean()) print('base_value:',explainer.expected_value[1])所有样本预测标签1的概率均值: 0.3519852365700774 base_value: 0.35198523657007774经验证,base_value计算逻辑正确
# 验证单一样本 i=208 fx=model_vot.predict_proba(X_test)[:,1][i] da=X_test.iloc[i,:] sv=fx-explainer.expected_value[1] sv_val=shap_values[1][i].sum() print('f(x):',fx) print('shap_values:',sv,sv_val)f(x): 0.9264517406651224 shap_values: 0.5744665040950446 0.5744665040950446经验证,shap_values计算逻辑正确
- 特征重要性
# 特征重要程度
shap.summary_plot(shap_values[1],X_test,max_display=10,plot_type="bar")

- 蜂窝图体现特征重要性
# 特征与样本蜂窝图
shap.summary_plot(shap_values[1],X_test,max_display=10)

retention_days越大,蓝色的样本越多,表明较高的retention_days有助于缓减流失
- 特征的shap值
# 单特征预测结果
shap.dependence_plot("retention_days", shap_values[1], X_test, interaction_index=None)

retention_days低的shape值较大,上面讲到shap越大越红,对于y起到提高作用。即retention_days与流失负相关
# 双特征交叉影响
shap.dependence_plot("retention_days", shap_values[1], X_test, interaction_index='level')
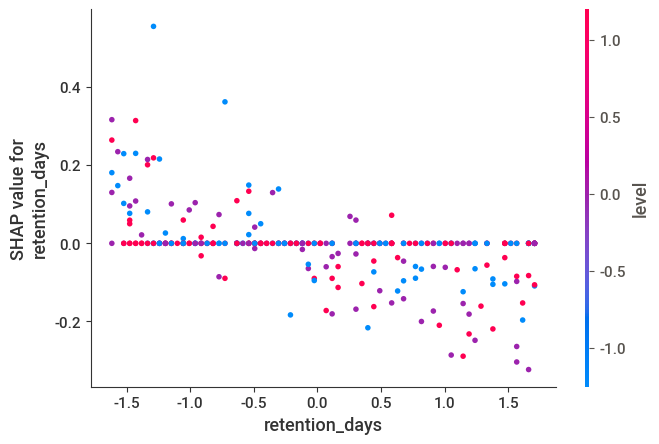
- 在较低的retention_days(如-1.5),高level(level=1.0)的shepae值较高(红色点),在0.2附近
- 在较高的retention_days(如1.5),高level(level=1.0)的shepae值较低(红色点),在-0.2附近
总结
集成学习能有效地提高模型的预测性能,但是使得模型内部结构更为复杂,无法直观理解。好在可以借助shap进行常见的特征重要性解释等。
共勉~