顺序栈和非循环队列来咯!!!

前言:
通过上几篇文章,我们一直在学习我们的线性表,我们学习了我们的顺序表,链表等相关线性表,那么我们今天来学习一下栈和队列这两种线性表叭!
当然我们今天只介绍我们的顺序栈和非循环的队列。
可能有小伙伴想问了:为什么不介绍链栈,共享栈,循环队列呢?
原因很简单啊~我不会!当然,过几天应该会学会,过几天的事过几天再说。
马上就进入我们的顺序栈和非循环队列当中吧
知识框架:
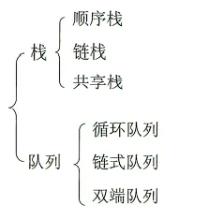
我们今天只讲我们的顺序栈和链式队列。
栈:
栈的基本概念:
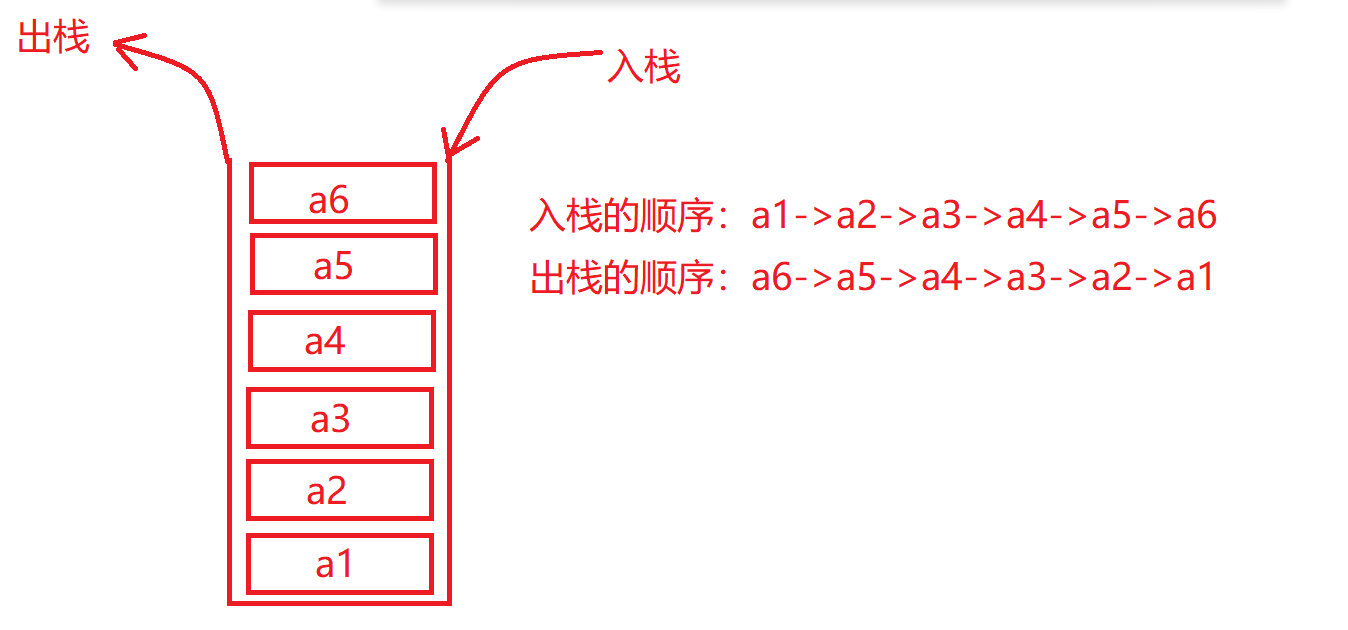
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
总结上面这段话:先进后出,后进先出
再来看下图:
栈的基本操作:
1.栈的初始化
2.栈的销毁
3.元素入栈
4.元素出栈
5.栈已有的元素个数
6.栈是否为空
7.读栈顶的元素
那么我们现在来实现他们叭!
当然实现他们之前,我们先用代码实现栈的结构:
顺序栈的结构:
定义一个数组进行存放数据,再定义StackSize的变量来记录当前数组的最大容量,最后定义一个记录栈顶所在位置的变量
//栈的结构体数据
typedef int Stackdata;struct Stack
{Stackdata* data;//存放栈数据的数组Stackdata StackSize;//记录目前数组的最大容量Stackdata top;//记录栈顶
};
typedef struct Stack Stack;注意:可能有同学很想问:为什么我们不定义top为指针呢?
原因:
顺序栈的top变量通常不定义为指针,是因为顺序栈是基于数组实现的,数组的元素在内存中是连续存储的,因此可以通过数组下标来访问元素,而不需要使用指针来进行地址计算。
顺序栈的top变量表示栈顶元素在数组中的下标位置,通过top变量可以方便地获取栈顶元素的值,同时也可以方便地插入和删除元素。如果将top定义为指针,则需要进行指针的地址计算,增加了额外的复杂度和开销,同时也容易出现指针越界等问题,不如直接使用数组下标来操作元素方便和安全。
因此,通常情况下,顺序栈的top变量会定义为一个整型变量,用于记录栈顶元素在数组中的下标位置。
-
栈的初始化:
我们用于存放数据的数组还是个空的,那么我们从堆区开辟空间,让我们的数组能够存放数据,我喜欢一开始把大小开为2,具体多大,大家按需求和喜好来开辟,之后让栈的结构体的记录最大容量的变量变为2,让我们的top设为0,当然我们可以设为-1
void StackInit(Stack* ps)
{ps->data = (Stackdata*)malloc(sizeof(Stackdata) * 2);if (ps->data == NULL){perror("malloc fail");return;}ps->StackSize = 2;ps->top = 0;
}-
栈的销毁:
由于我们的栈是通过数组进行存储数据,我们只需要把数组free了就行,当然还需要将StackSize和top赋值为0,并将数组的指针赋值为空指针
void StackDestroy(Stack* ps)
{assert(ps);free(ps->data);ps->StackSize = 0;ps->top = 0;ps->data = NULL;
}-
元素入栈:
每次让元素入栈之前都需要判断以下栈是否已经满了,如果满了我们就需要进行扩容操作,我一般会扩容为原大小的2倍,扩容多少全看各位的喜好,之后我们将元素入栈,并让top自增1,改变栈顶
void StackPush(Stack* ps,Stackdata val)
{assert(ps);if (ps->top == ps->StackSize)//栈满了!!!{Stackdata* tmp = (Stackdata*)realloc(ps->data, sizeof(Stackdata) * ps->StackSize * 2);if (tmp == NULL){perror("realloc fail");return;}ps->data = tmp;ps->StackSize = ps->StackSize * 2;}ps->data[ps->top] = val;++(ps->top);
}-
元素出栈:
每次让元素出栈,我们都要检查栈的数组是否为空,如果是空的,我们就无法从栈中拿出元素。
如果我们从栈中提取出了元素,我们就需要改变栈顶的位置,即让top自减1
void StackPop(Stack* ps)
{assert(ps);assert(!isEmpty);--(ps->top);
}-
栈已有的元素个数:
这个就很简单了,因为我们存放数据的容器是一个数组,那么我们数组元素的个数就是top的值,这也是为什么我们的top变量不设为指针变量的其中原因
int StackSize(Stack* ps)
{assert(ps);return ps->top;
}-
栈是否为空:
因为我们的top一开始是0,只要top = 0,这个栈就是空的
bool isEmpty(Stack* ps)
{assert(ps);return (ps->top) == 0;
}-
读栈顶的元素:
读栈顶的元素,还是需要判断栈是否为空,top所在的位置是我们的栈顶,那么栈顶的前一位就是栈顶的元素
Stackdata ReadTop(Stack* ps)
{assert(ps);assert(!isEmpty);return (ps->data[(ps->top)-1]);
}顺序栈的实现的完整代码:
//栈的初始化
void StackInit(Stack* ps)
{ps->data = (Stackdata*)malloc(sizeof(Stackdata) * 2);if (ps->data == NULL){perror("malloc fail");return;}ps->StackSize = 2;ps->top = 0;
}//栈的销毁
void StackDestroy(Stack* ps)
{assert(ps);free(ps->data);ps->StackSize = 0;ps->top = 0;ps->data = NULL;
}//元素入栈
void StackPush(Stack* ps,Stackdata val)
{assert(ps);if (ps->top == ps->StackSize)//栈满了!!!{Stackdata* tmp = (Stackdata*)realloc(ps->data, sizeof(Stackdata) * ps->StackSize * 2);if (tmp == NULL){perror("realloc fail");return;}ps->data = tmp;ps->StackSize = ps->StackSize * 2;}ps->data[ps->top] = val;++(ps->top);
}
//元素出栈
void StackPop(Stack* ps)
{assert(ps);assert(!isEmpty);--(ps->top);
}
//栈已有的元素个数
int StackSize(Stack* ps)
{assert(ps);return ps->top;
}
//栈是否为空
bool isEmpty(Stack* ps)
{assert(ps);return (ps->top) == 0;
}
//读栈顶的元素
Stackdata ReadTop(Stack* ps)
{assert(ps);assert(!isEmpty);return (ps->data[(ps->top)-1]);
}队列:
队列的基本概念:
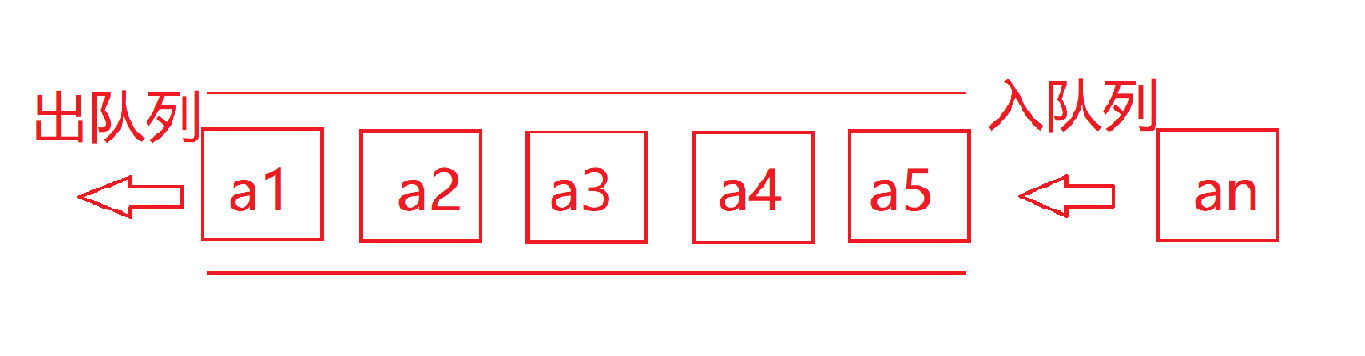
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
总结:队列是先进先出,后进后出
再来看下图:
队列的基本操作:
1.队列的初始化
2.数据入队列
3.数据出队列
4.获取队列的有效数据个数
5.判断队列是否为空
6.获取队列头部的数据
7.获取队列尾部的数据
8.销毁队列
老样子,先来看非循环队列的结构:
非循环队列的结构:
typedef int QueueData;struct QueueNode
{struct QueueNode* next;QueueData data;
};typedef struct QueueNode QueueNode;struct Queue
{QueueNode* head;QueueNode* tail;int size;
};
typedef struct Queue Queue;很多同学发现了,我们的Queue这个结构体存放了两个指针,这两个指针在其实是分别指向我们的队头和队尾,因为我们的队头和队尾只需要分别出数据和入数据,所以只需要两个指针就可以很好的解决,那么我们也不需要用循环的双向链表了。
这两个指针应该还是很好理解的,但是为什么这个结构体还有一个size呢?
等看到该队列的基本操作代码出来之后你就会明白这个size的大用处。
-
队列的初始化
这个应该没什么好说的,一开始我们的队列其实是没有任何数据的,那么我们就让head和tail两个指针指向空指针,size赋值为0
void QueueInit(Queue* Q)
{assert(Q);Q->head = Q->tail = NULL;Q->size = 0;
}-
数据入队列
malloc一个队列的结点,如果新的结点为空,返回,新结点的数据应该赋值为我们传入的val,next指针应该传为空指针,如果一开始我们的队列是空的,我们的指向头尾的两个指针都是指向空的,我们要让这两个指针同时指向这个新的指针,如果这个队列不是空的,那就让我们的插入之前的队列的最后一个结点指向我们的新结点,再让尾指针指向这个新结点,最后让我们的size自增1
void QueuePush(Queue* Q, QueueData val)
{assert(Q);QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));if (newnode == NULL){perror("malloc fail");return;}newnode->data = val;newnode->next = NULL;//如果队列一开始是空的,也就是我们的尾指针是空的if (Q->tail == NULL){assert(Q->head == NULL);Q->head = Q->tail = newnode;}else//如果队列不是空的{Q->tail->next = newnode;Q->tail = newnode;}//存入数据之后我们的size也要自增哦++(Q->size);
}-
数据出队列
在Pop一个元素之前,首先还是先要判断这个队列是否为空,当然出队列有两种情况,第一种就是队列中还存在一个元素,这只需要free头指针就行,并让头尾指针同时指向空,如果不止一个元素,我们需要找到第二个元素的位置,让一个新的指针指向它,之后free头指针,之后把新指针的值赋给我们的头指针,这样让我们原本的第二个元素顺利变成队头的元素。当然,千万别忘了size自减1
void QueuePop(Queue* Q)
{assert(Q);assert(Q->head != NULL);//整个队列还剩头的一个元素if (Q->head->next == NULL){free(Q->head);Q->head = Q->tail = NULL;}//整个队列不止一个元素else{QueueNode* next = Q->head->next;//用一个新的指针指向head的后一个结点free(Q->head);Q->head = next;//头指针到了我们的第二个结点上,第二个结点也顺利成为队列的第一个数据}--(Q->size);//少不了我们队列大小的计算
}-
获取队列的有效数据个数
size的用处来咯,因为我们之前每次增删元素都会修改size,那么size就是我们的有效数据的个数。
int QueueSize(Queue* Q)
{assert(Q);return Q->size;//我都说了,这个size有大用!!!
}-
判断队列是否为空
还是size的用处,只需要判断size是否为0即可
bool isEmpty(Queue* Q)
{assert(Q);return (Q->size) == 0;
}-
获取队列头部的数据
还是需要判断队列是否为空,之后返回头指针指向的结点的数据即可
QueueData QueueFront(Queue* Q)
{assert(Q);//一定要判断这个队列是否是空的assert(!isEmpty(Q));return Q->head->data;
}-
获取队列尾部的数据
QueueData QueueBack(Queue* Q)
{//思路如上assert(Q);assert(!isEmpty(Q));return Q->tail->data;
}-
销毁队列
这个没什么好说的,因为队列里面是一个单链表嘛,我们只需要遍历一遍依次free即可
void QueueDestroy(Queue* Q)
{assert(Q);QueueNode* cur = Q->head;while (cur){QueueNode* next = cur->next;free(cur);cur = next;}Q->size = 0;Q->head = Q->tail = NULL;
}非循环队列的实现的完整代码:
//队列的初始化
void QueueInit(Queue* Q)
{assert(Q);Q->head = Q->tail = NULL;Q->size = 0;
}
//数据入队列
void QueuePush(Queue* Q, QueueData val)
{assert(Q);QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));if (newnode == NULL){perror("malloc fail");return;}newnode->data = val;newnode->next = NULL;//如果队列一开始是空的,也就是我们的尾指针是空的if (Q->tail == NULL){assert(Q->head == NULL);Q->head = Q->tail = newnode;}else//如果队列不是空的{Q->tail->next = newnode;Q->tail = newnode;}//存入数据之后我们的size也要自增哦++(Q->size);
}
//数据出队列
void QueuePop(Queue* Q)
{assert(Q);assert(Q->head != NULL);//整个队列还剩头的一个元素if (Q->head->next == NULL){free(Q->head);Q->head = Q->tail = NULL;}//整个队列不止一个元素else{QueueNode* next = Q->head->next;//用一个新的指针指向head的后一个结点free(Q->head);Q->head = next;//头指针到了我们的第二个结点上,第二个结点也顺利成为队列的第一个数据}--(Q->size);//少不了我们队列大小的计算
}
//获取队列的有效数据个数
int QueueSize(Queue* Q)
{assert(Q);return Q->size;//我都说了,这个size有大用!!!
}
//判断队列是否为空
bool isEmpty(Queue* Q)
{assert(Q);return (Q->size) == 0;
}
//获取队列头部的数据
QueueData QueueFront(Queue* Q)
{assert(Q);//一定要判断这个队列是否是空的assert(!isEmpty(Q));return Q->head->data;
}
//获取队列尾部的数据
QueueData QueueBack(Queue* Q)
{//思路如上assert(Q);assert(!isEmpty(Q));return Q->tail->data;
}
//销毁队列
void QueueDestroy(Queue* Q)
{assert(Q);QueueNode* cur = Q->head;while (cur){QueueNode* next = cur->next;free(cur);cur = next;}Q->size = 0;Q->head = Q->tail = NULL;
}