MySQL基础篇

基础概念
为什么要用数据库?
应用程序产生的数据是在内存中,如果程序退出或者断电,数据则会消失,使用数据库是为了永久保存数据
为什么不直接使用普通文件?
把数据写在硬盘文件中,当然可以实现持久化的目标,但是不利于后期的检索和管理
Mysql,Oracle,SqlServer是什么?
都是数据库管理系统,是一种操纵和管理数据库的大型软件
SQL是什么?
SQL是结构化查询语言,专门用来操作/访问数据库的语言
目录介绍
mysql的数据文件位置
/var/lib/mysql/
mysql配置文件
/etc/my.cnf
Mysql数据类型
整形:
一字节整形:tinyint
二字节整形:smallint
三字节整形:mediumint
四字节整形:int
对于整形,Mysql支持类型后加(M),M表示显示宽度。int(M)这个M,只有在字段的属性
中指定了unsigned(无符号)和 zerofill(零填充)才有意义
浮点数:
float
double
M为位数,D表示小数位数
decimal(M,D) 默认decimal(10,0)
浮点类型具有误差,浮点类型推荐使用decimal类型(保存为字符串格式)
字符串类型
char(M) M表示字符个数而不是字节个数,M为0~255
varchar(M) M表示字符个数,总字节数<=65535,需要增加1或2个字节存储数据的字节数
blob 0~65535字节,值所占字节数 +2
text 0~65535字节,值所占字节数 +2
对于myisam存储引擎,推荐使用固定长度的数据列代替可变长度的数据列。使整个表静态化,从而使数据检索更快,用空间换时间
对于innodb存储引擎,推荐使用可变长度的数据列,因为innodb数据表的存储格式不分固定长度和可变长度,使用char不一定比使用varchar好,但varchar是按实际的长度存储的,比较节省空间,所以对磁盘IO和数据存储总量比较好
日期时间类型
year 1字节 YYYY 取值:1901-2155
date 3字节 YYYY-MM-DD 取值:1000-01-01至9999-12-31
time 3字节 HH:MM:SS 取值: -838:59:59至838:59:59
datetime 8字节 YYYY-MM-DD HH:MM:SS 取值: 9999-12-31 23:59:59
timestamp 4字节 YYYY-MM-DD HH:MM:SS 取值: 2038-01-19 03:14:07
timestamp类型的日期时间值存储时会将当前时区的日期时间值转换为标准时间值,检索时再转换回当前时区的日期时间值
datetime只能反映出插入时当地的时区,其他时区的人查看数据必然存在误差
enum类型,只能在指定的枚举列表中取值,而且一次只能取一个。枚举列表最多有65535个成员。enum值在内部用整数表示,每个枚举值都有一个索引值,mysql存储的就是索引编号
值 索引
NULL NULL
'' 0
'fisrt' 1
'second' 2
'third' 3
set类型,可以从定义的值列表中选择1个或多个值的组合。set列最多有64个成员。set值在内部用整数表示,分别是1,2,4,8都是2的n次方值,这些整数值对应的二进制位都是只有1位是1,其余是0
集合成员 二进制值 十进制值
'地铁' 0001 1
'公交' 0010 2
'步行' 0100 4
'出租车' 1000 8
mysql运算符
算术运算符
+:求和,不支持字符串拼接
-:
*:
/: div(只保留整数部分) /:数学中的除
%: mod
mysql 没有 += 运算符
比较运算符
:>
:<
:>=
:<=
:= 不能用于null判断
: != 或 <> 不能用于null 判断
区间或集合范围比较运算符
区间范围:between x and y 或 not between x and y
集合范围:in(x,x,x) not in(x,x,x)
模糊匹配比较运算符
%:代表任意字符
_: 代表一个字符,如果两个下划线代表两个字符
select * from t_employeee where ename like '%冰%'
逻辑运算符
&& 或 and
|| 或 or
! 或 not
关于null值
xx is null
xx is not null
xx <=> null
ifnull(xx,代替值) 当xx是null时,用代替值计算
Mysql系统预定义函数
Mysql数据库管理软件提供好的函数,任何数据库都可以用的公共函数
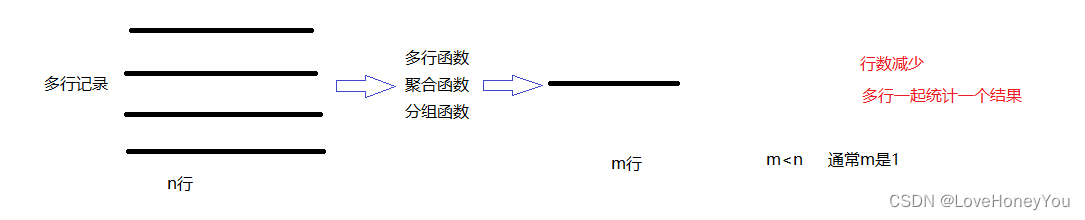
分组函数(聚合函数):表示会对表中多行记录一起做一个"运算",得到一个结果
求平均值 avg(x),求最大值 max(x),求最小值 min(x) 求总和 sum(x) 求个数 count(x)
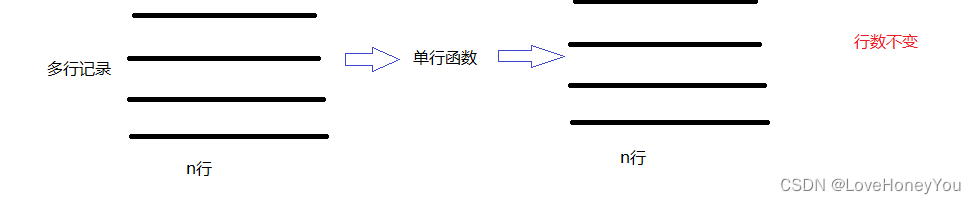
单行函数:表示会对表中的每一行记录分别计算,有n行就有n行结果
数学函数,字符串函数,日期时间函数,条件判断函数,窗口函数
关系型数据库范式
应用数据库范式带来的好处:
1)减少数据冗余
2)消除异常
3)让数据组织更协调
第一范式:每一列保持原子性
列都是基本数据项,不能够在进行分割
第二范式:属性完全依赖于主键-主要针对联合主键
只依赖于联合主键的其中一个字段,不符合第二范式
第三范式:属性不依赖于其他非主属性
要求一个数据库表中不包含已在其他表中包含的非主关键字信息
范式越高,表越多,带来的问题
1.查询时,需要连接多个表,增加SQL查询的复杂度
2.查询时,需要连接多个表,降低了数据库查询性能
3.第三范式已经很大程度上的减少了数据冗余,并且基本预防了数据插入异常,更新异常,和删除异常
SQL语句
DDL:数据定义语句,创建,删除,修改
DML:增,删,改,查
DCL:数据控制语句:grant,commit,rollback
SQL语法规范
1)mysql中的sql语法不区分大小写
2)建议不要使用nysql的关键字来做为表名,字段名,数据库名,不小心使用,加' '引起来
标点符号
():在创建表,添加数据,函数使用,子查询,计算表达式,等等会用()表示某个部分是一个整体结构
' ':字符串和日期类型的数据值使用单引号,数值类型的不须要加标点符号
" ":列的别名可以使用双引号,给表取别名不能使用双引号
DDL
与数据库相关
create database 数据库名; //创建
show databases; //查看
//查看详细定义
show create database 数据库名;
show create database 数据库名\\G
//修改数据库编码
alter database 数据库名 character set 字符集名称 collate 字符集校对规则;
alter database LHY character set utf8 collate utf8_general_ci;
修改数据库编码,只会影响之后创建表的默认编码,之前创建的表不受影响
//删除数据库
drop database 数据库名;
//使用数据库
use 数据库名;
与数据表相关
create table 数据表名(字段名 数据类型,字段名 数据类型); //创建
//查看表的定义信息
show create table 表名;
show create table 表名\\G
//查看表结构
desc 表名;
//删除表格,包括表结构和字段
drop table 表名;
//修改表,删除表的字段
alter table 表名 drop 字段名称;
//修改表,增加字段
alter table 表名 add 字段名称 数据类型 约束;//添加到末尾
alter table 表名 add 字段名称 数据类型 约束 first;//添加到开头
alter table 表名 add 字段名称 数据类型 约束 after 字段名;//添加到某个字段后
//修改表,修改字段的数据类型
alter table 表名称 modify 字段名称 新的数据类型 约束;
//修改表,修改字段名称
alter table 表名称 change 旧字段名称 新字段名称 新的数据类型;
//修改表结构,修改字段位置
alter table 表名称 modify 字段名称 数据类型 first;
alter table 表名称 modify 字段名称 数据类型 after 另一个字段;
//修改表名称
rename table 旧表名称 to 新表名称;
DML
//添加
insert into 表名称 values(值列表);//值列表中的值顺序,类型,个数与表结构对应
insert into 表名称 values(值列表),(值列表),(值列表);
insert into 表名称(字段列表) values(值列表),(值列表),(值列表);
//修改
update 表名称 set 字段名 = 值,字段名 = 值; //给所有行修改
update 表名称 set 字段名 = 值 where 条件; //给满足条件的行修改
//删除
delete from 表名称; //删除整张表,但表结构保留
truncate 表名称; //截断表,清空表中数据,只有表结构
二者区别:delete是一条一条删除,支持回滚
truncate是把整张表drop,新建一张,效率高,无法回滚
DQL
select 字段名1 as "别名1",字段2 as "别名" from 表名称 as 别名;
//as可以省略,表的别名不能加双引号
//查询结果去重
select distinct 字段列表 from 表名称 【where 条件】;
//