Python程序员看见一个好看的手机壁纸网站,开撸!

人生苦短,我用python
最近好像没什么大事,
.那就采集一下小——姐——姐————看下吧~
python 安装包+资料:点击此处跳转文末名片获取

最近有同学的爬虫代码出了bug,给问我怎么改
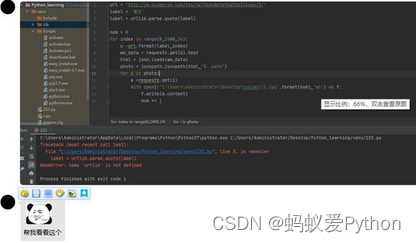
于是就发现了这个好看的手机壁纸网站。

这个图片应该是违规的,放不出来的
看到那么多好看的壁纸,
我的pycharm已经饥渴难耐了(不是)
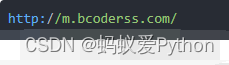
受害网址
python 安装包+资料:点击此处跳转文末名片获取
为了良性爬取,
这个代码就不完整的展示出来了
部分爬虫代码
导入工具
from urllib import parse
import requests
import parsel
import re
解析网站,爬取数据
for page in range(1, 10):print('正在爬取第{}页壁纸'.format(page))url = 'http://# /tag/{}/page/{}/'.format(name, page)headers = {'Cookie': 'UM_distinctid=1747c5616688f-0da459aa281e74-3962420d-1fa400-1747c56166982d; CNZZDATA1278590218=744878758-1599811024-%7C1599811024','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}response = requests.get(url=url, headers=headers)selector = parsel.Selector(response.text)img_url = selector.css('#main a::attr(href)').getall()
设置爬取类目
string = input('请输入你要爬取的类目:')
name = parse.unquote(string)
保存图片
path = 'C:\\\\Users\\\\Administrator\\\\Desktop\\\\手机壁纸\\\\' + new_title + '.jpg'with open(path, mode='wb') as f:f.write(data_response.content)print(title)
运行代码,效果如下图
python 安装包+资料:点击此处跳转文末名片获取
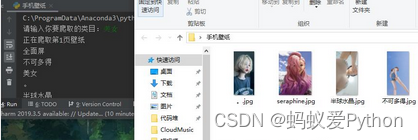
最后放两张好看的图片~
咳咳…今天的文章就是这样啦!
我绝对没有在水!!!


👇问题解答 · 源码获取 · 技术交流 · 抱团学习请联系👇